Google’s Top AI Surpassed by HKUST Open Source? The Image Editing Powerhouse Making Overseas Creators Shout “King Bomb”

Driving Multimodal AI Toward True Generalized Creation

Introduction — The "Photoshop is Dead" Moment
In recent months, "Photoshop is dead" has become a hot topic in the AI creator community.
The explosive growth of image editing and generation models is challenging professional creative software’s long-standing dominance. Multimodal image technology upgrades from Google’s Nano Banana, ByteDance’s Seedream4.0, and Alibaba’s Qwen-Image-Edit-2509 have introduced entirely new capabilities, including:
- OOTD outfit styling
- Text rendering
- Movie storyboard generation
These tools allow creators to focus on controllability, creativity, and product readiness without mastering complex photo-retouching skills.
---
From Innovation to Limitations
While models like Nano Banana combine language understanding, visual recognition, and multimodal instruction control for a natural creative process, some limitations remain:
- Editing prompts can be ambiguous — often needing reference images or extra description
- Generation tasks excel with concrete objects but struggle with abstract concepts (e.g., hairstyles, textures, lighting, artistic styles)
---
DreamOmni2 — A New Benchmark Model
Two weeks ago, Professor Jia Jiaya’s team at HKUST open-sourced DreamOmni2, addressing these weaknesses. Built on FLUX-Kontext, it maintains existing instruction editing and text-to-image abilities, while adding multi-reference image generation editing for greater flexibility.
Key Advantages:
- Superior handling of both concrete and abstract concepts
- Outperforms popular models like Nano Banana in certain scenarios
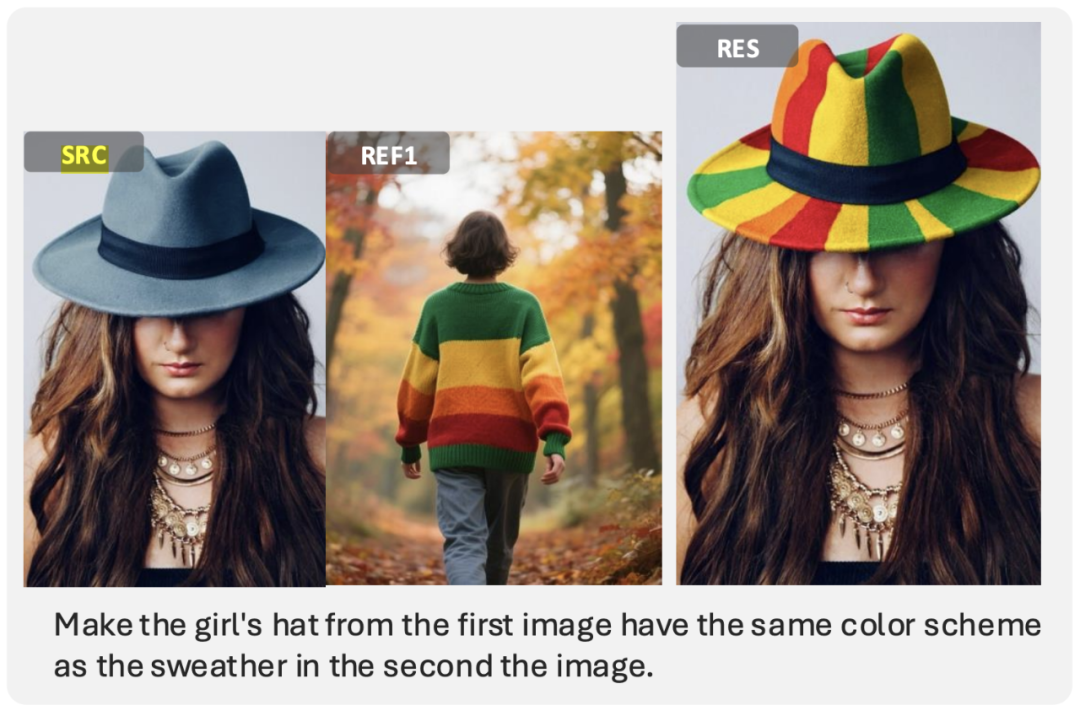
Example — Instruction-Based Editing:
> Change the hat color of the woman in the first image to match the sweater in the second reference image.

Example — Instruction-Based Generation:
> Place image 1 on the bedroom wall, change the cup in image 3 to have the same material as the plate in image 2, and place it on the table.
DreamOmni2 quickly gained traction, amassing 1.6k GitHub Stars in just two weeks.
Repository: https://github.com/dvlab-research/DreamOmni2
---
Hands-On Testing — Where DreamOmni2 Excels
We tested DreamOmni2’s instruction-based multimodal editing and compared it with GPT-4o and Nano Banana.
---
Test 1 — Background Replacement
Prompt:
"Replace the background of the panda in picture 1 with picture 2 to generate an ID photo."

✅ Result: High-quality, fur detail preserved, professional-level output

---
Test 2 — Style Transfer
Prompt:
"Make the first image have the same style as the second image."

✅ Result: Accurate tone, mood, and stylistic integration into original image

---
Test 3 — Clothing Replacement
Prompt:
"Replace the jacket in the first image with the clothes in the second image."
DreamOmni2:

Preserves posture and face; minimal collar differences.
GPT-4o:

Face overly smoothed; awkward proportion changes.
Nano Banana:

Pose intact, but color/shape altered; logo removed.
---
Test 4 — Instruction-Based Multimodal Generation
Example Prompt:
"Print the logo from image 1 on the object from image 2 and place it on a desk."

✅ Result: Accurate logo placement, realistic light/shadow, desk context recognition

---
Test 5 — Pose Transfer from Sketch
Prompt:
"Anime image 1 adopts the pose of image 2"

✅ Result: Captured pose naturally, smooth transformation from lines to motion

---
Test 6 — Necklace on a Cat
Prompt:
"Put the necklace from image 2 on the cat’s neck from image 1"
DreamOmni2:

GPT-4o:

AI artifacts noticeable
Nano Banana:
---
Technical Innovations
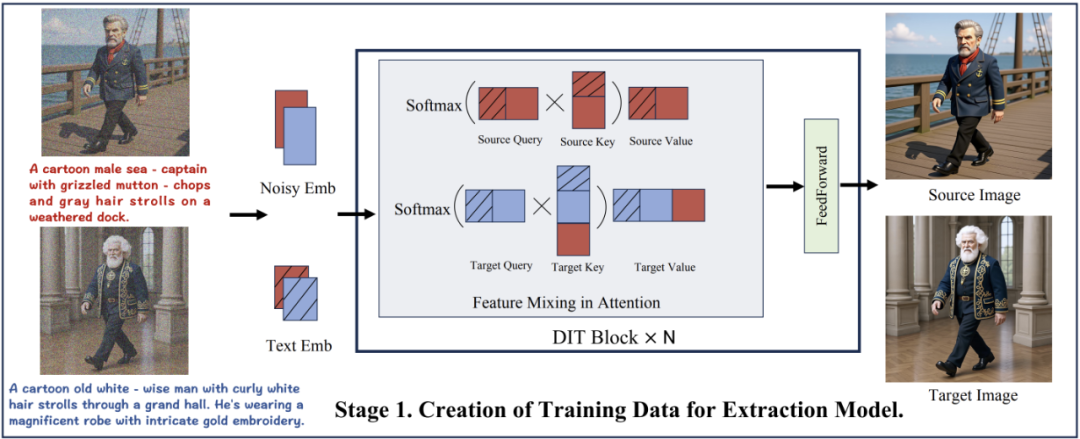
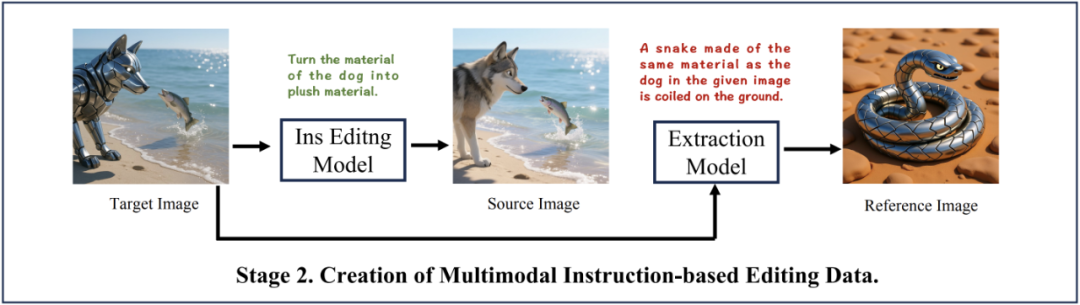
1. Three-Stage Data Construction Paradigm
DreamOmni2 overcomes dataset limitations via:
- Feature Mixing Scheme — Generates high-quality concrete + abstract pairs without resolution loss.
- Instruction-Based Editing Data — Combines real + generated images to create diverse editing examples.
- Instruction-Based Generation Data — Integrates multiple reference images into cohesive datasets.

---
2. Multi-Reference Framework Design
- Uses index encoding with positional offsets to prevent artifacts and confusion between reference images.
---
3. Joint VLM + Generation Model Training
- LoRA modules activate automatically when reference images are detected.
- Improves understanding of non-standard, real-world prompts.
---
Conclusion
DreamOmni2 unifies data, framework, and training to leap forward in multimodal generation/editing.
Advancements vs Previous Models:
- Style transfer and structural reorganization with abstract attribute editing
- Flexible object + concept combination in generation tasks
- Open-source — enabling wide adoption and integration
---
Industry Impact
Platforms like AiToEarn bridge AI creation and monetization.
They integrate:
- AI content generation
- Cross-platform publishing (Douyin, Kwai, Bilibili, Instagram, YouTube, X, etc.)
- Analytics and AI model ranking (AI模型排名)
This fits perfectly with the multimodal creative future enabled by DreamOmni2.
---
References:
---
✔ Final Takeaway:
DreamOmni2 isn’t just an upgrade — it’s a new standard for instruction-based multimodal editing & generation, transforming how creators interact with AI.
---
Do you want me to create a side-by-side visual comparison table for DreamOmni2 vs GPT-4o vs Nano Banana results? That would make the performance differences even clearer.

![Leading Investment in Ilya’s New Company, 13-Year Net IRR of 33%: Greenoaks’ Tech Investment Philosophy | [Matrix Low-Key Share]](/content/images/size/w600/2025/11/img_001-156.jpg)