From 50+ Projects by OpenAI, Google, and Others: Why Stunning AI Demos Often End in Failure

!image
Linkloud Introduction
A perfect demo and enthusiastic early feedback often mask serious risks: why can these lead to frequent issues and loss of trust when an AI product goes live? Traditional software best practices don’t fully apply to the AI era.
Drawing from experience leading 50+ AI projects at OpenAI, Google, and others, Aishwarya Reganti and Kiriti Badam propose the Continuous Calibration / Continuous Development (CC/CD) framework.
This guide explores:
- Two fundamental challenges in AI product development:
- Non-determinism
- The trade-off between agency and control
- How CC/CD addresses these challenges to build stable, trustworthy AI products.
> For more complete content, click “Read the original”.
---
1. Understanding the CC/CD Framework
Imagine this:
Your AI project makes a flawless demo, early reviews are glowing, stakeholders are thrilled… then real-world problems emerge. Issues prove complex and hard to trace, confidence drops, and trust erodes.
Why?
Over 50 deployments have shown two core truths:
- AI products are inherently non-deterministic
- Agency and control are always in tension
Failing to embrace these truths leads to cascading failures despite impressive demos. The CC/CD framework helps teams design for clarity, stability, and trust.
---
1.1 Non-Determinism in AI
Traditional software is:
- Predictable: fixed logic maps specific inputs to specific outputs
- Bugs: reproducible and traceable
AI systems:
- Unpredictable inputs: users give open-ended prompts, voice, or natural language
- Unpredictable outputs: models generate responses based on patterns, not fixed rules
- Same request → different outputs depending on phrasing, context, or model version
Implication:
Design must accommodate wide-ranging behaviors from users and AI. Continuous calibration is essential.
---
1.2 The Agency–Control Trade-off
Agency = AI’s ability to act autonomously (book flights, run code, close support tickets)
> More agency → Less control
Early mistakes often involve granting too much agency before validating system reliability.
Without a controlled rollout, autonomy can:
- Reduce transparency
- Erode trust
- Create untraceable decision logic
Solution:
Earn agency step-by-step via CC/CD – similar to CI/CD but respecting AI’s unique behaviors.
---
2. CC/CD in Practice
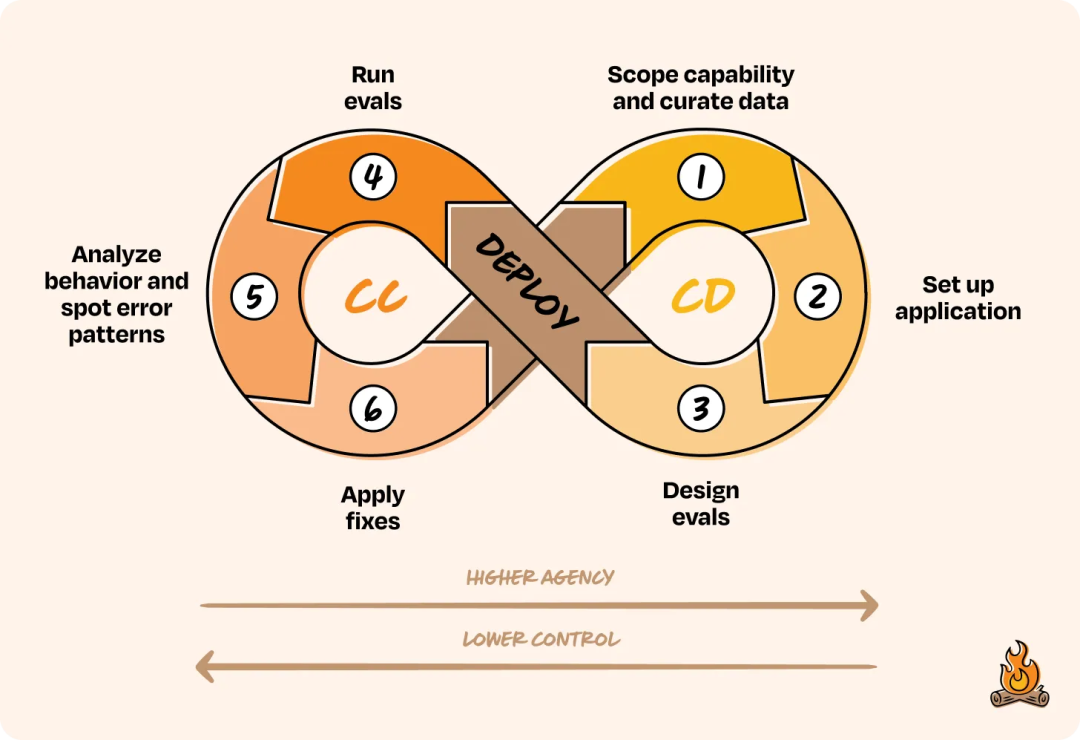
Goals:
- Reduce non-determinism via design + monitoring
- Earn agency progressively, not instantly
Two Loops:
- Continuous Development (CD): Scope → Setup → Evaluation design
- Continuous Calibration (CC): Deploy → Evaluate → Analyze → Fix
---
CD 1: Define Scope & Organize Data
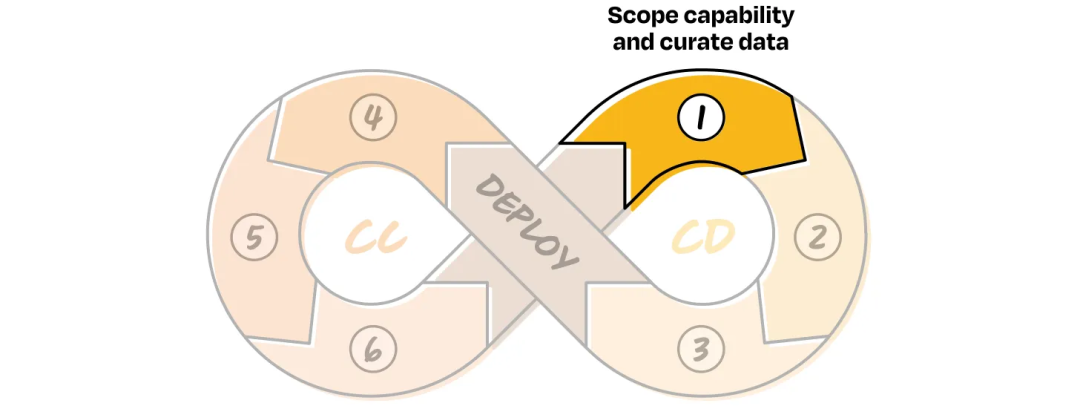
Versioning criteria:
- Level of agency
- Level of control retained
Guidelines:
- Start with low-agency, high-control features
- Gradually increase autonomy in each version
- Use small, observable, testable functions
Example: Customer Support
- V1: Route tickets
- V2: Suggest solutions
- V3: Auto-resolve with rollback
Data:
Collect a reference dataset to baseline expected behavior:
- User queries
- Target department
- Relevant metadata
- Aim for 20–100 samples to start.
---
CD 2: Set Up the Application
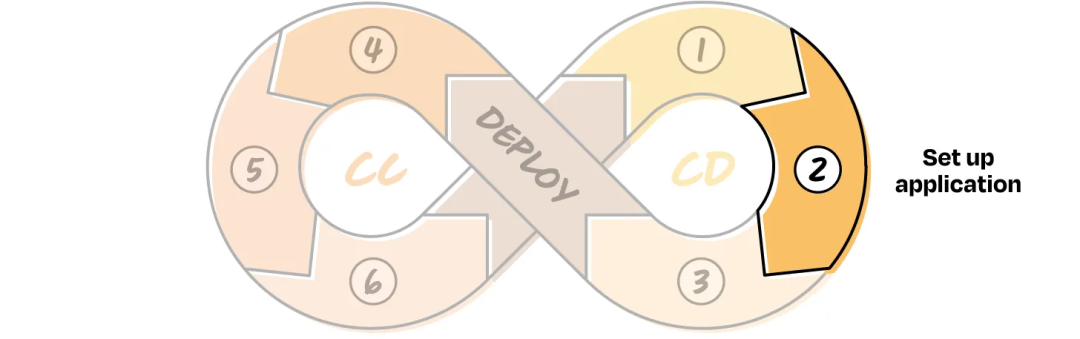
Avoid premature optimization:
- Build only what V1 needs
- Implement logging of:
- Inputs
- Outputs
- Interaction patterns
- Include human handoff mechanisms for error correction
---
CD 3: Design Evaluation Metrics (Evals)
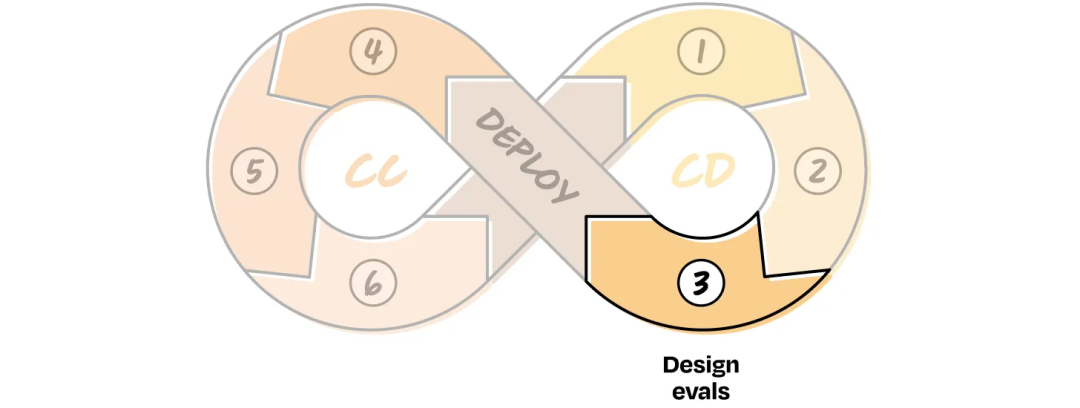
Evals = Scoring mechanisms to assess AI performance
Key differences:
- Handle ambiguity
- Application-specific
- Signals, not binary pass/fail
Example Metrics:
- V1 Routing Accuracy = % tickets routed correctly
- V2 Retrieval Quality = relevance of suggested solutions
---
Deployment: Transition to CC Phase
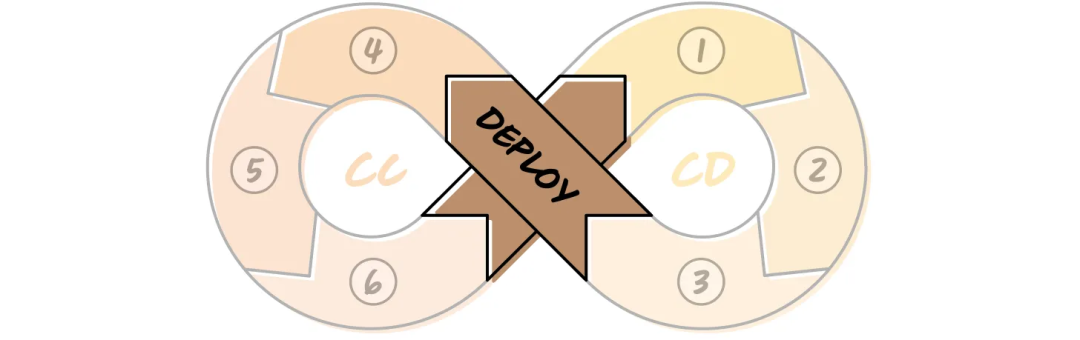
After CD1–CD3:
- Logging + handoffs are ready
- Evaluation metrics are in place
- Deploy to a small user group → Begin Continuous Calibration
---
CC 4: Run Evaluations on Live Data
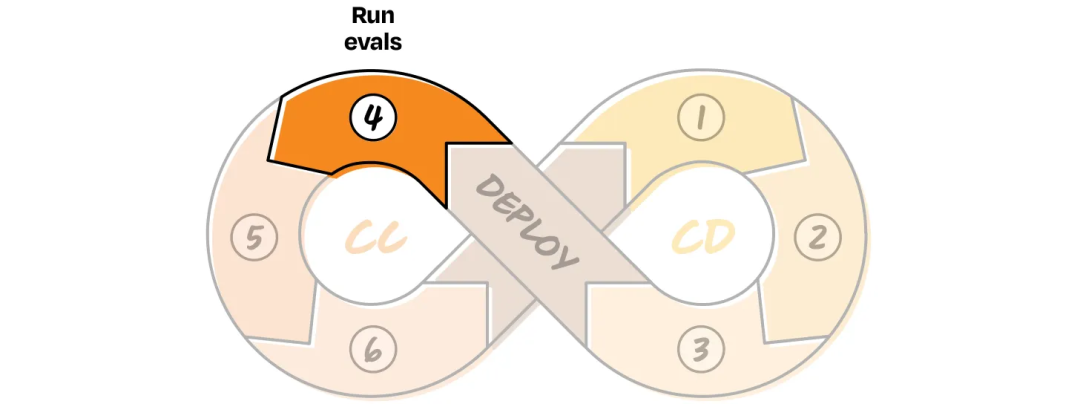
Run Evals using:
- Complete dataset if small
- Representative samples if large
- Use logs for proxy metrics (e.g., human reroutes).
---
CC 5: Analyze Behavior & Identify Errors
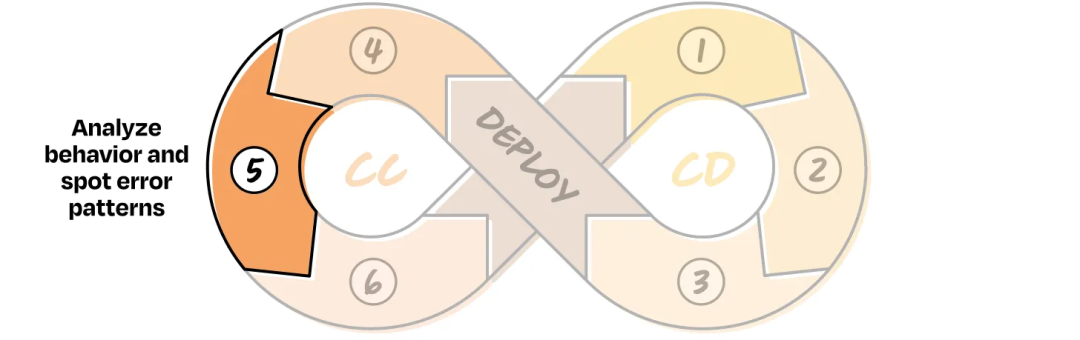
Process:
- Review low-performing segments
- Identify repeated error patterns
- Record in a simple table for iteration planning
---
CC 6: Apply Fixes
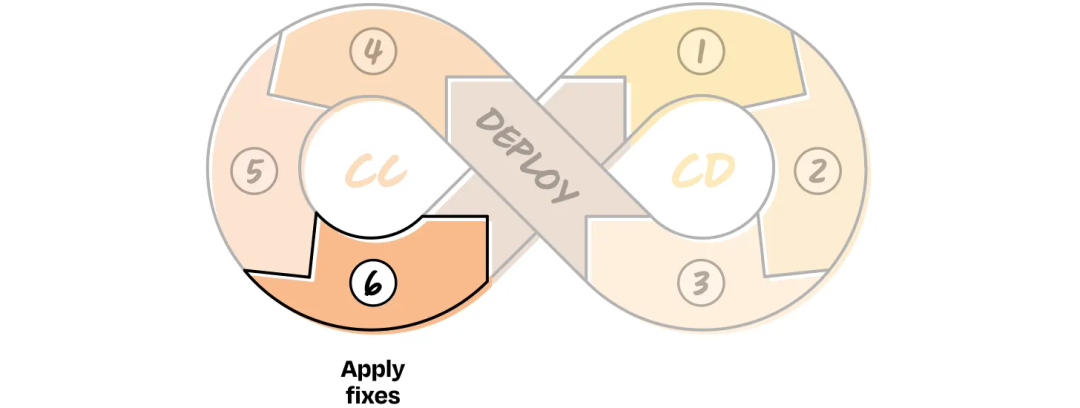
Types of fixes:
- Prompt refinements
- Model swaps
- Retrieval improvements
- Task decomposition
Iterate:
- Apply fix → Rerun Evals
- Adjust architecture based on data, not guesswork
- Refine evaluation design if needed
---
3. CC/CD Example: Customer Support
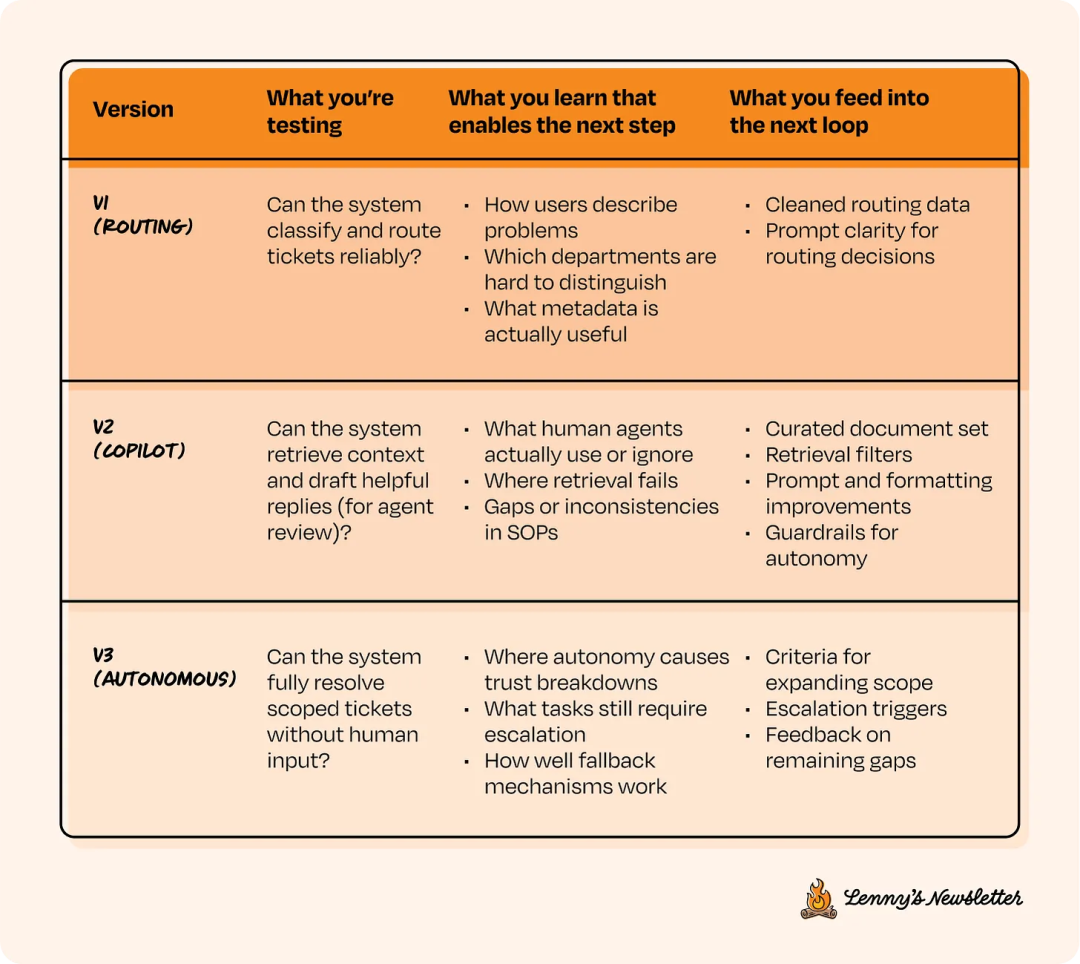
V1: Routing only → Gather intent data
V2: Draft responses → Find retrieval/document issues
V3: Auto-resolve → Rollback for exceptions
---
4. Core Principle: Judgment
CC/CD is a structured cycle for:
- Deciding what to release
- Defining “good enough”
- Knowing when to hand back control
No universal answers for:
- Features per version
- Duration before advancing
- Scope per stage
Use judgment for safe scaling.
---
Key Takeaways
- AI ≠ traditional software — accept non-determinism and plan for it.
- Manage agency vs control deliberately.
- CC/CD = design deliberate steps to earn trust before scaling autonomy.
- Start small, measure, calibrate, and expand.
---
Would you like me to create a one-page visual CC/CD cheat sheet summarizing the full framework flow? This could make it even easier for teams to adopt.



{kind=link}