Handcrafted 1,000-Line Java OpenAI gpt-oss Inference Engine

# OpenAI **gpt-oss** — Java CPU Inference Implementation & Performance Optimization
In **August 2025**, OpenAI released **gpt-oss**, marking its first **open-weights model** since GPT‑2 — with **120B** and **20B** parameter reasoning models.


---
## 1. Release Overview
The **gpt-oss** launch continued OpenAI's openness tradition, providing the weight files for both model sizes. Built for **advanced reasoning**, the models immediately gained wide support from:
- **Cloud providers**: AWS, GCP
- **Inference engines**: Ollama, LM Studio, vLLM, Transformers, TensorRT‑LLM
Inspired by **llama.cpp** and **llama2.c**, and curious about **LLM internals**, I ported the inference engine to **Java** for pure CPU execution.
Within ~1,000 lines of Java code ([GitHub: gpt-oss.java](https://github.com/amzn/gpt-oss.java)), I built a compact, high‑performance CPU‑only engine — now published on Amazon’s official GitHub.
---
## 2. Model Architecture Summary
The **gpt-oss** architecture adheres to mainstream design with efficiency‑focused choices:
- **Tokenization**: [`tiktoken`](https://github.com/openai/tiktoken)
- **Architecture**: Decode‑only Mixture‑of‑Experts (MoE)
- **Position Encoding**: Rotary Position Embedding (RoPE)
- **Normalization**: RMSNorm
- **Attention Layer**: Grouped Query Attention (GQA)
- **Attention Strategy**: Mix of Sliding Window and full‑context attention
- **MLP**:
- MoE with expert selection per forward pass
- SwiGLU activation
- **Quantization**: `mxfp4` (20B weights ≈ 13 GB)
**Performance envelope**:
- 120B runs on a single 80 GB GPU
- 20B runs on a single 16 GB GPU
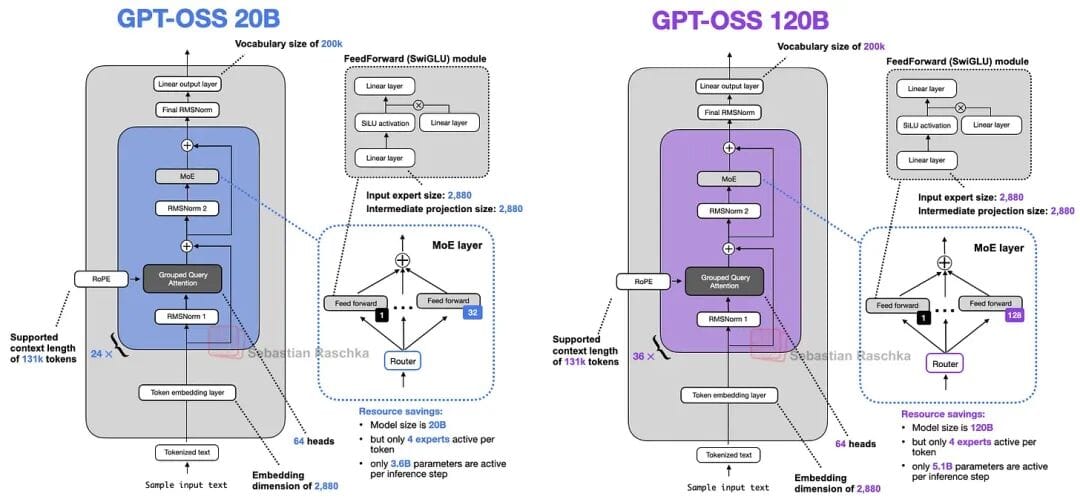
*Diagram from Sebastian Raschka — summarizing LLM architecture evolution since GPT‑2.*
---
## 3. Java Inference Engine Design
Porting from PyTorch’s `model.py` meant rewriting:
### Core Modules
- **Model loader**: Reads `.safetensors` weights
- **Math operators**: `matmul`, RMSNorm, `softmax`
- **Attention block**:
- QKV computation
- GQA attention
- Sliding window + multi-head SDPA
- RoPE
### MLP Block
- Expert routing
- SwiGLU activation
- Projection layers
> **Sampling**: Currently only temperature-based — no top‑p or repetition penalty.
---
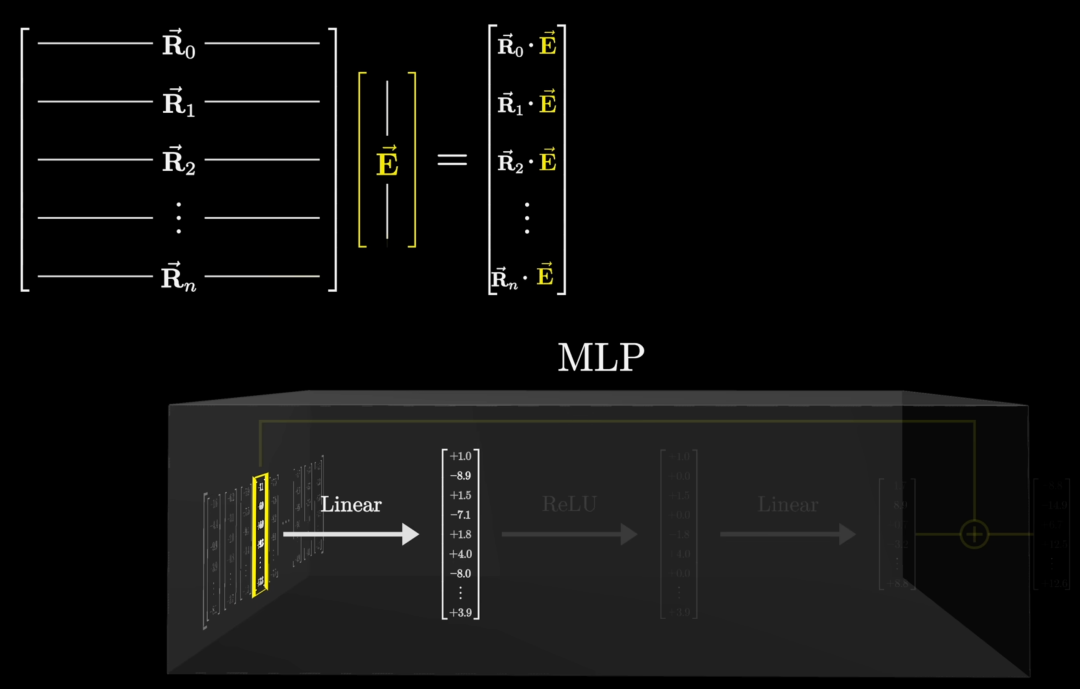
## 4. MXFP4 Quantized Computation
Model weights store MLP parameters in **mxfp4** with `u8` block scaling; others in `bf16`.
This is critical for inference efficiency but requires unpacking to FP32 for CPU math.
### Heavy Compute Example — MLP Up Projection (20B)
1. **Input**: 2880‑D vector → RMSNorm
2. **Expert selection**: 4 of 32 experts per layer
3. **Matrix multiply**: 2880‑D × `[5760×2880]` expert matrix
4. **Data layout**: Columns stored as `[90,16]` U8 tensor (pairs of 4-bit values)
On CPU, SIMD assists in nibble extraction & LUT mapping:
MXFP4_VALUES = {
+0.0f, +0.5f, +1.0f, +1.5f, +2.0f, +3.0f, +4.0f, +6.0f,
-0.0f, -0.5f, -1.0f, -1.5f, -2.0f, -3.0f, -4.0f, -6.0f
};
Java’s **Project Panama Vector API** enables parallel LUT lookups & FMA operations, combined with multi-threading.
---
## 5. Performance Optimization Techniques
Initial **PyTorch decode speed**: ~0.04 tokens/s on AWS m5.4xlarge.
Optimized Java decode: ~7 tokens/s; prefill: ~10 tokens/s.
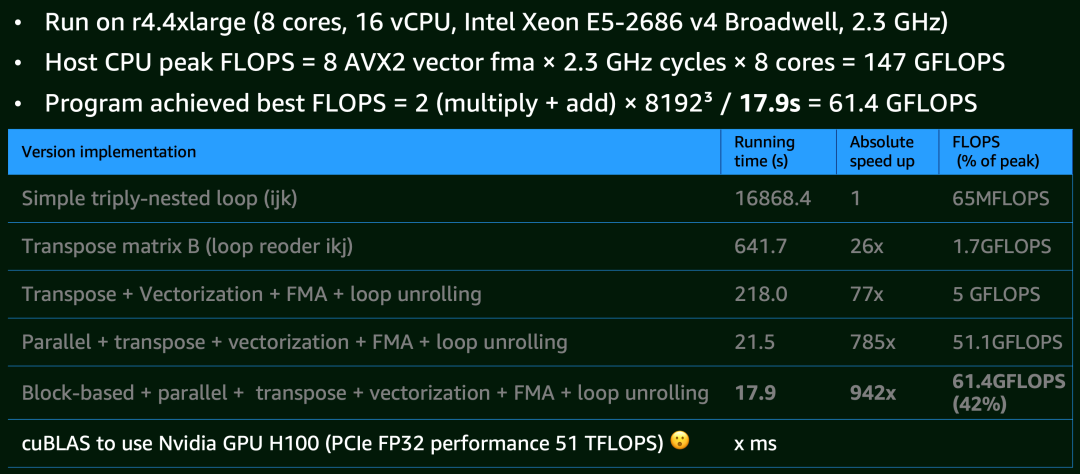
### 5.1 Matrix Multiplication
Experiments (8k×8k matmul on m4.4xlarge):
| Optimization Stage | Speed-up vs Baseline |
|------------------------------|----------------------|
| **Baseline** (triple loop) | 1× |
| Cache locality + transpose | 26× |
| SIMD + loop unrolling ×4 | 77× |
| Multi-core (16 vCPUs) | 785× |
| Block/tile computation | 942× (≈42% HW peak) |
> Even GPU (cuBLAS on H100) reaches **51 TFLOPS**, 1000× CPU FP32 throughput.
---
### 5.2 Parallel Computing
- Matrix multiplications
- GQA dot products
- MLP experts processed concurrently
---
### 5.3 Memory Mapping
- **mmap** MLP weights via Java Foreign Memory API
- RAM requirement: 16 GB
- Larger RAM improves OS *Page Cache* hit rate
---
### 5.4 Reduce Memory Copies
- Direct SIMD loads from mmap segments
- Pre-allocate intermediate buffers for **GC-less** computation
---
### 5.5 Operator Fusion
- Combine operators to reduce data transfers
- Applied selectively for clarity
---
### 5.6 KV Caching
- Pre‑allocated KV cache sized to `max_tokens`
- GQA dramatically cuts memory usage
---
## 6. Performance Results
| Environment | Decode (tokens/s) | Prefill (tokens/s) |
|----------------------|-------------------|--------------------|
| **Mac M3 Pro** | 8.7 | 11.8 |
| **AWS m5.4xlarge** | 6.8 | 10 |
Java performance > PyTorch & HuggingFace baseline, but < `llama.cpp` (GGUF v3 mxfp4, 16.6 tokens/s, due to deeper low-level optimizations).
---
## 7. Implementation Insights
- Achieved full PyTorch parity in ~1,000 Java LOC
- Modular architecture = easier port
- Runs on desktop or EC2
- Java optimization possibilities:
- **Leyden** (startup)
- **Lilliput** (object size)
- **Loom** (virtual threads)
- **Panama** (native bridge)
- **Valhalla** (compact objects)
- **ZGC** & **AOT**
- Proven ~95% of O3 C performance in prior LLM ports
---
## 8. AI Content Pipelines & Monetization
For developers combining **optimized inference** with content creation, platforms like **[AiToEarn官网](https://aitoearn.ai/)** can connect model output to instant multi‑platform publishing:
- Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter
- Analytics, AI model ranking ([AI模型排名](https://rank.aitoearn.ai))
- Open-source integrations ([GitHub](https://github.com/yikart/AiToEarn), [Docs](https://docs.aitoearn.ai))

---
## 9. Recommended Articles
- [Meta’s massive layoffs — Yuandong Tian let go; Scale AI hiring aggressively](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247647159&idx=1&sn=a9e0e5d10801f5a2caddaaee0b68c12b&scene=21#wechat_redirect)
- [Flagship AI coding assistant price hike ×10; CEO defends sustainability](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247646785&idx=1&sn=d3dd267adf24e14e7354c3070ad5ccf4&scene=21#wechat_redirect)
- [Claude Skills are great — possibly more important than MCP](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247646684&idx=1&sn=19a88396cba9448d1a7e5fe2ff21e96e&scene=21#wechat_redirect)
- [Anthropic’s new model: 2/3 cost cut, GPT‑5‑level performance, 3.5× faster Sonnet](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247646628&idx=1&sn=679b13baf56bc6e09ddda0dfea43b0ad&scene=21#wechat_redirect)
- [Custom ChatGPT in 4h — Karpathy hand-coded 8k lines; netizens joke “ML engineer certified”](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247646486&idx=1&sn=159d276bb43b24d898b91fa03d8867c2&scene=21#wechat_redirect)

---
## 10. Links
[Read the full article](2247647248)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=8a0274c9&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzU1NDA4NjU2MA%3D%3D%26mid%3D2247647248%26idx%3D2%26sn%3D984bbee78a8dea553064935ff674b25b)
---
**For creators**:
[AiToEarn博客](https://blog.aitoearn.ai) | [AiToEarn文档](https://docs.aitoearn.ai) | [AiToEarn开源地址](https://github.com/yikart/AiToEarn)

