HAMi × NVIDIA: Detailed Guide to GPU Topology-Aware Scheduling

# HAMi NVIDIA GPU Topology-Aware Scheduling — Design & Code Deep Dive
**Date:** 2025-10-25 13:30 (Zhejiang)
This article explains the **design philosophy**, **core principles**, and **code implementation** of HAMi’s new **topology-aware scheduling** capability for NVIDIA GPUs in version `v2.7.0`. We focus on how HAMi intelligently schedules GPU workloads in **HPC** and **large AI model training** scenarios to minimize communication bottlenecks and maximize cluster efficiency.
---
## Introduction


HAMi is an active **open-source project** maintained by over **350 contributors** from more than **15 countries**. Adopted by over **200 enterprises**, it is known for **scalability** and **production-grade stability**.
The `v2.7.0` release brings **topology-aware scheduling** for NVIDIA GPUs, allowing workloads to be deployed to GPU groups with the **closest physical connections** (e.g., NVLink, PCIe) and **fastest communication speeds**.
---
## Key Features
- **Dynamic topology scoring**:
Device Plugin uses **NVML** to detect GPU physical topology and converts it into **numeric communication scores**.
- **Dual-strategy anti-fragmentation scheduling**:
- **Best match** for multi-GPU tasks, maximizing inter-GPU communication efficiency.
- **Minimal disruption** for single-GPU tasks, preserving topology for future workloads.
---
## Core Principles
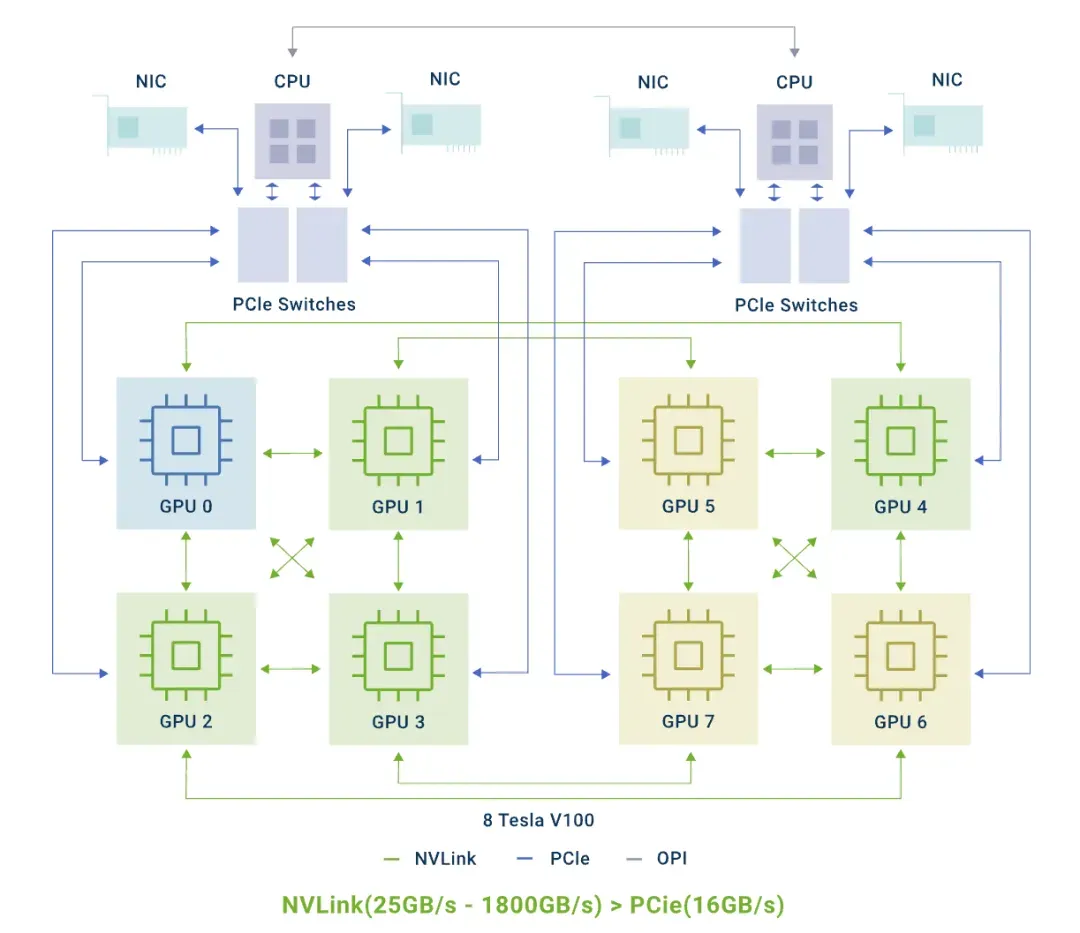
HAMi scheduling consists of two main stages:
### **Stage 1: Topology Registration**
Transform invisible hardware topology into quantifiable scores:
1. **Detect connection types** between GPU pairs (`NVLink`, `PCIe`) via NVML.
2. **Model the topology graph** for all devices on a node.
3. **Assign scores** using rules (e.g., `SingleNVLINKLink` = 100, `P2PLinkCrossCPU` = 10).
4. **Create a device score table** and register it in **node annotations**.
### **Stage 2: Scheduling Decision**
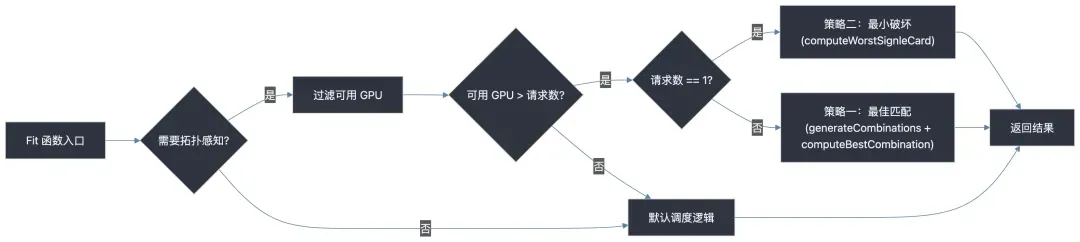
Use the score table in the `Fit()` function to choose optimal GPUs:
1. **Filter** GPUs by resource requirements.
2. **Score & optimize**:
- For **multi-GPU**: select the highest total communication score.
- For **single-GPU**: select the least-connected GPU to reduce topology impact.
---
## Principle Implementation — Code Analysis
### 1. **Topology Discovery & Score Calculation**
#### Build the Topology Graph
File: `pkg/device/nvidia/calculate_score.go`
- **Initialize device list** with empty `Links` maps.
- **Populate links**:
- `GetP2PLink` and `GetNVLink` detect interconnects.
- Store connections as `P2PLink` objects in each device’s `Links`.
#### Quantify to Scores
Function: `calculateGPUPairScore`
- Sum scores for all links between two GPUs using a `switch` statement.
func (o *deviceListBuilder) build() (DeviceList, error) {
var devices DeviceList
for i, d := range nvmlDevices {
devices = append(devices, device)
}
for i, d1 := range nvmlDevices {
for j, d2 := range nvmlDevices {
if i != j {
p2plink, _ := GetP2PLink(d1, d2)
devices[i].Links[j] = append(
devices[i].Links[j], P2PLink{devices[j], p2plink},
)
nvlink, _ := GetNVLink(d1, d2)
devices[i].Links[j] = append(
devices[i].Links[j], P2PLink{devices[j], nvlink},
)
}
}
}
return devices, nil
}
func calculateGPUPairScore(gpu0 Device, gpu1 Device) int {
score := 0
for _, link := range gpu0.Links[gpu1.Index] {
switch link.Type {
case P2PLinkCrossCPU:
score += 10
case SingleNVLINKLink:
score += 100
// ...
}
}
return score
}
---
### 2. **Device-side Scheduling Decision**
File: `pkg/device/nvidia/device.go`
- Check if **topology-aware policy** is requested.
- Apply appropriate strategy:
func (nv *NvidiaGPUDevices) Fit(...) {
needTopology := util.GetGPUSchedulerPolicyByPod(...) == util.GPUSchedulerPolicyTopology.String()
// Filter idle GPUs: tmpDevs
if needTopology {
if len(tmpDevs[k.Type]) > int(originReq) {
if originReq == 1 {
lowestDevices := computeWorstSignleCard(nodeInfo, request, tmpDevs)
tmpDevs[k.Type] = lowestDevices
} else {
combinations := generateCombinations(request, tmpDevs)
combination := computeBestCombination(nodeInfo, combinations)
tmpDevs[k.Type] = combination
}
return true, tmpDevs, ""
}
}
}
---
## Fit Function Strategies
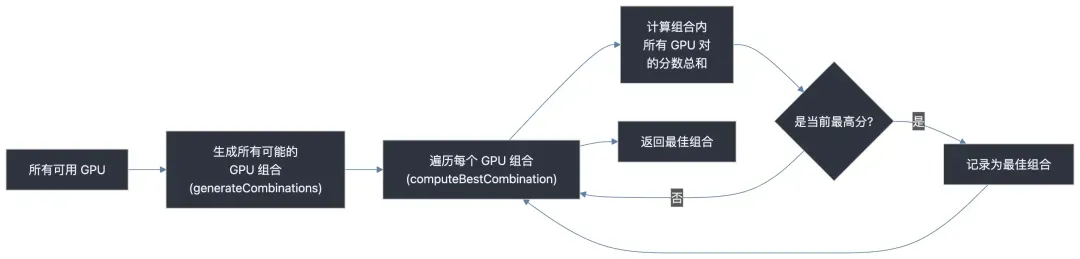
### **Strategy 1: Best Match (Multi-GPU)**
- Enumerate all combinations via `generateCombinations`.
- Select the one with **maximum total communication score** using `computeBestCombination`.
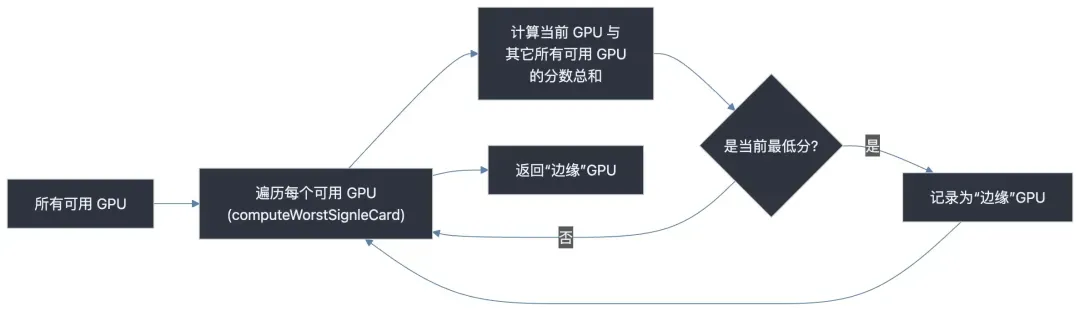
### **Strategy 2: Minimal Disruption (Single-GPU)**
- Use `computeWorstSignleCard` to find the least-connected GPU.
- Preserves topology for future larger jobs.
---
## Usage Example
Enable topology-aware scheduling with an **annotation**:
apiVersion: v1
kind: Pod
metadata:
name: gpu-topology-aware-job
annotations:
hami.io/gpu-scheduler-policy: "topology-aware"
spec:
containers:
- name: cuda-container
- image: nvidia/cuda:11.6.2-base-ubuntu20.04
- command: ["sleep", "infinity"]
- resources:
- limits:
- hami.io/gpu: "4"
---
## Summary
HAMi’s **dynamic discovery + dual optimization** approach:
- Best performance for current workloads.
- Long-term cluster topology health.
- Essential for **large-scale AI training** and **HPC workloads**.
---
## References
- [HAMi NVIDIA GPU Topology Policy Proposal](https://github.com/Project-HAMi/HAMi/blob/master/docs/proposals/gpu-topo-policy.md)
- [NVIDIA GPU Topology Scheduler Guide](https://github.com/Project-HAMi/HAMi/blob/master/docs/proposals/nvidia-gpu-topology-scheduler.md)
- Relevant PRs: [#1018](https://github.com/Project-HAMi/HAMi/pull/1018), [#1276](https://github.com/Project-HAMi/HAMi/pull/1276)
---
## Upcoming Event: **AICon 2025 — Beijing**
**Date:** December 19–20
Topics: Agents, Context Engineering, AI product innovation, and more.

---
## Recommended Reads
- [Mass Layoffs at Meta — Yuandong Tian Laid Off?!](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247647159&idx=1&sn=a9e0e5d10801f5a2caddaaee0b68c12b&scene=21#wechat_redirect)
- [AI Coding Assistant Price Jump](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247646785&idx=1&sn=d3dd267adf24e14e7354c3070ad5ccf4&scene=21#wechat_redirect)
- [Claude Skills vs MCP Debate](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247646684&idx=1&sn=19a88396cba9448d1a7e5fe2ff21e96e&scene=21#wechat_redirect)
- [Anthropic’s New Model Benchmarks](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247646628&idx=1&sn=679b13baf56bc6e09ddda0dfea43b0ad&scene=21#wechat_redirect)
- [Karpathy’s Custom ChatGPT Project](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247646486&idx=1&sn=159d276bb43b24d898b91fa03d8867c2&scene=21#wechat_redirect)

[Read the original](2247647314)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=73ec7c06&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzU1NDA4NjU2MA%3D%3D%26mid%3D2247647314%26idx%3D2%26sn%3D416fdac6b4e9a5d4dc075c6628aff2f4)
---

