Five-Year Uptime Streak Broken: Developer Laments “Aggressive Crawlers Ruined My Weekend”

Bear Blog’s Brush with Crawlers and DDoS — Lessons Learned
The proliferation of automated web crawlers is becoming a serious threat to personal blogs. Herman Martinus, creator of Bear Blog — minimalistic, ad-free, and privacy-focused — recently experienced his first major outage since the platform’s launch.
---
Incident Overview
On October 25, Bear Blog’s reverse proxy service — responsible for custom domains — failed, causing timeouts across all custom domain requests.
Compounding the issue:
- No timely alerts: Monitoring didn’t trigger notifications.
- Weekend downtime: Herman didn’t discover the outage until much later.
Following the event, Herman wrote a detailed post linking the root cause to a broader issue: explosive growth in crawler traffic.


---
The Three Faces of Crawlers
Earlier in the year, Herman published The Great Scrape, highlighting the domination of robot traffic. He categorizes crawlers into:
- AI Crawlers
- Gather data for training large language models (LLMs).
- Often declare identity (e.g., ChatGPT, Anthropic, XAI).
- Two purposes:
- User-initiated search queries → Allowed on Bear Blog.
- Data mining for training sets → Blocked.
- Malicious Crawlers
- Scan for vulnerabilities (e.g., misconfigured WordPress, exposed `.env` or AWS credentials).
- Intercepted nearly 2 million malicious requests in 24 hours.
- Frequently rotate IP addresses, possibly using mobile app network tunnels for traffic obfuscation.
- Uncontrolled Automation
- “Toy” crawlers created in minutes using AI tools.
- Run continuously, unintentionally generating mild DDoS effects.
- PC performance today can rival VPS hosting, amplifying the problem at scale.
---
Security Measures Attempted
To counter disruptive bots, Herman employed:
- Cloudflare WAF rules + rate limits.
- Custom detection logic to block based on behavioral analysis.
Experimental tactics (later dropped due to complexity):
- Deploying Zip Bombs against crawlers.
- Proof of Work challenges to consume bot CPU cycles.
- Feeding infinite junk data to exhaust bots.

---
DDoS Attack on Oct 25
What Happened?
Hundreds of blogs faced tens of thousands of requests per minute.
While web servers scaled well under crawler load, the reverse proxy — upstream of many defenses — was the single point of failure. Under load, it simply crashed.
Monitoring graphs showed a huge traffic spike dwarfing all prior activity.
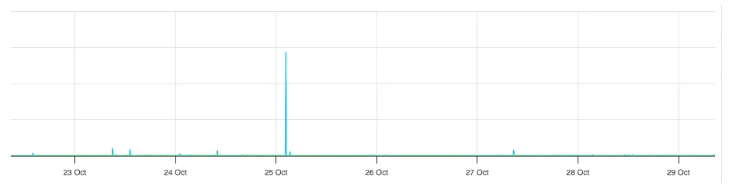
This was Bear Blog’s first crash in five years. The monitoring tool failed to notify despite “critical alert” settings.

---
Post-Incident Improvements
Herman’s action plan includes:
- Monitoring redundancy: Added a second system with alerts via phone, SMS, and email.
- Aggressive proxy filtering: Early abnormal traffic drops server load by ~50%.
- Proxy scaling: Capacity boosted ×5.
- Automatic restart: Triggered if bandwidth hits zero for 2 consecutive minutes.
- Public status page: status.bearblog.dev shows real-time uptime.
---
Key Takeaways
> “Today, most public internet traffic comes from bots. The online environment is harsher than ever, but we must protect the corners of the internet worth staying in. This arms race is far from over.”
Herman invites developers to share anti-crawler strategies — from infrastructure hardening to creative deterrence — acknowledging that defenses evolve as fast as attacks.
---
Related Resources
For creators looking beyond defense, platforms like AiToEarn官网 offer an open-source global AI content monetization solution.
Features include:
- AI-generated multi-platform publishing.
- Built-in analytics.
- AI模型排名 for model performance assessment.
While AiToEarn won’t stop crawlers, it can help creators focus on building value worth protecting.
---