# Galaxy Data Development and Management Platform
**Shanghai — 2025-10-27**
The **Galaxy Data Development and Management Platform** is designed for data production teams, providing:
- **Offline & real-time** data collection and synchronization
- **Development & operations** tooling
- **Processing & production** pipelines
- **Data asset management** frameworks
- **Security & compliance** controls
It addresses core business demands for **data architecture**, **data quality**, and **delivery efficiency**, enabling **long-term scalability**.


---
## 📚 Table of Contents
### **I. Background Introduction**
### **II. Product Function Architecture**
### **III. The “Cockpit” of Data Development — Data Development Suite**
1. System Architecture Analysis
2. Data Synchronization Technology Analysis
3. Task Migration Plan
4. Function Development & Migration Progress
### **IV. The “Chassis” of Company Data Assets — Data Architecture Technology**
1. Onedata Methodology & Tool System
2. Unified ODS Data Ingestion Scheme
3. Standardized Data Modeling & Metrics Automation
4. Progress & Results
### **V. The “Brake Pad” of Data Production — Data Quality Technology**
1. Galaxy Data Quality Tools
2. Progress & Results
### **VI. The “Driver Assistance” in Data Development — Intelligent Data Development**
1. Galaxy’s Intelligent Roadmap
2. Intelligent SQL Code Completion
3. Progress & Results
### **VII. Future Plans**
1. Intelligent ETL Agent
2. Data Fabric Architecture
3. Data Logicalization
---
## I. Background Introduction
**Why build our own big data platform?**
As a data-driven internet company, Dewu’s competitiveness depends heavily on **efficiency**, **quality**, and **cost** in data utilization.
In the **data value chain**:
- **Computing/storage engines** affect **cost**
- **Data development platforms** determine **delivery speed**, **data quality**, and **architectural soundness**
**Current challenges** with cloud-based commercial products prompted the **2024 launch of Galaxy** as a proprietary platform.
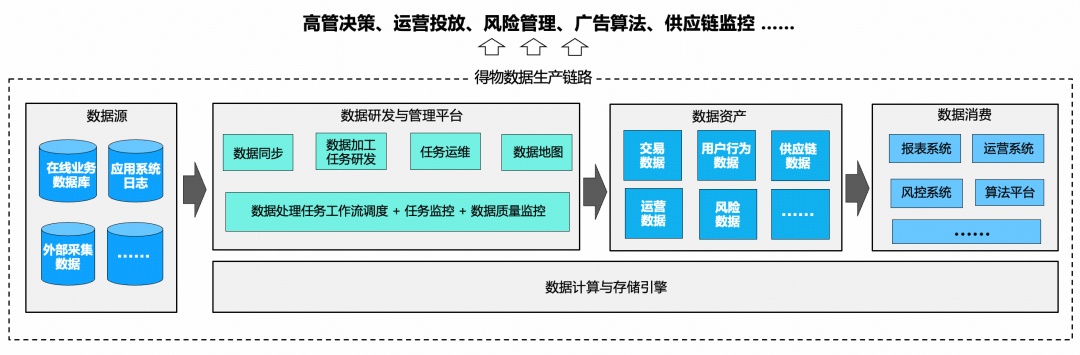
Galaxy delivers capabilities across **offline/real-time sync**, **development & ops**, **asset management**, and **security compliance** for sustainable data growth.
---
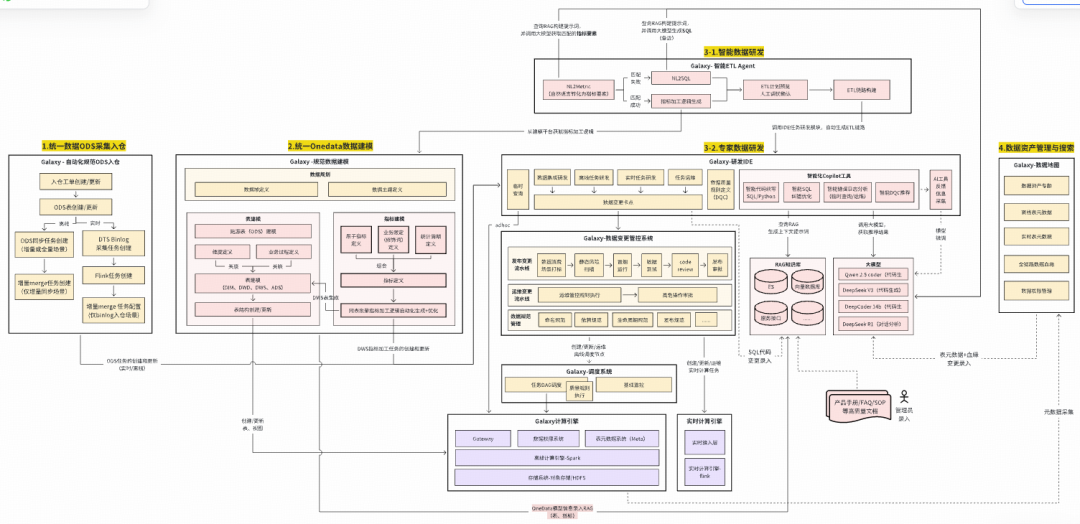
## II. Product Function Architecture
The Galaxy architecture visualizes:
- **Blue sections**: implemented features
- **Grey sections**: planned
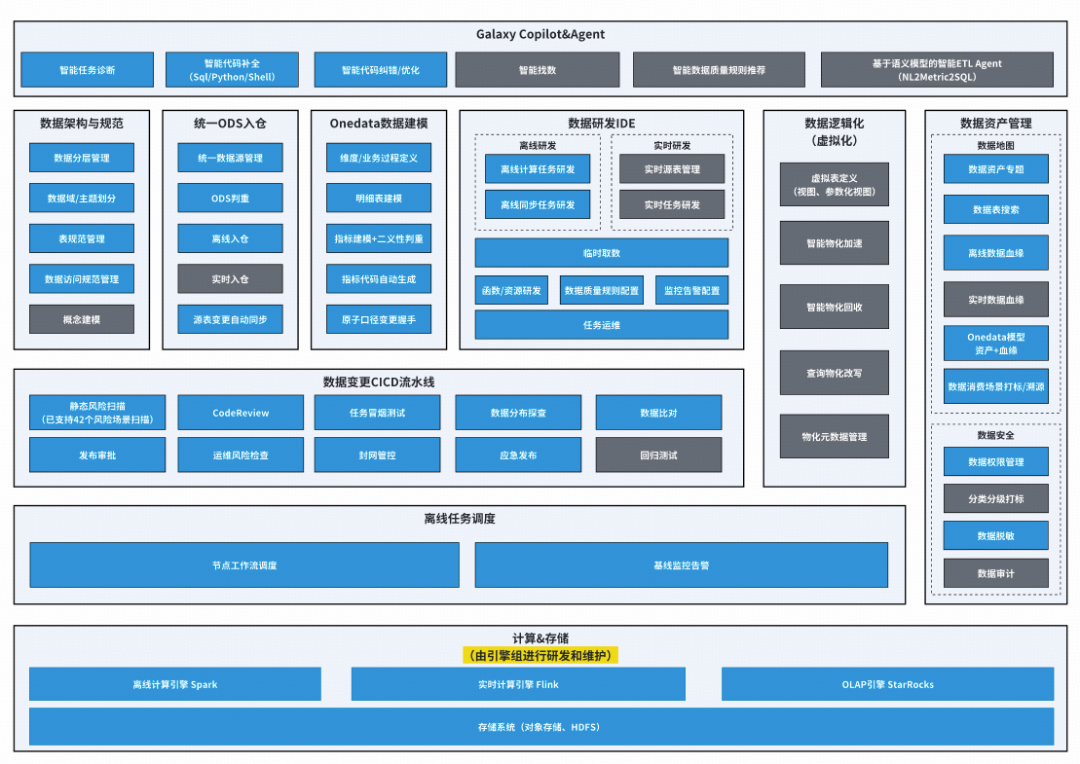
**4 core components**:
1. **Data Development Suite**
2. **Data Architecture Technology**
3. **Data Quality Technology**
4. **Intelligent Data Development**
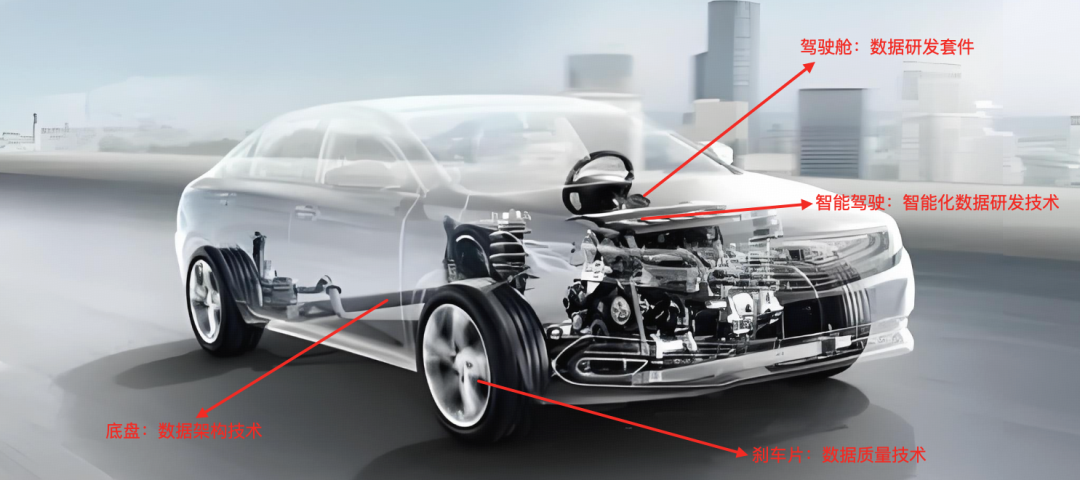
### Car Analogy:
- **Cockpit** = Data Development Suite
- **Chassis** = Data Architecture
- **Brake Pads** = Data Quality
- **Driver Assistance** = Intelligent Development
---
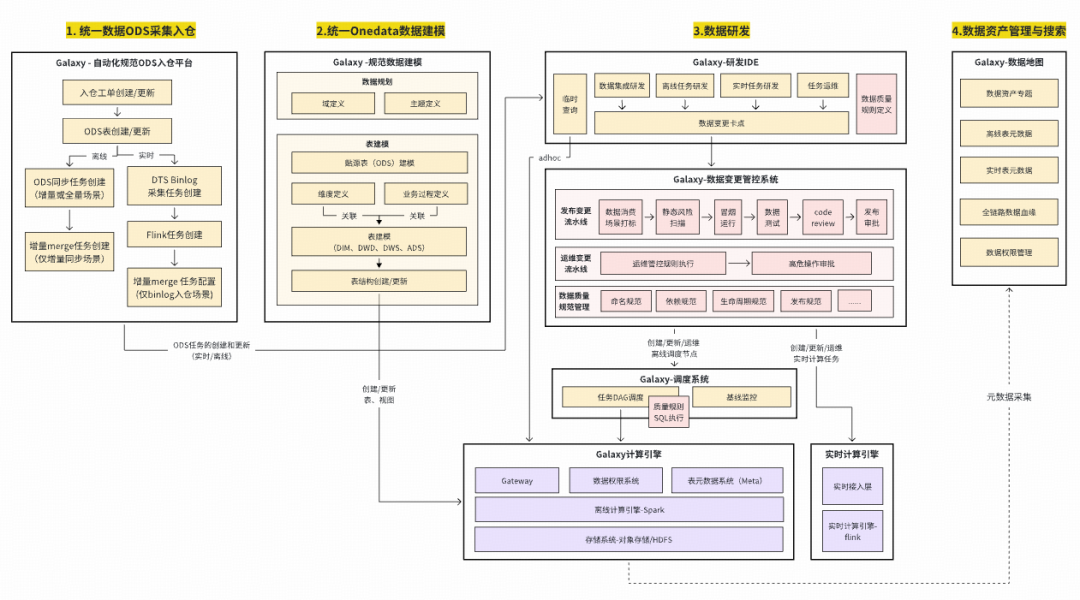
## III. Data Development Suite — “Cockpit” of Data Construction
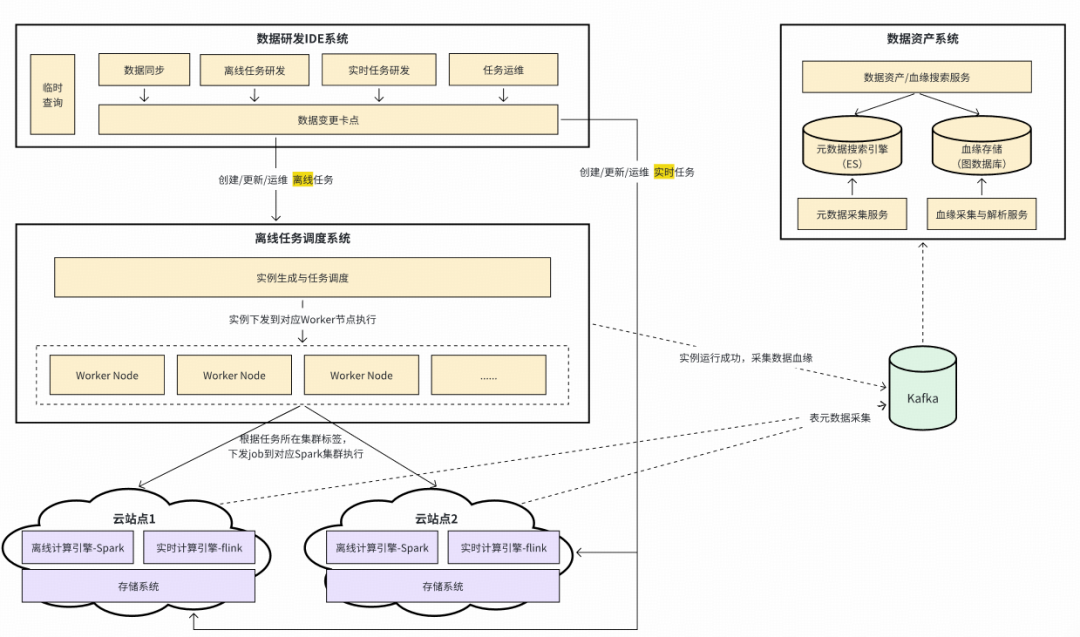
### 1. System Architecture
Includes:
- **IDE**
- **Data asset system**
- **Task scheduling system**
### 2. Data Synchronization Technology
Sync (integration) moves data between heterogeneous sources & warehouse.
Two modes:
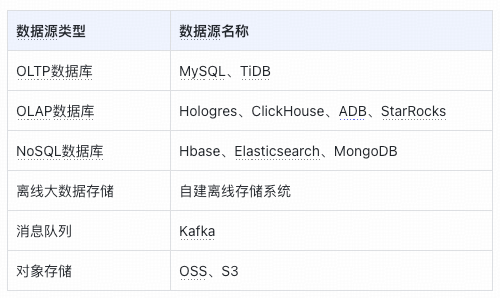
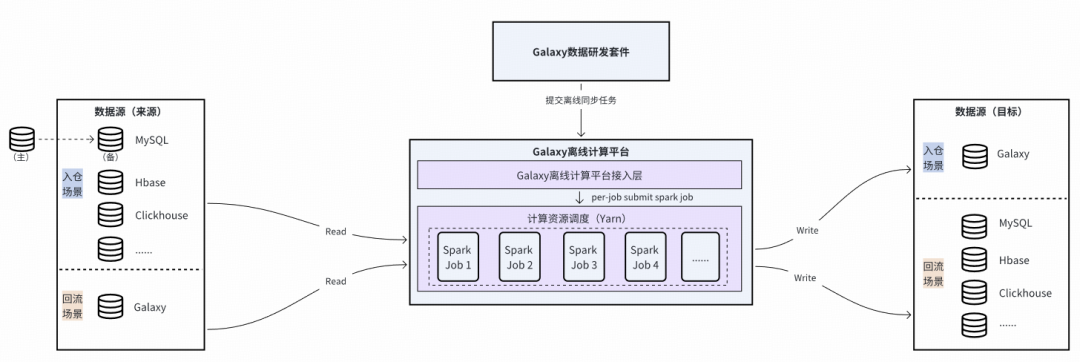
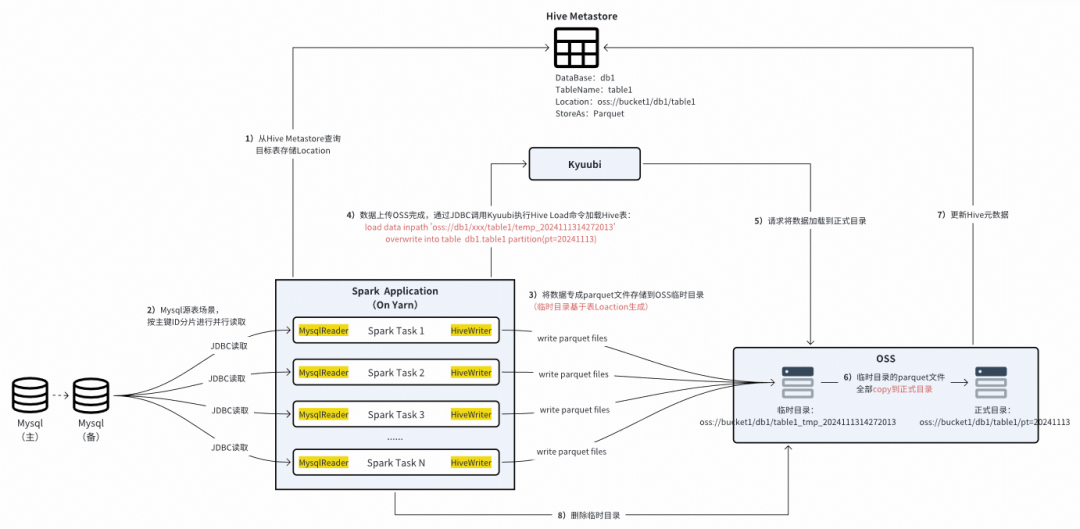
#### **Offline Sync**:
- **Batch write/read**, periodic jobs
- Supports multiple source types
- Architecture: Spark Jar kernel
#### **Real-Time Sync**:
**Why needed**:
- Reduce load, improve timeliness, meet SLA
Approaches:
1. **Binlog-based warehousing**
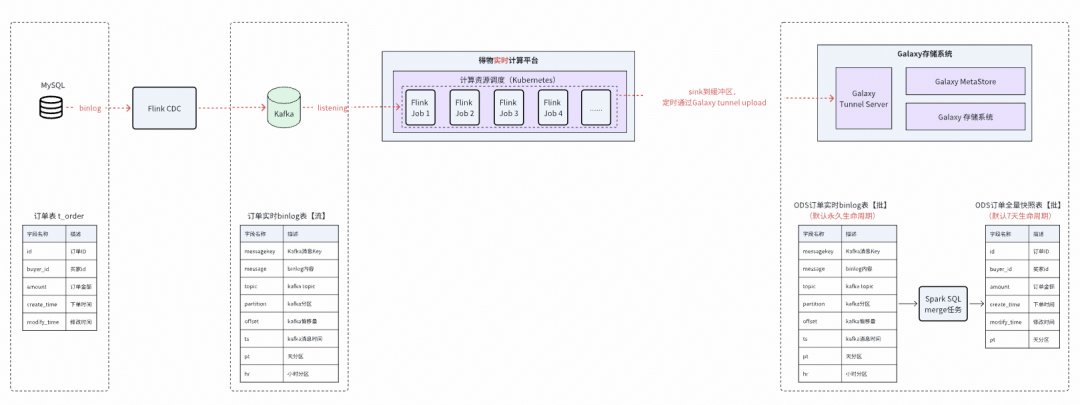
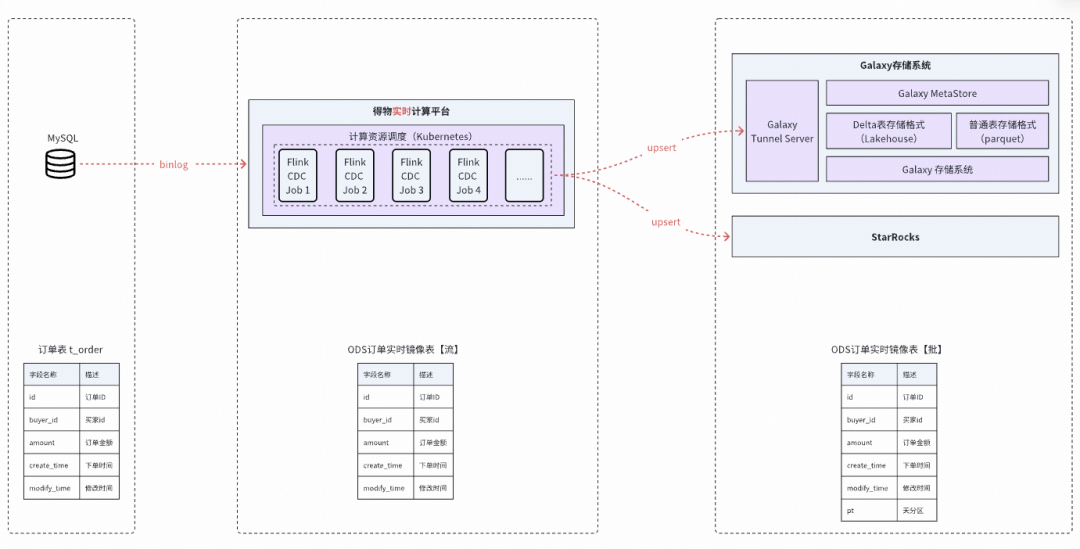
2. **Mirror sync via Flink CDC**
---
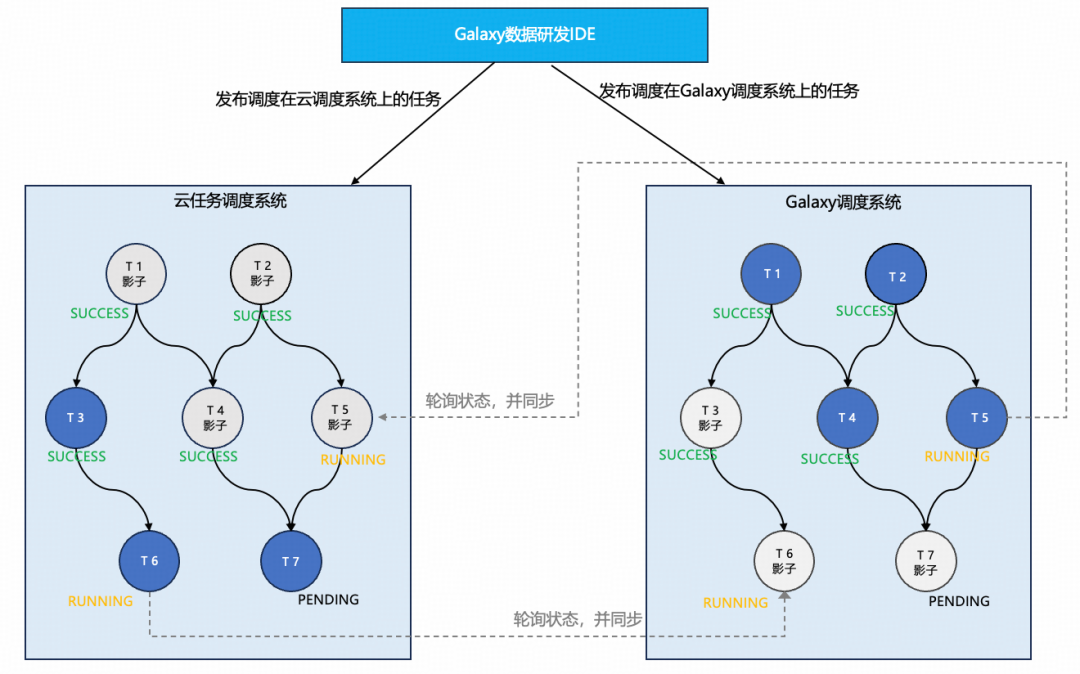
### 3. Task Migration Plan
**Phased strategy**:
1. **Platform Layer Migration** — quick business onboarding, keep original scheduler
2. **Scheduler Migration** — seamless, remove cloud deps
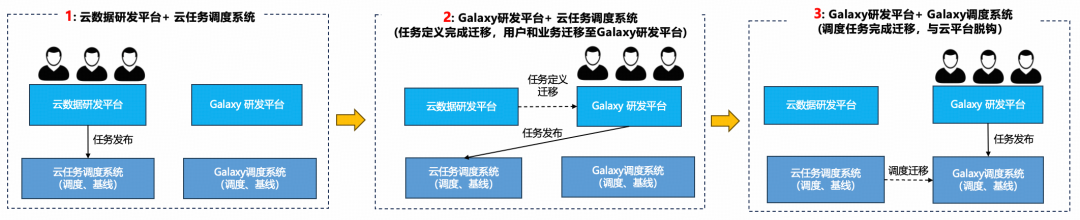
**Shadow nodes** enable **transparent migration**, parallel scheduler operation, rollback.
---
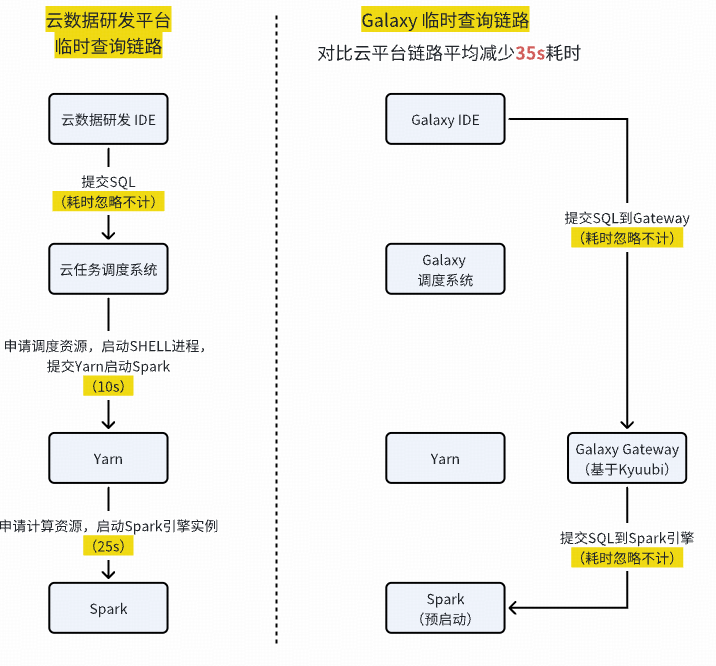
### 4. Function Development & Migration Progress
**Optimizations**:
- SQL query acceleration: save **35+ seconds/query**
- Online warehousing automation: save **30+ mins/request**
Cost savings: reduced cloud compute res by **400+ cu**, saving **~¥20k/month**.
---
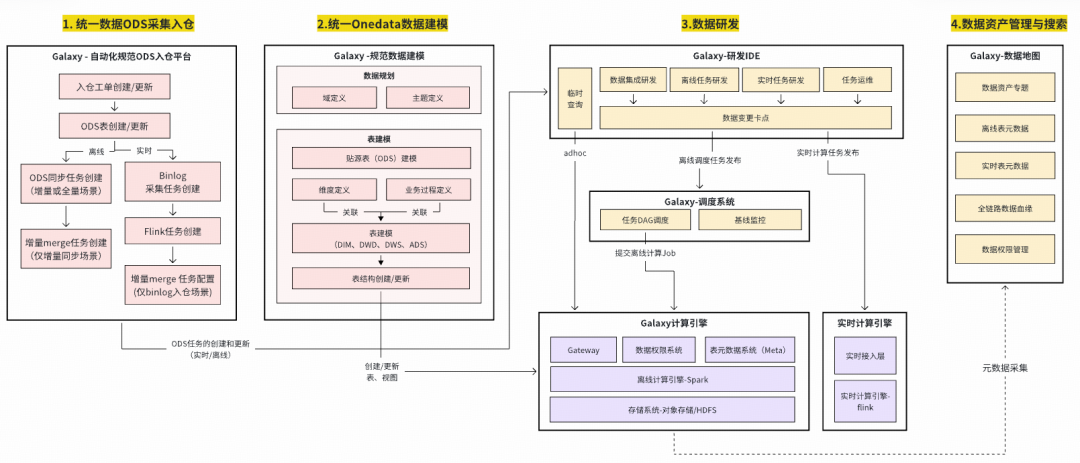
## IV. Data Architecture Technology — “Chassis” of Data Assets
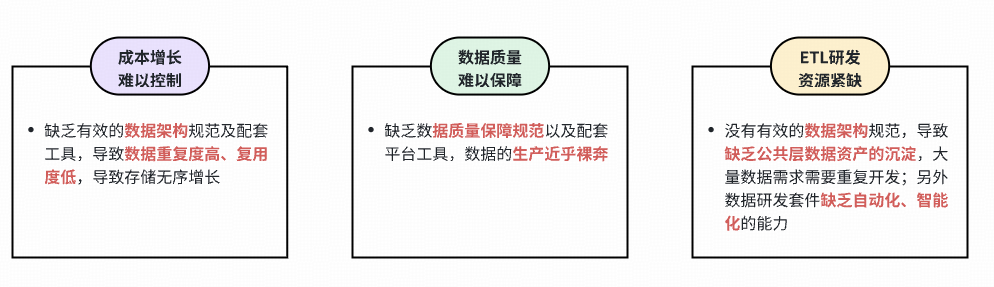
### Problems:
- **Redundancy**: duplicate data & metrics
- **Ambiguity**: unclear definitions
- **Cost**: uncontrolled storage growth
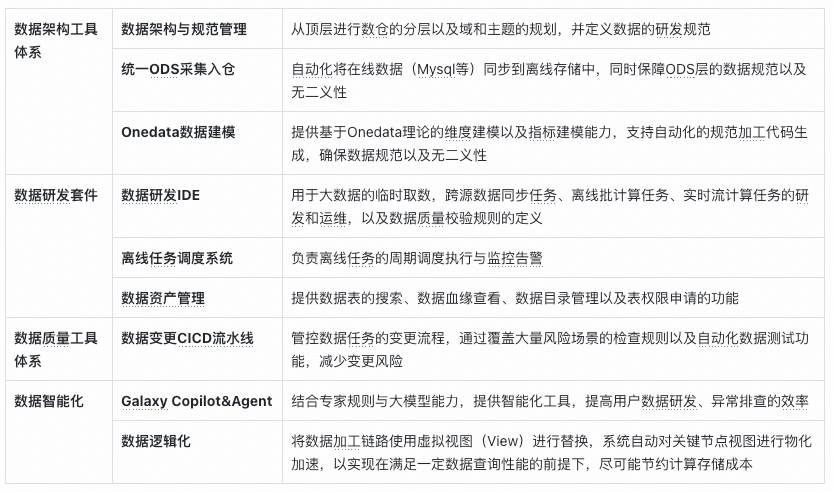
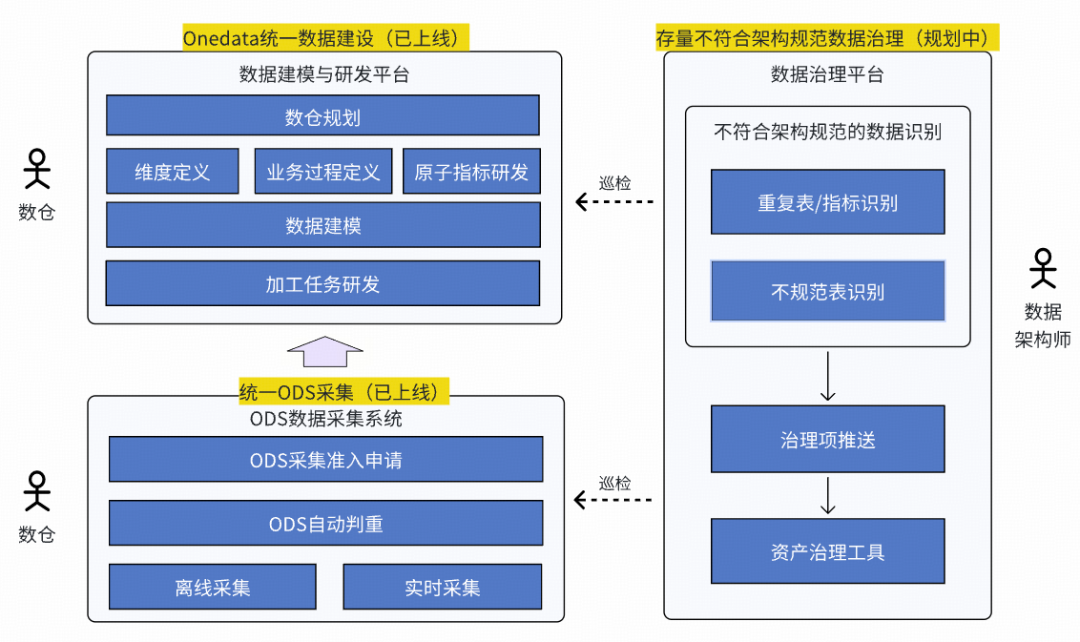
### Solution: **Onedata Methodology**
- Unified standards for collection & production
- Improves usability, reusability, efficiency, reduces cost
- Enforces **ODS layer & warehouse** standardization
---
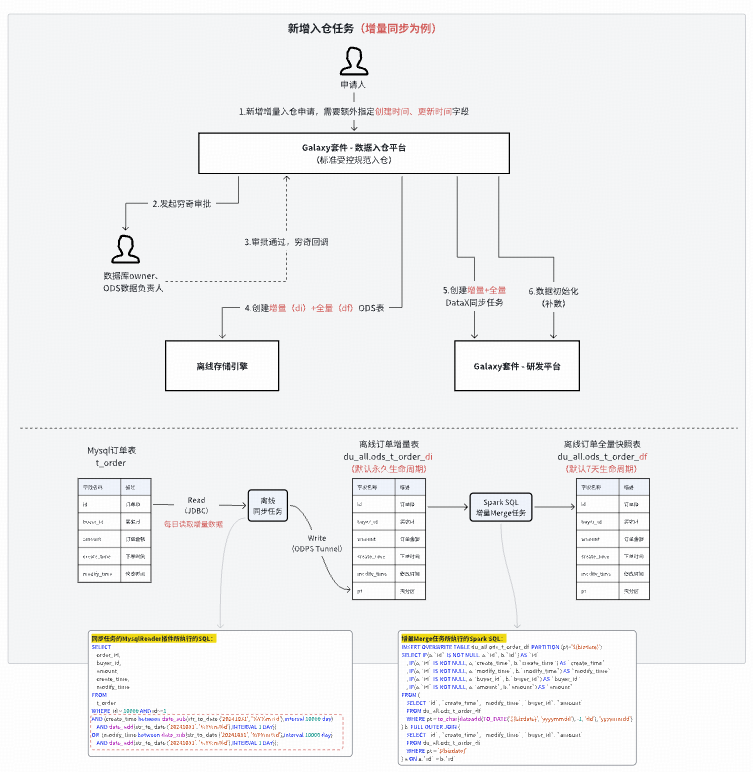
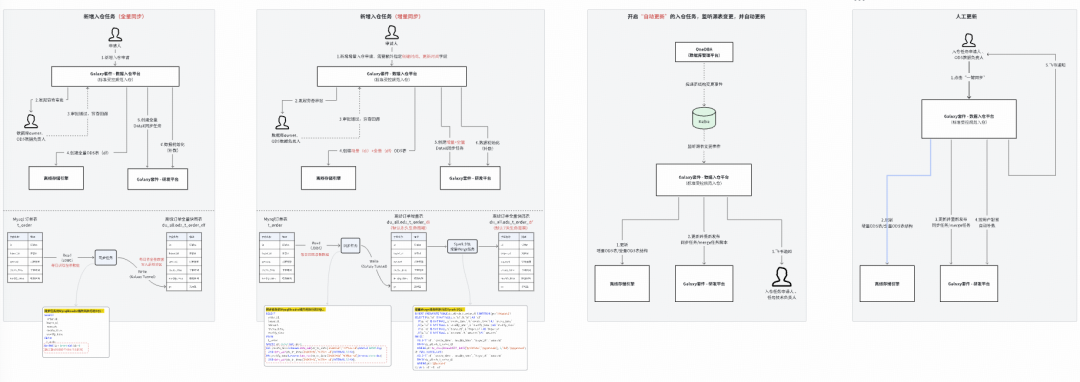
### 1. Unified ODS Automated Data Ingestion
- Prevents duplication
- **Two-tier approval**
- Controlled lifecycle
- Full-process automation
Supports MySQL & TiDB, full & incremental sync.
---
### 2. Standardized Data Modeling & Automated Metrics
- **Dimensional modeling**
- Globally consistent dimensions/facts
- Automated metric code generation:
- Atomic metric definition
- Business constraints
- Statistical period & granularity
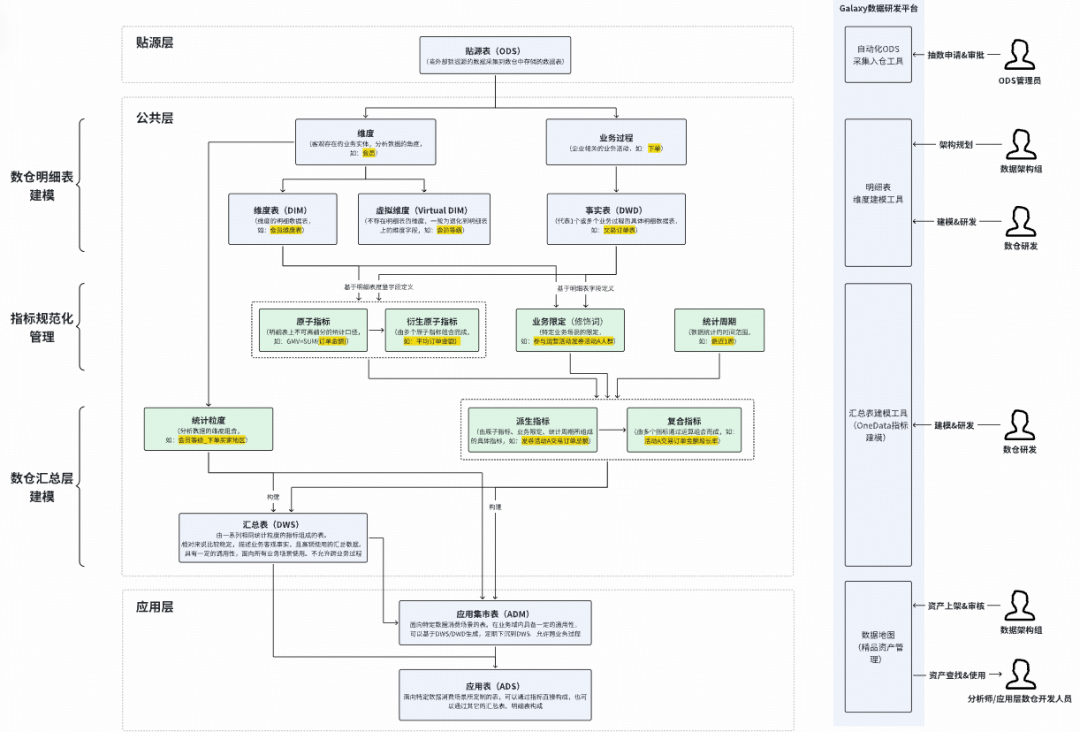
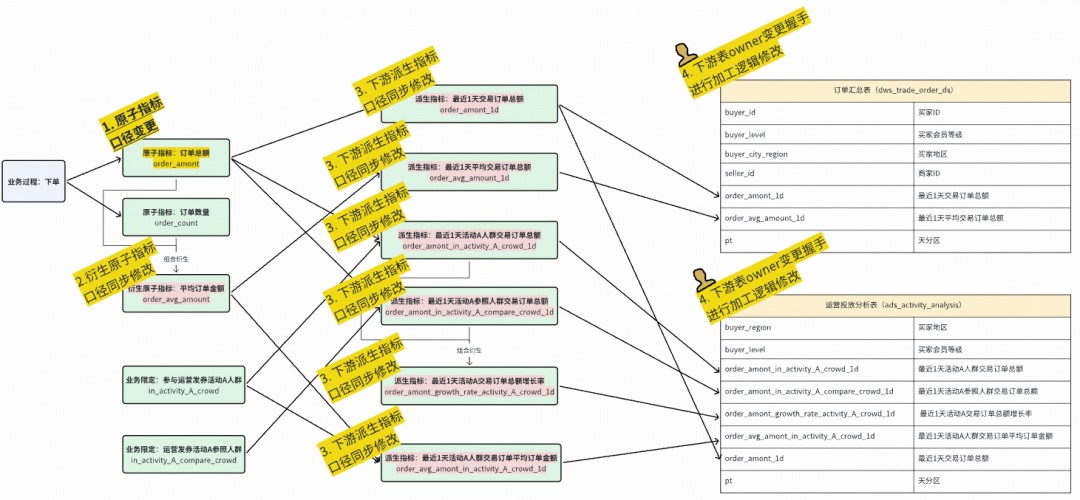

**Example**:
Data model → Auto SQL generation → Optimization
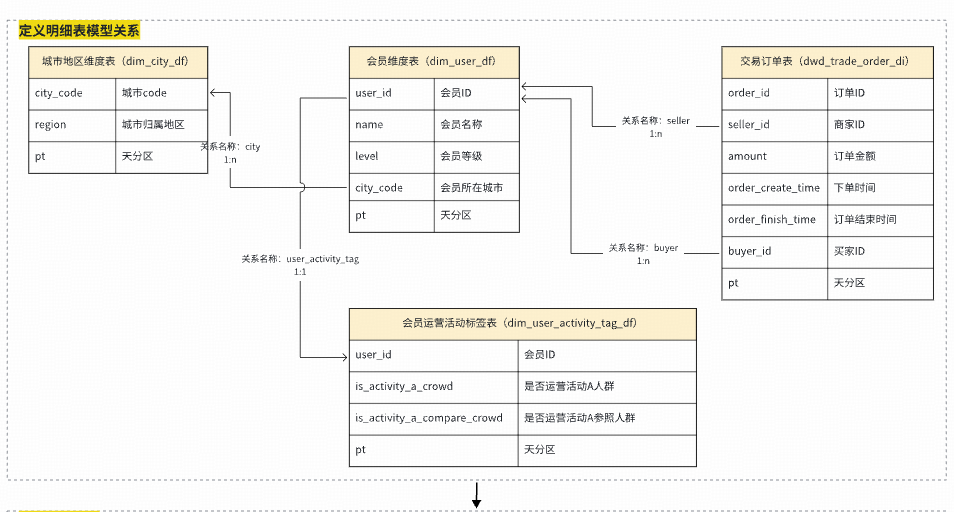
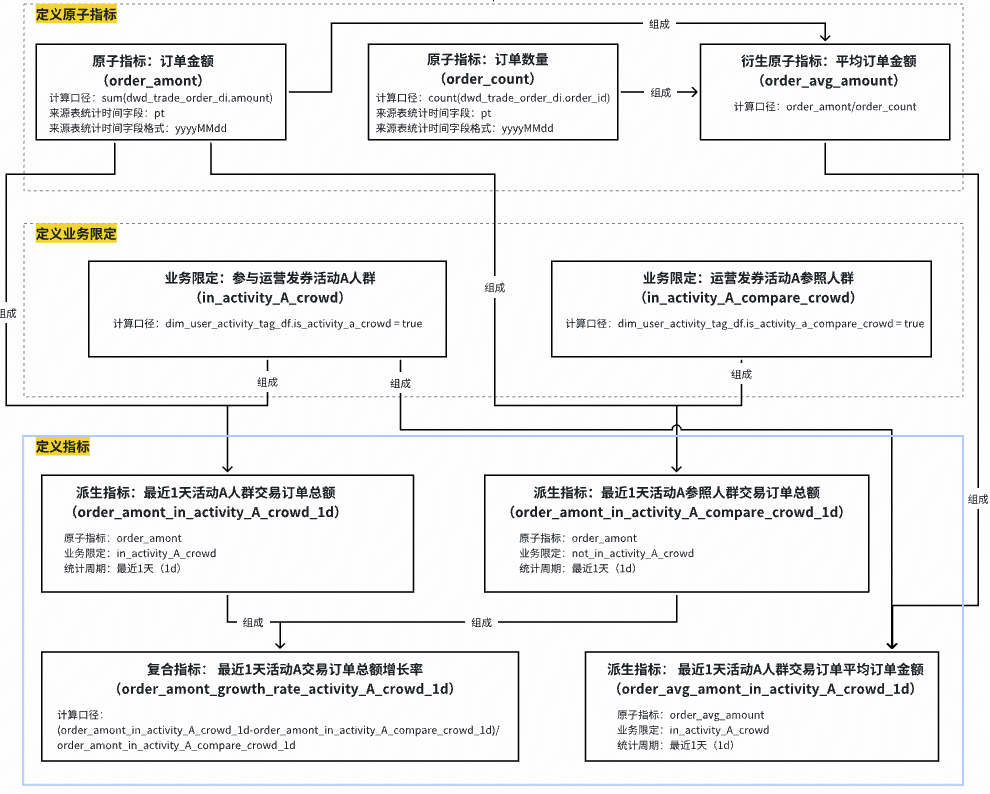









---
### Progress & Results:
- **93.6%** of new ODS ingestion auto-generated
- Storage growth reduced from **32% → 8%**
- Community DW: **1200+ metrics, zero ambiguity**
- Merchant DW: efficiency ↑ **40%**, throughput **75% → 90%**, reuse cost savings **¥50k/month**
---
## V. Data Quality Technology — “Brake Pads” of Data Production
### Risks:
- DW assets tightly linked to online ops
- P0-level asset loss scenarios
- Historically: weak change control, limited quality tools
### Galaxy Data Quality Suite:
**Capabilities**:
1. **Verification rules** — halt anomalies
2. **Change control pipeline** — tag, scan, review, test, approve
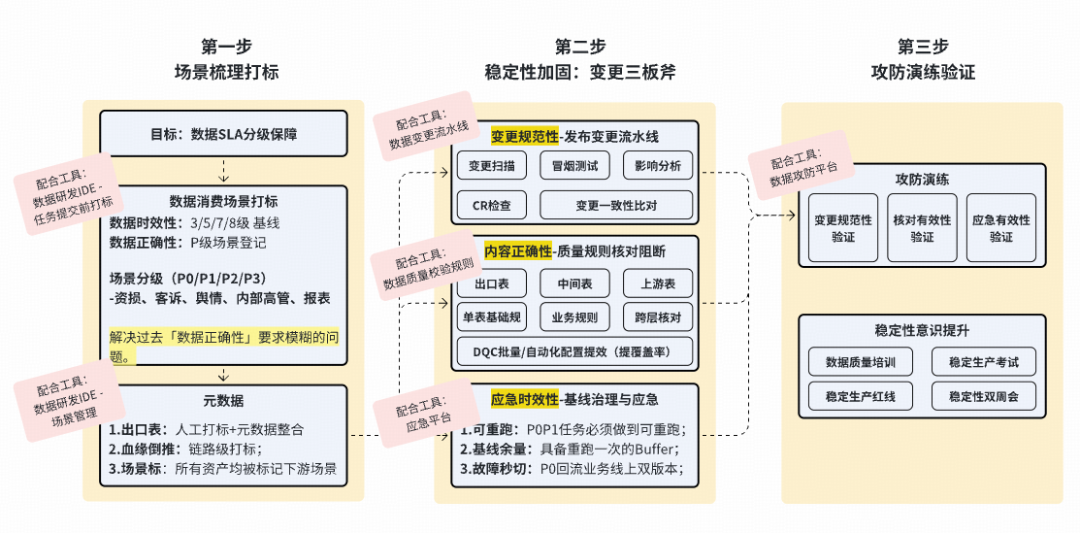
---
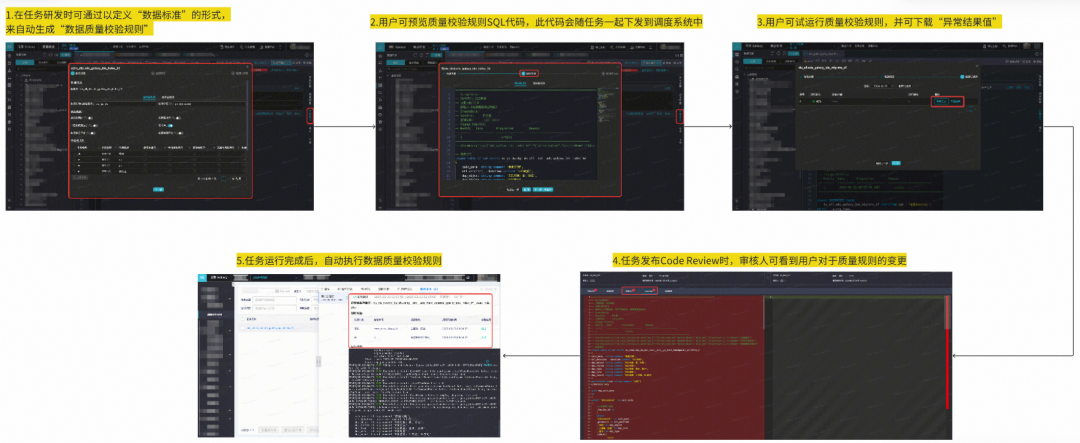
#### Data Quality Verification Rules:
- 15 rule types, 100% scenario coverage
- **P0 coverage**: 96% at task level, 100% for critical fields
- 1200+ rules added Q3 2025
---
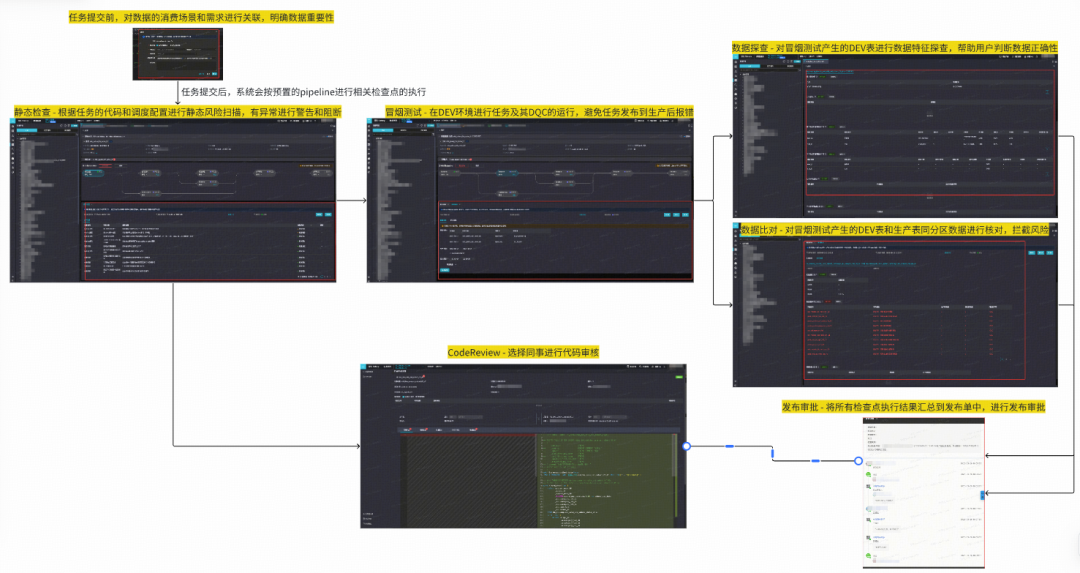
#### Change Control Pipeline:
- 48 static risk rules, 94% coverage
- Detection rate 98%, 600+ risk events intercepted biweekly
---
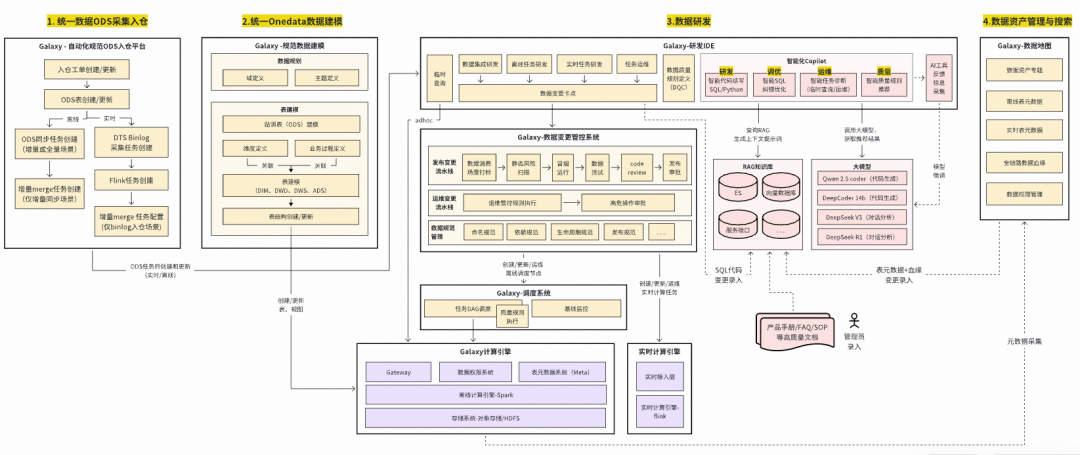
## VI. Intelligent Data Development — “Driver Assistance”
### Roadmap:
**L1 Copilot** → **L2 ETL Agent** → **L3 Logicalization**

---
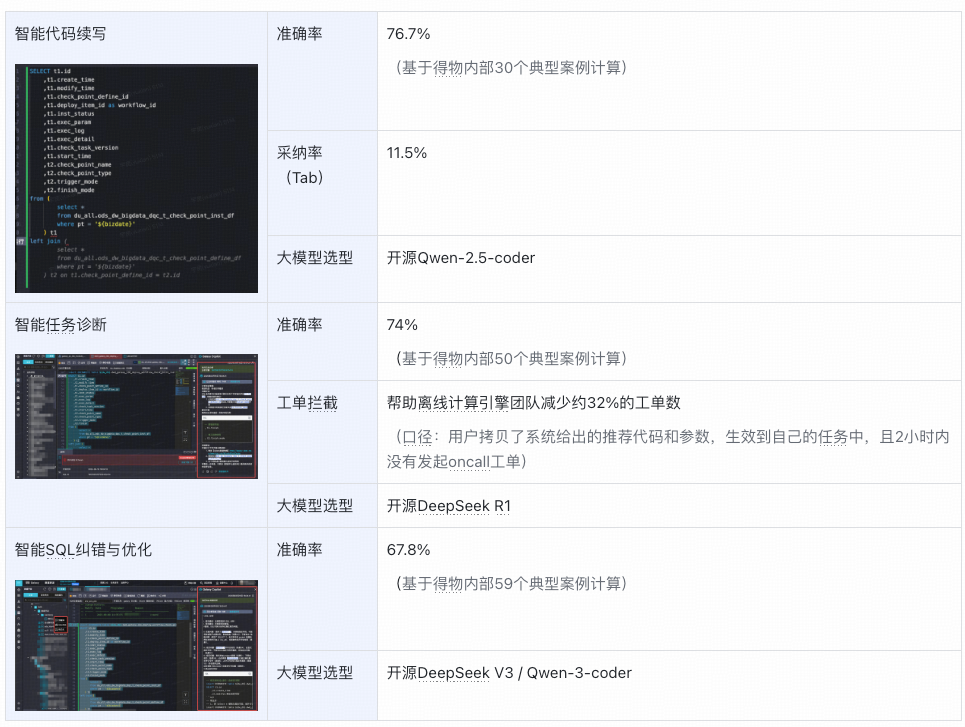
### L1: Copilot Stage
- **SQL code completion**
- **Task diagnostics**
- **SQL error correction & optimization**
- Model: **Qwen-2.5-coder**
Workflow:
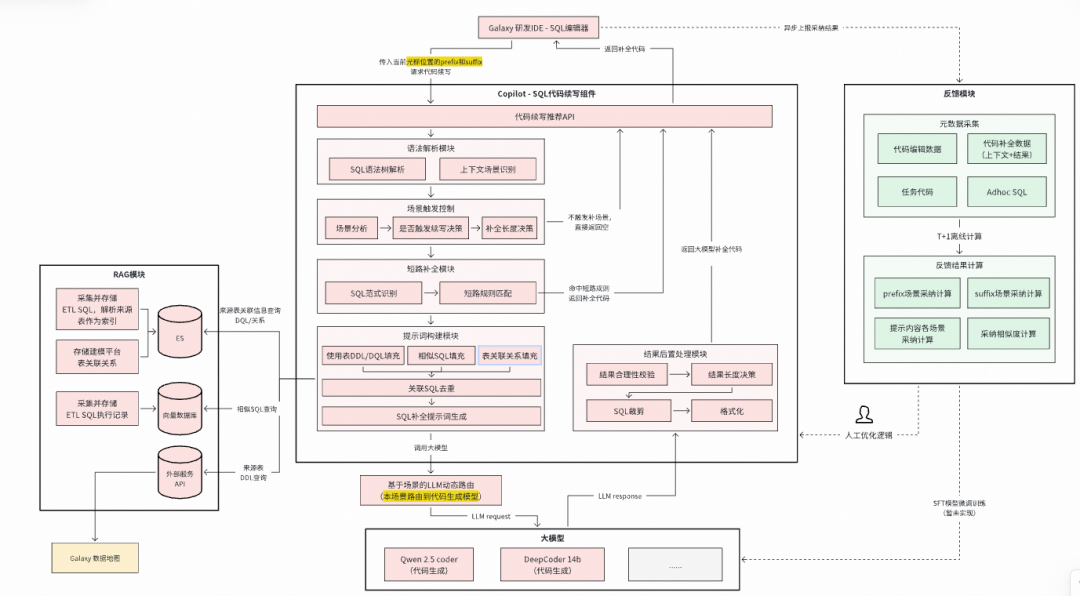
Modules:

### Impact:
- Code completion activation: 98.5% among active users
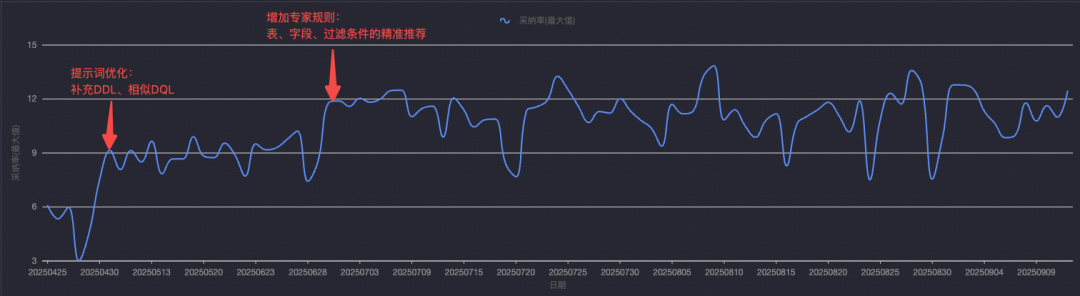
---
## VII. Future Plans
### **1. Intelligent ETL Agent (L2)**
- **NL2Metric2SQL** pipeline
- Uses Onedata semantic layer
- Example flow:
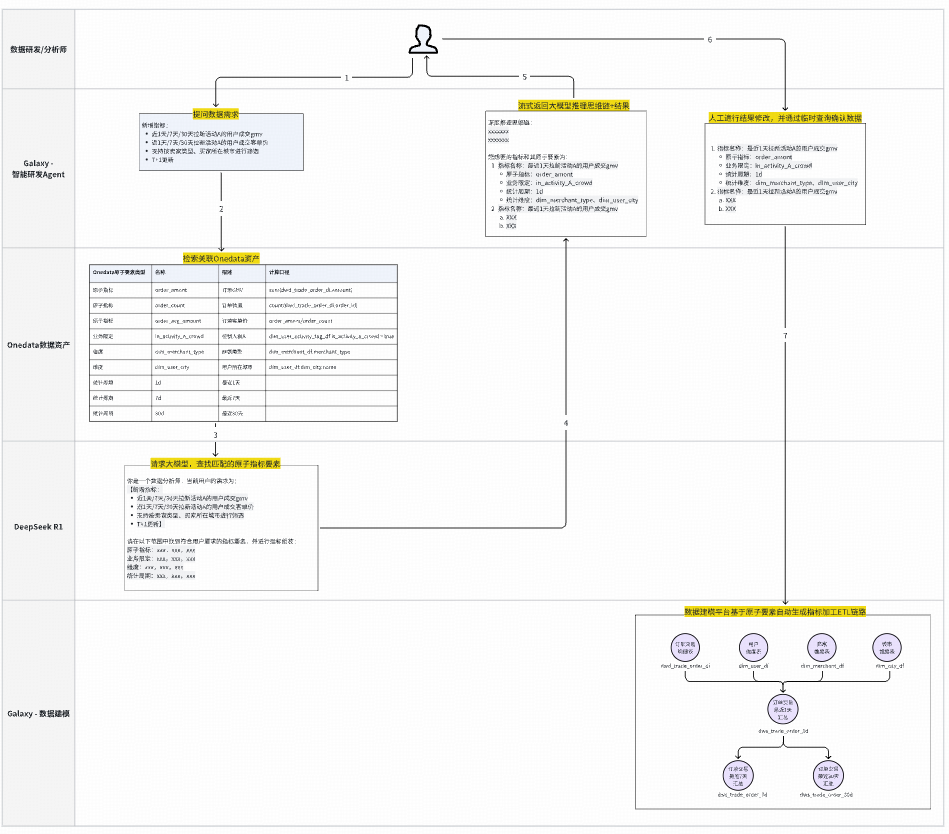
Architecture:
---
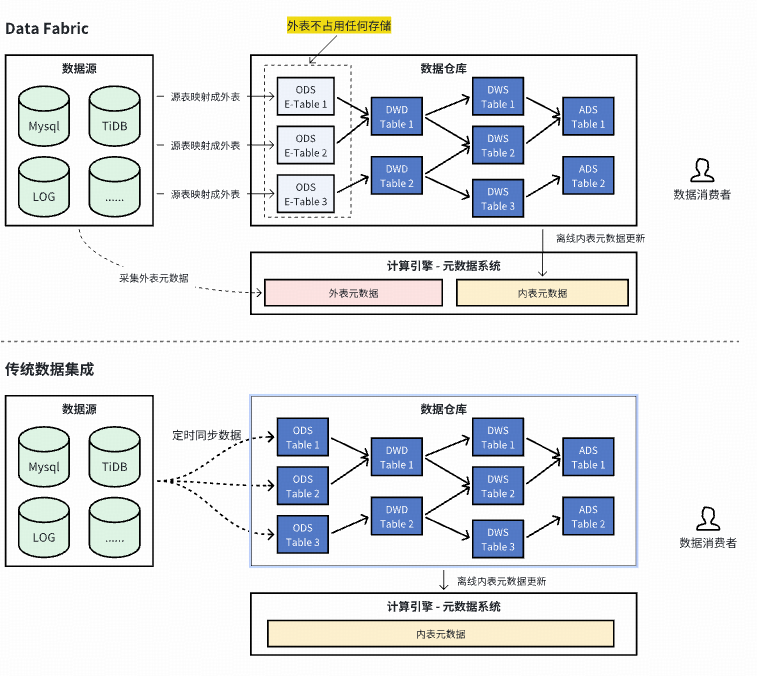
### **2. Data Fabric Architecture**
- Goal: avoid offline storage waste
- Concept: **Query in place via external tables & federated queries**
- “Move computation, not data”
---
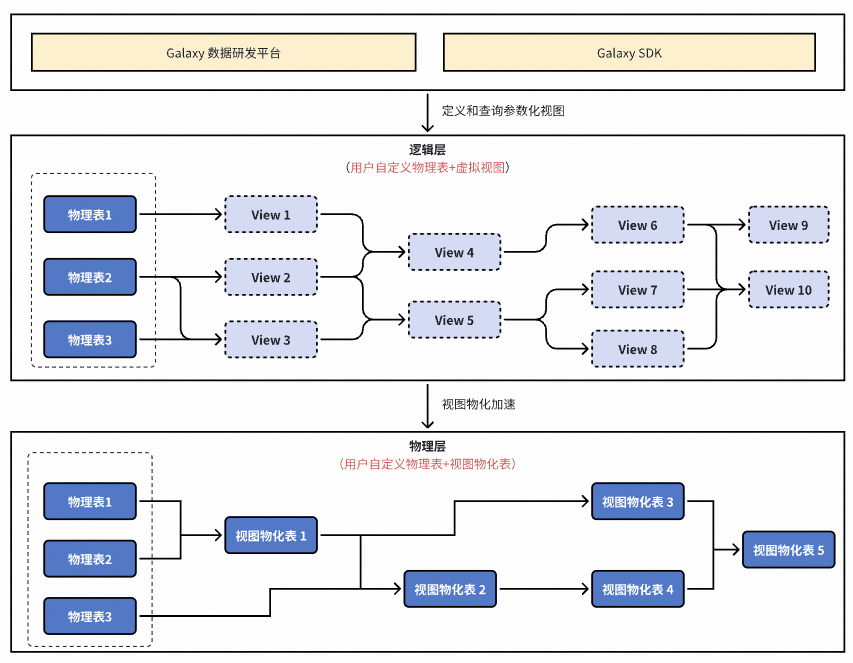
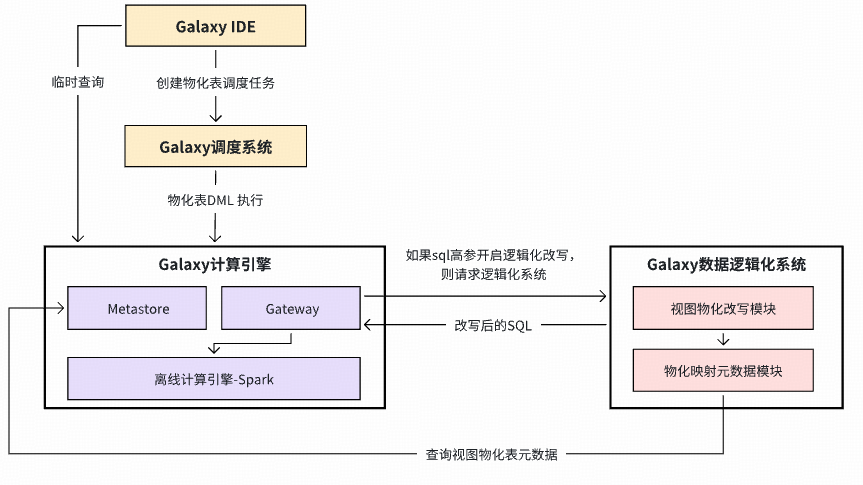
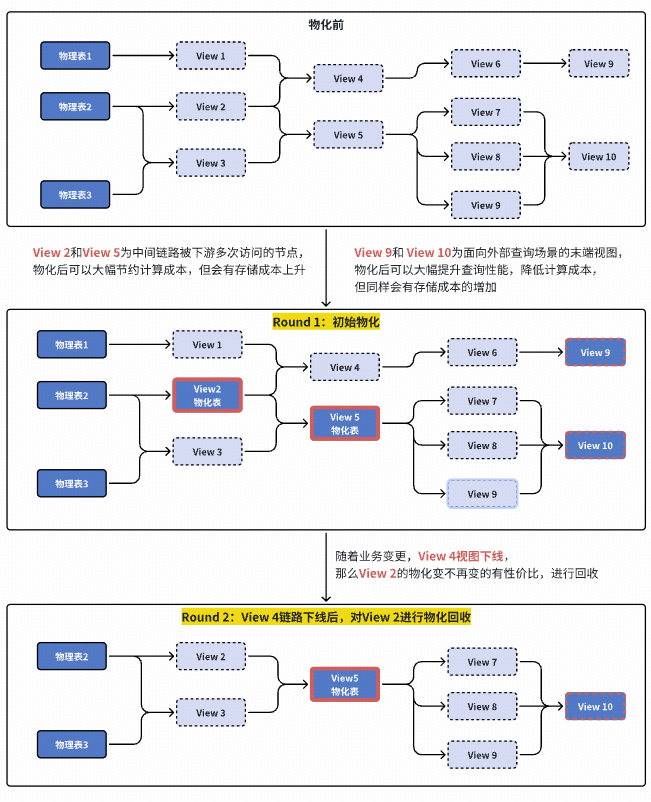
### **3. Data Logicalization (L3)**
- Build pipelines via parameterized views
- Materialized view detection & optimization
---
## 📌 Related Reads
1. [Spring Circular Dependencies — Dewu Tech](...)
2. [Apex AI-Assisted Coding — Dewu Tech](...)
3. [Fastjson Analysis — Dewu Tech](...)
4. [TTL Agent Pitfalls — Dewu Tech](...)
5. [ThreadPoolExecutor Analysis — Dewu Tech](...)
---
**Follow Dewu Technology for updates every Monday & Wednesday**
Scan QR to add WeChat assistant:

[Read Original](2247541473) | [Open in WeChat](...)
---



