# From Detection to General Perception: Building the Foundations of Spatial Intelligence
## 1. Importance of Visual Perception & Object Understanding
Visual perception is a **core capability** for AI systems to interact with the physical world, and a necessary step toward **general intelligence**.
This article is adapted from a June presentation at **AICon 2025 Beijing** by the IDEA Research Institute’s Chair Scientist in the Computer Vision & Robotics Research Center:
*"From Detection to General Perception: Building the Foundations of Spatial Intelligence"*.
**Key Focus Areas of the Talk:**
- Comparing **language-native** vs. **vision-native** model architectures.
- Evolution of **Transformer-based object detection** from **DETR** to **DINO**.
- Advances in **open-set detection**: **Grounding DINO**, **DINO-X**, and extensions to keypoint localization, attribute understanding, and 3D perception.
- Using detection technologies as the foundation for **spatial intelligence** and real-world AI applications.
---
### AICon 2025 Theme Preview
At the December 19–20 **AICon Beijing** conference:
- **Frontier topics**: Large model training & inference, AI Agents, new R&D paradigms, organizational transformation.
- **Goal**: Building trustworthy, scalable, and commercializable agentic operating systems.
- **Benefit for enterprises**: Cost reduction, efficiency improvement, growth breakthrough.
**Full schedule:** [AICon Beijing 2025](https://aicon.infoq.cn/202512/beijing/schedule)
---
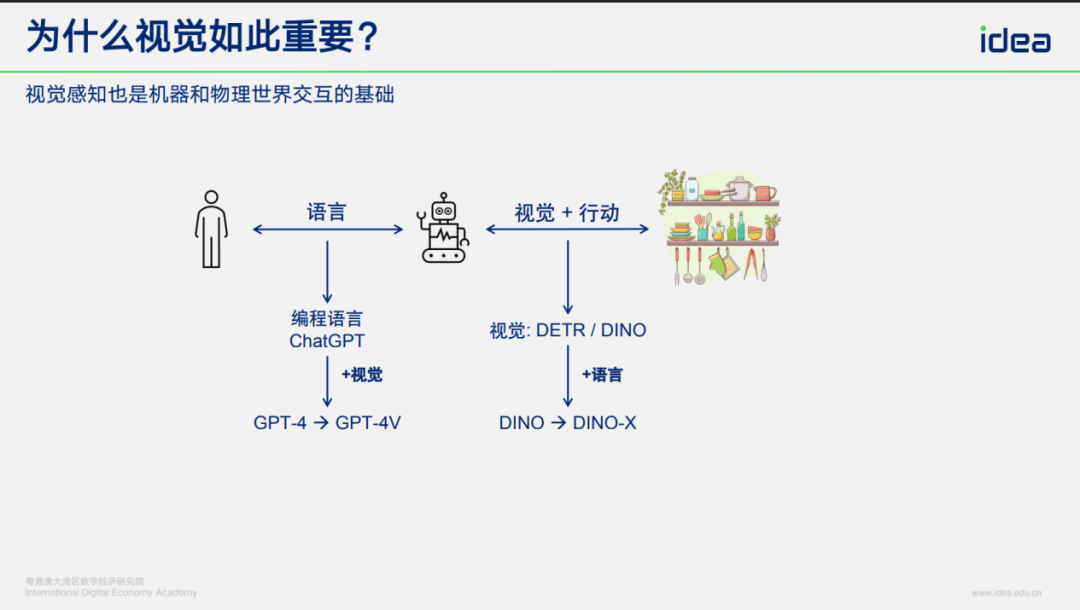
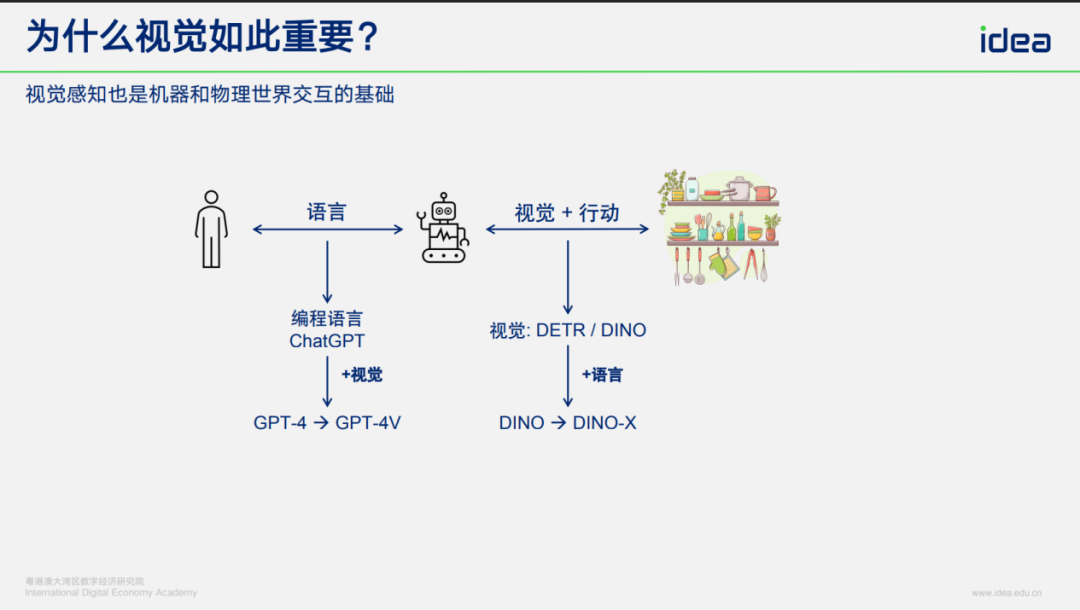
## 1.1 Visual Perception: Humans vs. Machines
- **Human and animal interaction without language** → relied on sight + action.
- **Machine-world interaction** → requires *visual perception* for action.
- Early interactions were via programming; natural language AI (e.g., GPT) opened usage to non-programmers.
- **Even with language**, machines **must** have strong visual capabilities for real-world action.
## 1.2 Two Primary Technical Routes
1. **Language Understanding**
2. **Visual Understanding**
Convergence is happening via **multimodal AI**.
Language without vision is inadequate; vision without language misses human-machine synergy.
---
## 1.3 Object Detection Basics
Object detection answers: *Does an image contain a specific object? If so, where?*
**Milestones Timeline:**
- **2001 — Viola’s Algorithm**
- Efficient face detection.
- Used in digital camera autofocus.
- **Faster R-CNN Era**
- Enabled breakthroughs in autonomous driving.
- Introduced accurate environmental perception.
Modern direction: detection + **open-set capability** + **zero-shot learning**, enabling detection of unknown objects via language prompts.
---
### Content Creation Connection
Platforms like **[AiToEarn官网](https://aitoearn.ai/)** help creators integrate visual AI research into practical, monetizable workflows:
- Publish to Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X.
- Use AI tools, analytics, and [AI模型排名](https://rank.aitoearn.ai) for optimization.
---
## 1.4 Transformer Architecture in Vision
Pre-2020 → Transformers mainly used for **language**.
**2020 DETR (Detection Transformer)** brought Transformers to **vision**, but faced:
1. Slow convergence (10× slower).
2. Lower performance than CNN-based methods.
Our **DINO** series solved these:
- Faster convergence.
- Achieved **SOTA** performance in object detection.

---
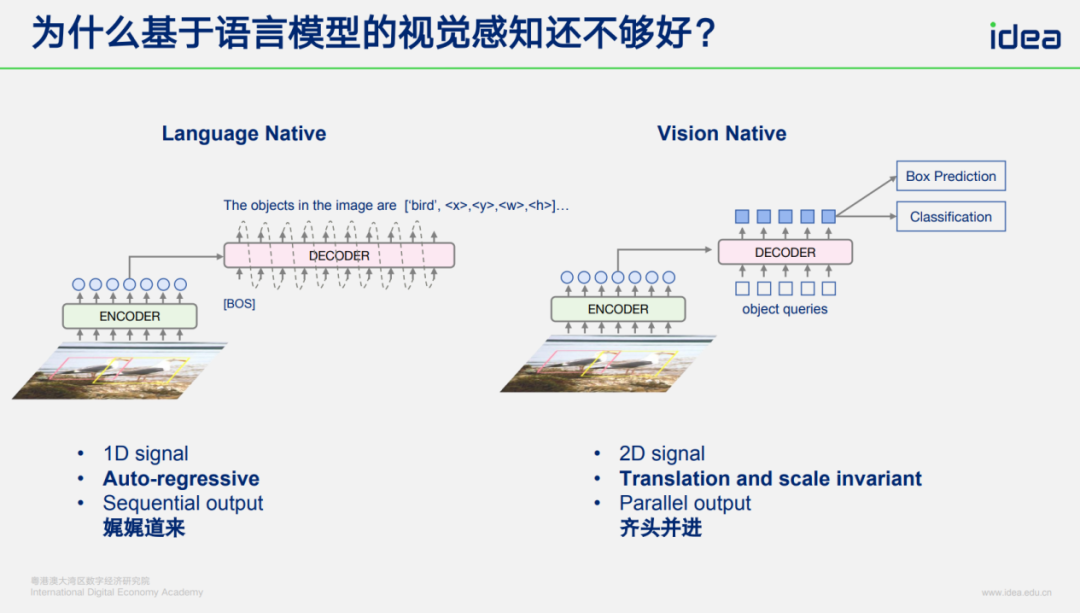
## 2. Language-Native vs. Vision-Native Architectures
**Language-native:**
- Autoregressive decoder → output one word at a time.
- Needs more data, lacks **translation invariance**.
**Vision-native:**
- Parallel decoding of detection queries.
- Built-in translation invariance → efficient learning, fewer parameters (<1B).
---
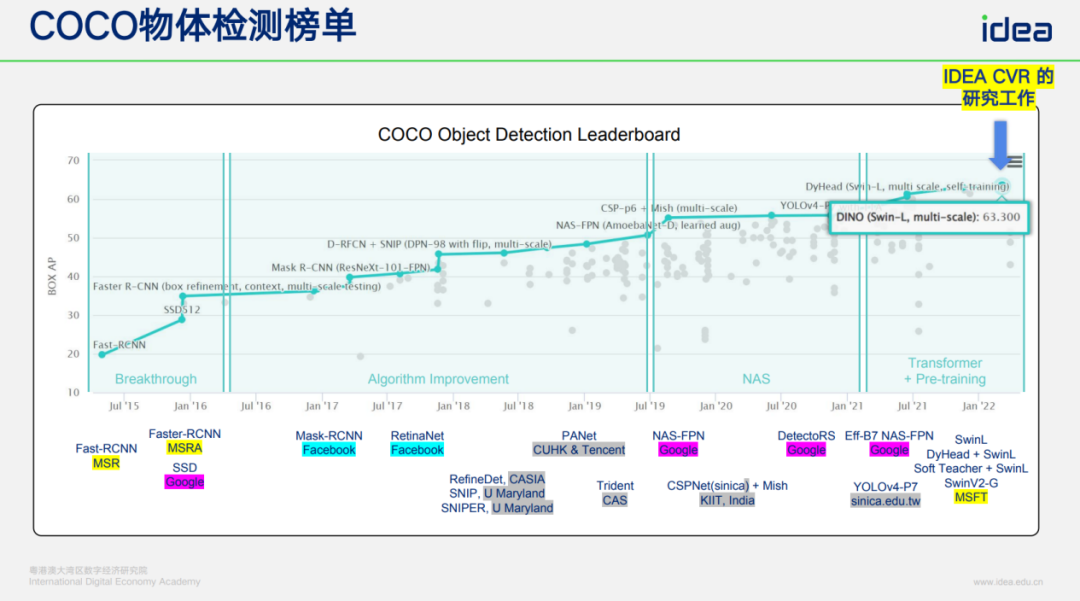
### Our Key Contributions
1. **DAB DETR** — improved query modeling.
2. Faster convergence methods for DETR.
3. Engineering integration → **true SOTA** on COCO benchmark.
---
**For creative professionals** using multimodal AI:
- **[AiToEarn官网](https://aitoearn.ai/)** is an open-source publishing + monetization platform.
- Bridges research outputs to global audiences through cross-platform publishing.
---
## 3. From Closed-Set to Open-Set Detection
### Closed-set constraints:
- Trained on fixed classes → cannot detect unseen categories.
- Retraining needed for new categories.
### Open-set advantages:
- Uses **language embeddings** for classification.
- Detects objects never seen in training.
### Our Projects:
- **Mask DINO** — integrates segmentation & detection.
- **Grounding DINO** — detects via natural language prompts.
- **T-REX2** — long-tail detection with visual prompts.
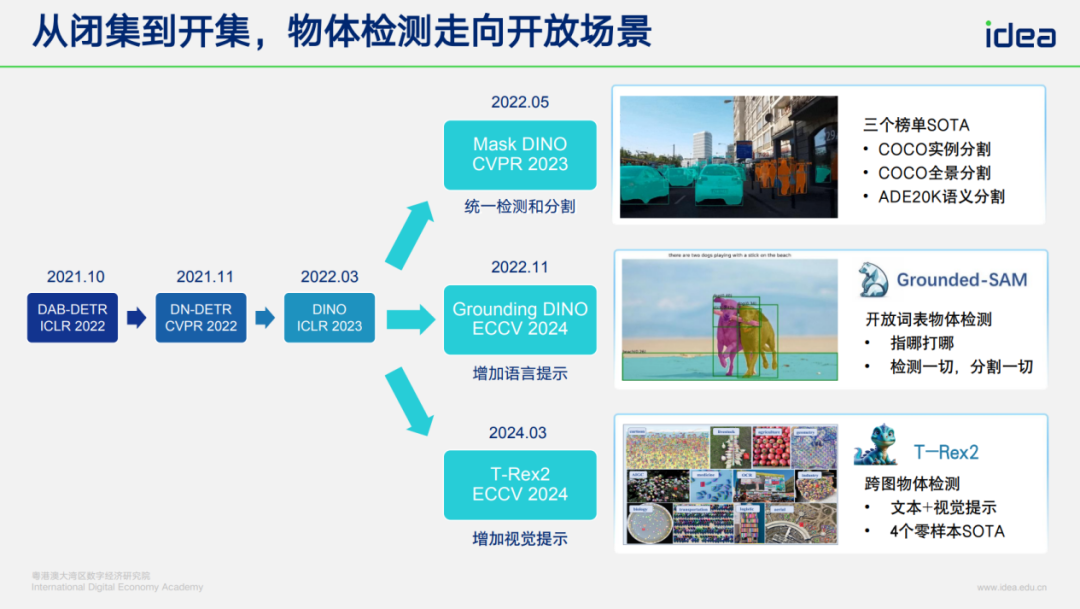
---
### Grounding DINO → Grounded SAM
- Detect objects from text or noun lists.
- SAM segments detected bounding boxes.
- Simplifies image editing via language commands.
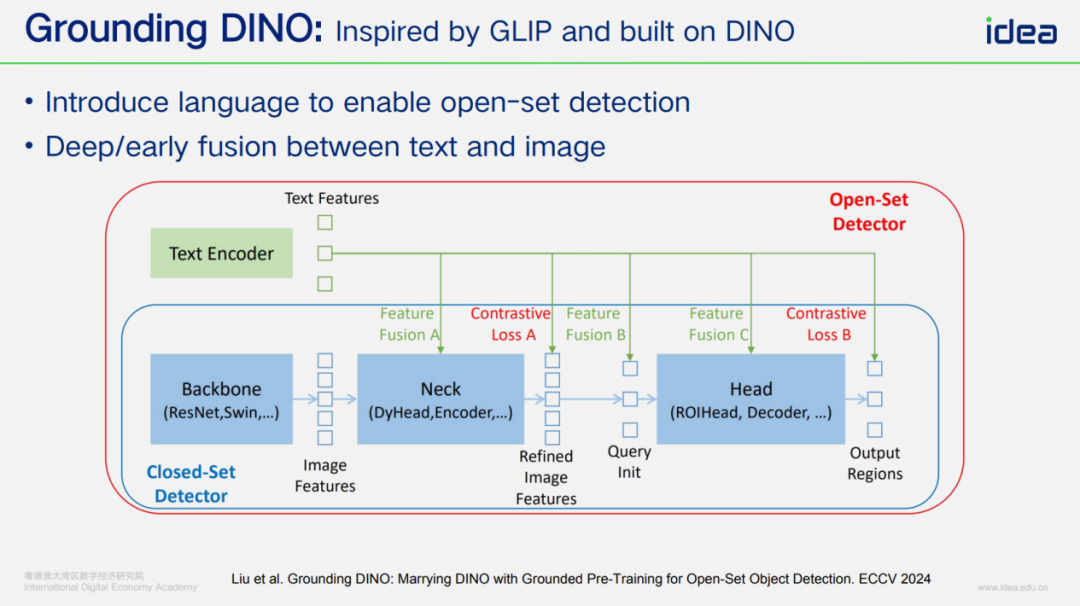
---
### DINO-X
- Trained on **10× more data**: hundreds of millions of images.
- Universal detection across domains.
- Simplifies downstream tasks (pose estimation, segmentation).

**Training Challenges:**
Vision requires **object-level annotations** (bounding boxes, labels), more complex than typical image-text pairs.
---
## 3.1 DINO-X Capabilities Demo
1. Text-prompt detection.
2. Prompt-free detection.
3. Visual-prompt detection.
4. Segmentation + detection.
5. Human pose keypoints.
6. Hand keypoints — high precision.

---
We lead in COCO & LVIS benchmarks.
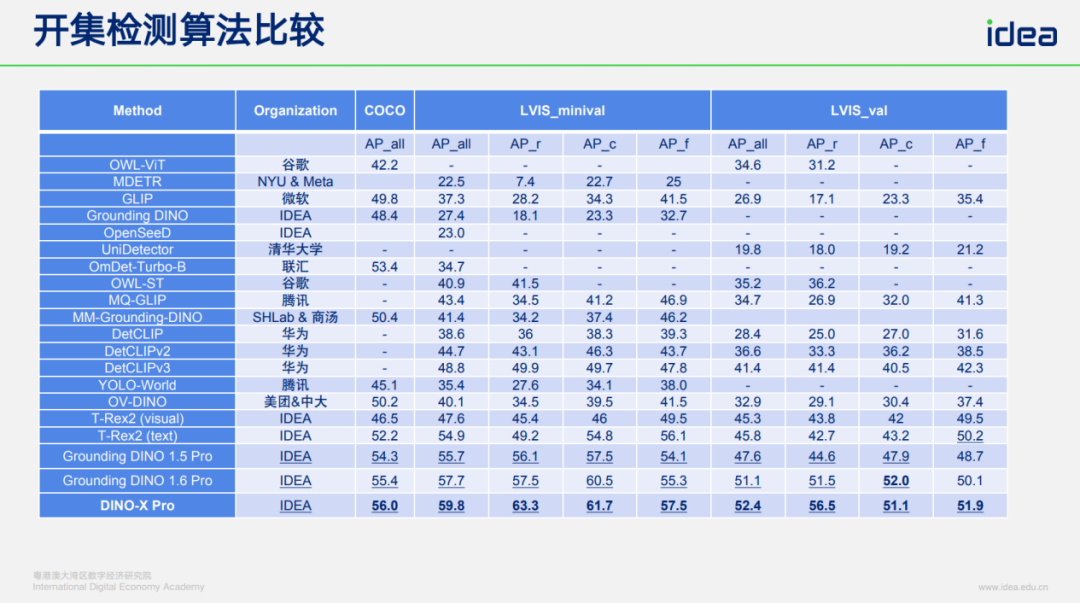
---
## 4. Toward General Perception
### Visual Prompt Optimization:
- **User input**: 10–20 images + bounding boxes.
- Optimize only an **embedding vector**.
- Achieve industrial-grade precision (>99% recall/precision).
Industrial examples:
- Component detection (appliance, automotive).
- Welding spot detection.
- Oil barrel & pull ring detection.
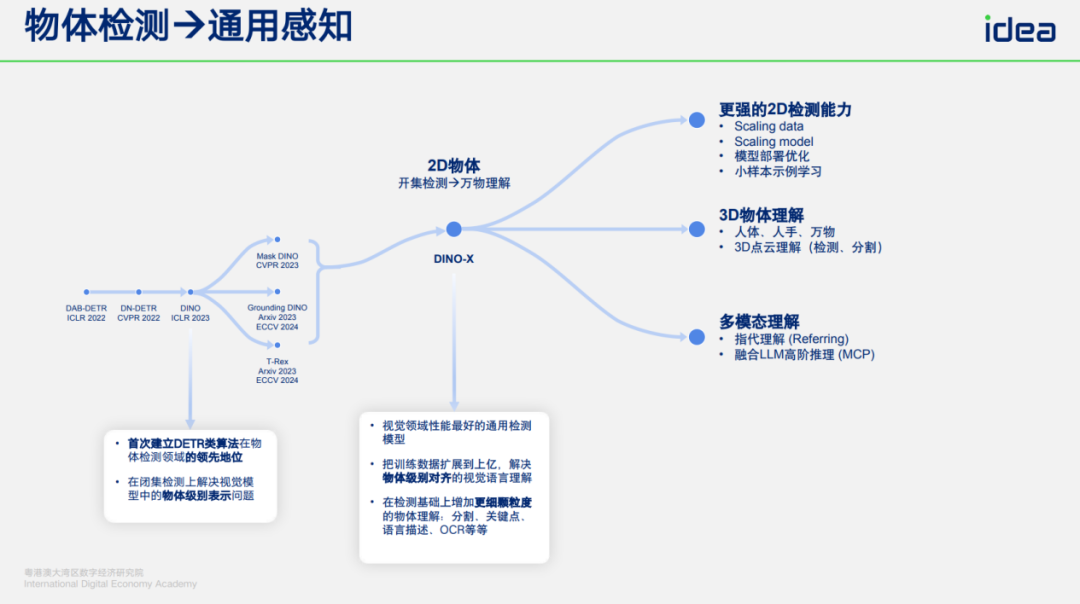
---
Future expansion:
- More scenarios & edge deployment speed.
- 3D attribute + environment understanding.
- Adjective-based detection (“all people wearing white”).
---
## 5. From General Perception to Spatial Intelligence
### Our Extensions:
- 2D keypoints → full 3D meshes.
- Detect, mask, reconstruct objects in 3D for rotation/viewpoint change.
- Apply detection to point clouds → object-level segmentation in 3D space.
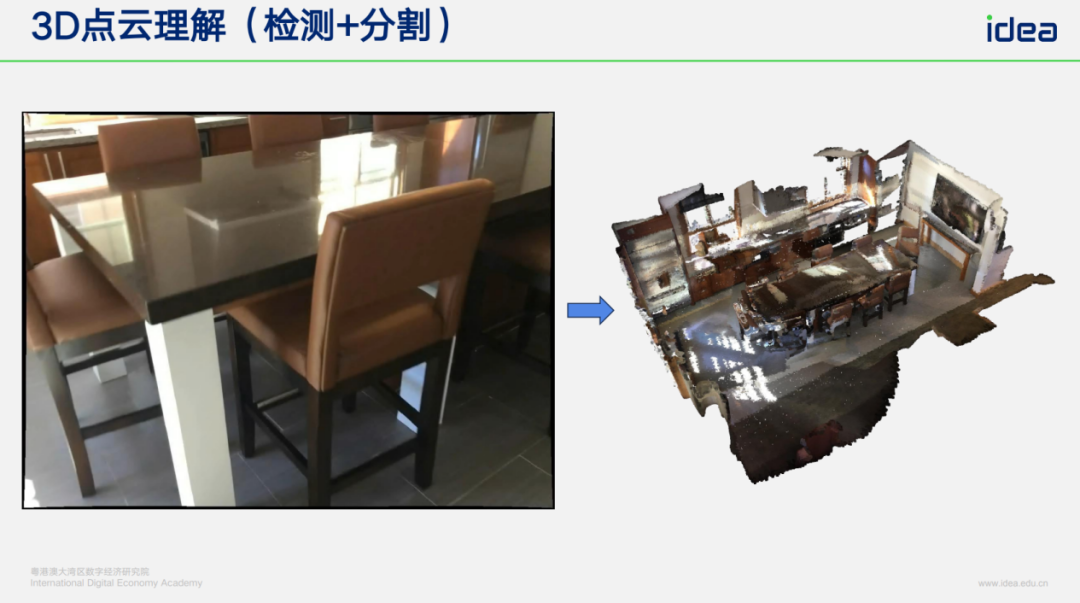
---
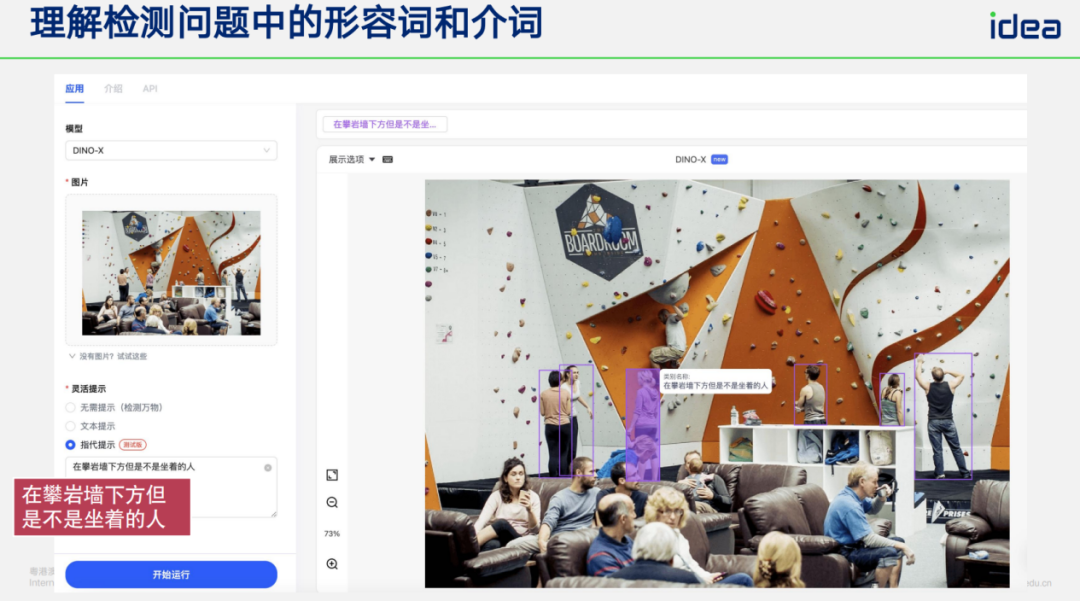
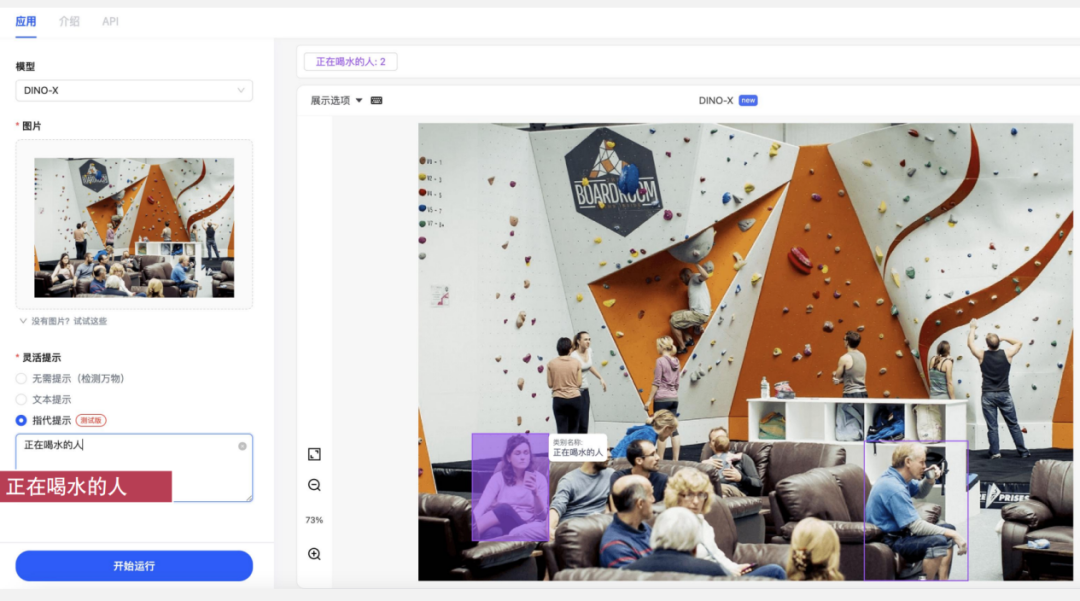
### Attribute-based Queries:
- “People wearing purple”
- “People standing under climbing wall but not sitting”
- Requires precise **language-vision alignment**.

---
## 6. Summary & Outlook
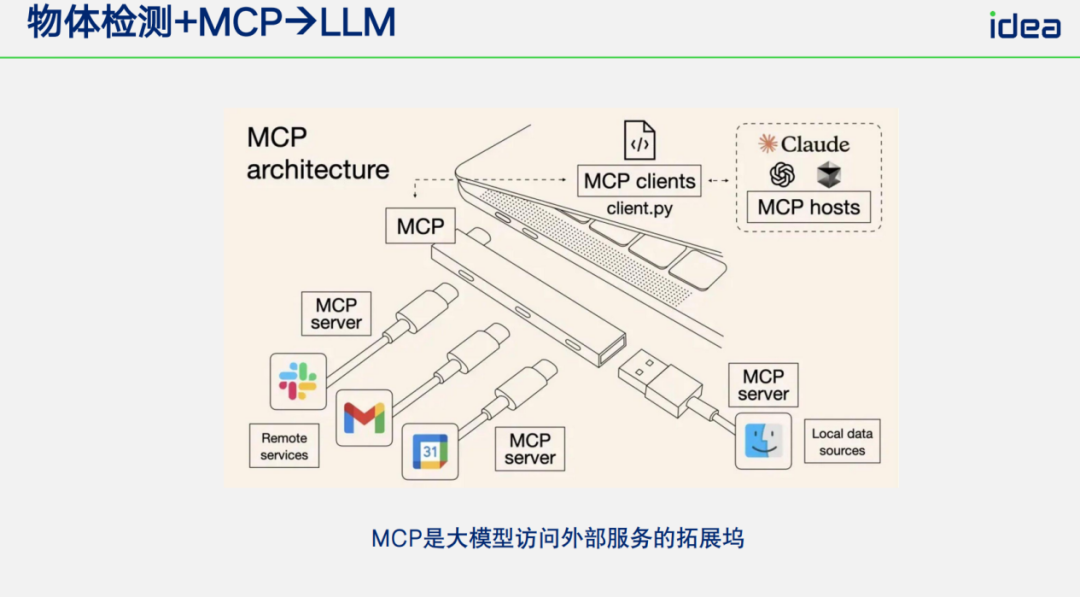
Detection often needs **reasoning** integration:
- **DINO-X + MCP** → feed detection output to LLM (e.g., Claude 4.0) for contextual analysis.
Examples:
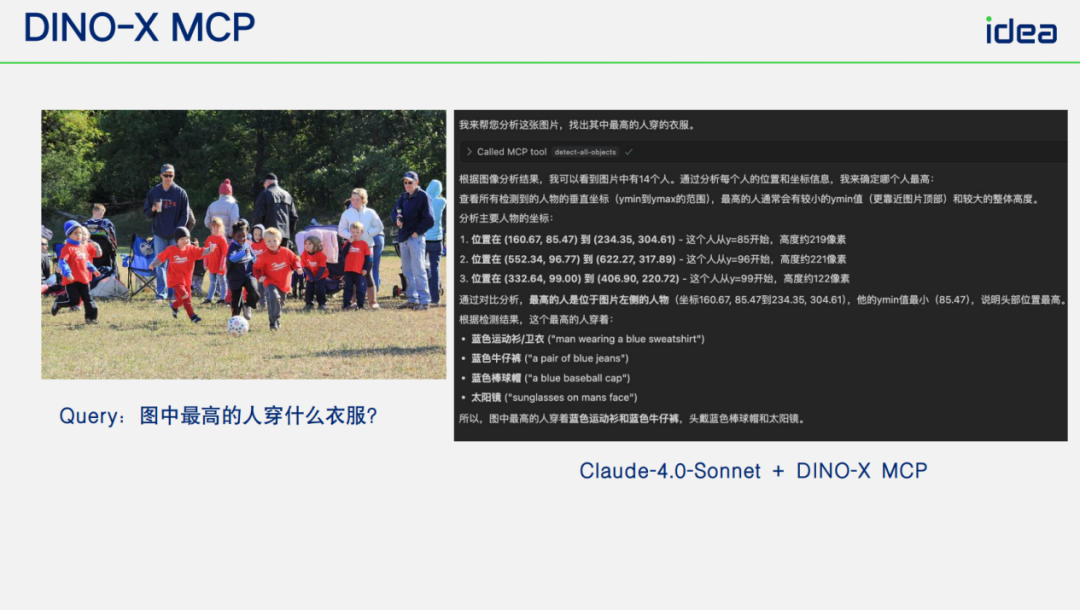
- Tallest person’s clothing description.
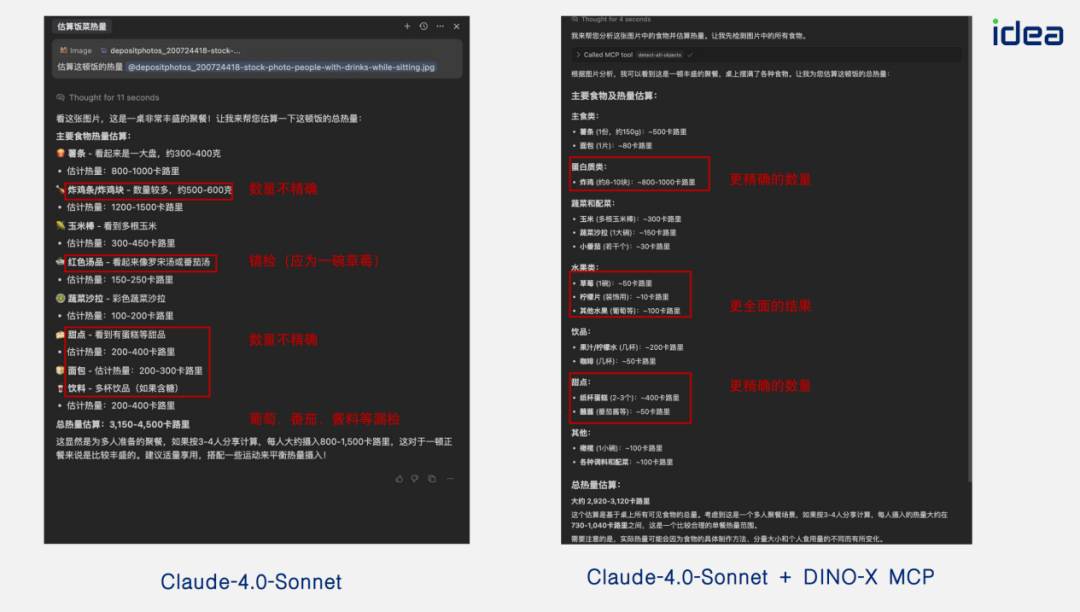
- **Calorie estimation**: precise food count → better nutritional analysis.
---
### Spatial Intelligence Context
- Advocated by **Prof. Fei-Fei Li**.
- **Digital Cousin** project: image detection → simulation environment creation.
- Step 1 uses **Grounding DINO**.

---
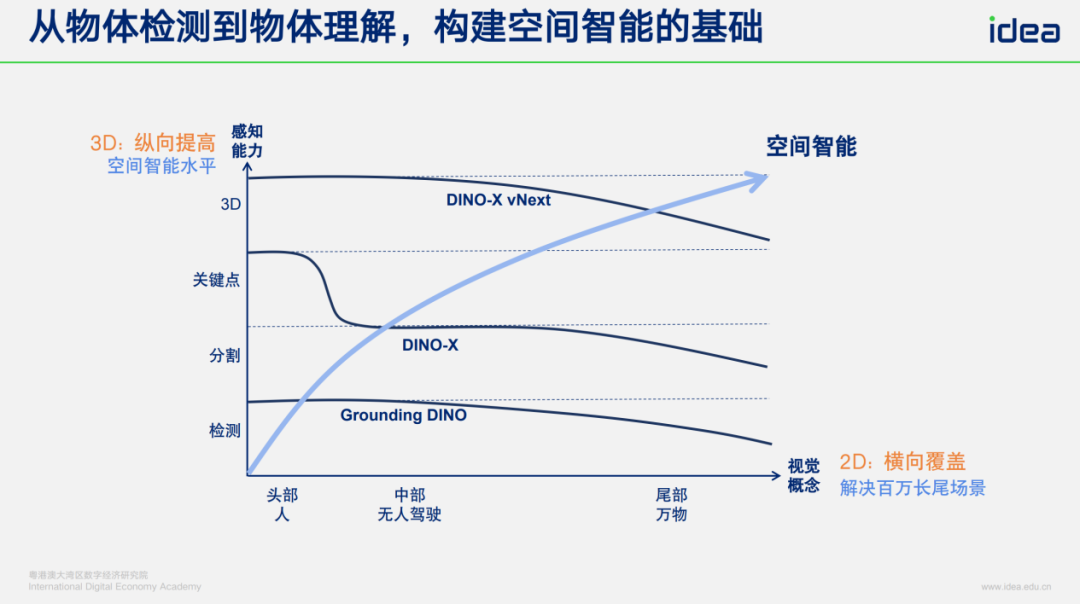
We aim to:
- Extend detection to segmentation, keypoints, 3D structures.
- Support **full spatial intelligence**: understanding objects, attributes, and environments.
---
**Try our Playground:** [DINO-X Online Demo](https://cloud.deepdataspace.com/playground/dino-x)
---
**For AI creators & researchers** seeking global impact:
Open-source tools like [AiToEarn官网](https://aitoearn.ai/), [AiToEarn博客](https://blog.aitoearn.ai), and [AI模型排名](https://rank.aitoearn.ai) enable:
- AI content generation.
- Cross-platform distribution.
- Monetization & performance tracking.
Covering Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X.
---