Hands-on Test of Meituan’s First Video Foundation Model: Native 5-Minute Photorealistic Long Video Output

Meituan Launches LongCat-Video — Their First AI Video Model

On Monday, Meituan unveiled its first AI video model, LongCat-Video.
With 13.6B parameters, a single model can handle:
- Text-to-video
- Image-to-video
- Video continuation
- Ultra-long video generation
Output: 720p, 30fps.
Since my own hardware couldn’t handle full-scale testing, I reached out to Meituan’s LongCat team for internal testing access.
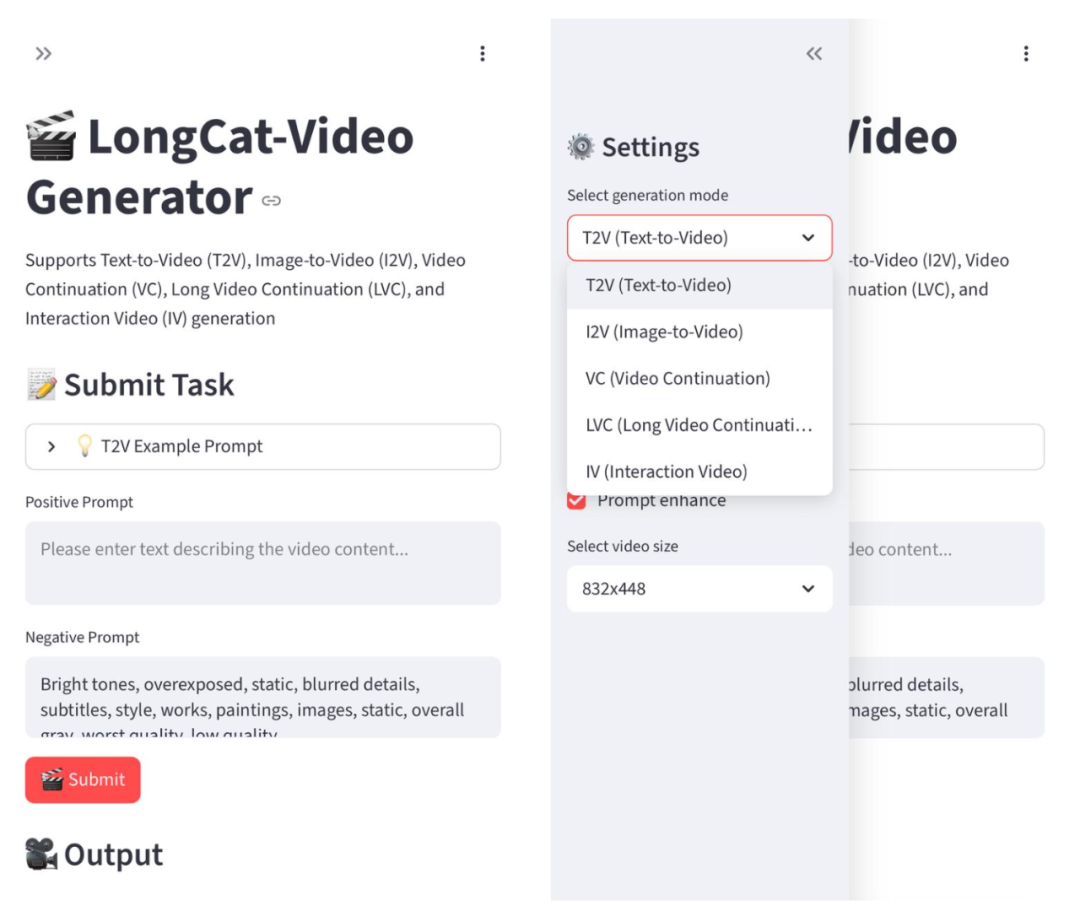
In this article, you’ll see authentic LongCat-Video results — including whether it can generate a 5-minute continuous video without breaking, and what’s behind Meituan’s interest in AI video.
> Spoiler: My impression is that LongCat-Video’s main pursuit is realism.
---
Can You Spot the Switch to AI?
In the example clip below, try guessing the exact second the scene turns AI-generated.
Answer: Just after the 2-second mark — everything beyond that point is AI.
The model doesn’t just copy the motion; it preserves the bicycle’s speed, environment, and fluid movement, making the transition nearly invisible to the untrained eye.
LongCat-Video thrives with first-person journey footage — even generating full 5-minute rides with smooth, natural progression.
---
"World Model" Approach
The LongCat-Video team frames their model as a world model.
Typical video models
→ Focus on visual variety, artistic styles, and dramatic scene shifts.
World models
→ Aim to understand the dynamics, physical laws, and cause-effect relationships of reality.
Industry Context
At NVIDIA GTC, the world model concept was front and center — enabling applications like:
- Simulating traffic patterns, road conditions, weather, lighting for autonomous driving
- Providing spatial intelligence for robotics
- Analyzing crowd movement for transit planning
In essence, a world model is not a film generator — it’s a predictive simulator of the real world.
---
Putting Physical Reality to the Test
Since LongCat-Video aims to model the Newtonian world, I designed prompts to test cause-effect understanding.
1. Skateboard Ollie
- Prompt: "Ollie" — no extra instructions.
- Result: Smooth jump and landing, realistic skater–board dynamics.
- Minor flaw: Slight board distortion during spin.
2. Mukbang Eating Video
- Food is visibly consumed — the portion on the plate shrinks as it enters the mouth.
- Facial expressions match the action.
- Area to improve: Softer lighting and higher sharpness control.
3. Talking-Head Explainer
- Checked lip-sync, blinking, and hand gestures.
- No repetitive mouth loops for a full minute.
- Small detail: Perfume bottle liquid moved subtly as it was shaken — event fidelity was high.
---
First Impressions
LongCat-Video’s “worldview” is accurate yet minimalist.
- It can’t match Sora’s cinematic grandeur, but
- It can faithfully recreate common real-world sequences
- For Meituan, this realism is more valuable than spectacle
---
Technical Deep-Dive: Why 5-Minute Clips Work

1. Video Continuation Pretraining
- The model trains not on isolated frames but on continuous sequences.
- It learns to predict “what comes next” instead of “what does the next frame look like.”
2. Event-Based Understanding
- Instead of a frame-by-frame mental model, it reasons event-by-event.
3. Block-Causal Attention
- Special attention mechanism enabling long, uninterrupted action generation.
- Avoids abrupt breaks in the video.
4. Caching Unchanged Elements
- Static backgrounds (e.g., a building) aren’t recalculated every frame.
- Cuts computation → Enables genuine 5-minute continuous generation.
---
Meituan’s Rationale for a World Model
Video models are splitting into two categories:
- Content Creation Tools — Maximize visual storytelling and diverse aesthetics.
- World Models — Prioritize simulation, prediction, and physical accuracy.
For Meituan, a world model provides direct business intelligence:
- Predict traffic congestion down to exact intersections and times.
- Estimate extra delay for a delivery rider during heavy rain or road flooding.
- Simulate wind effects on battery life and drone stability.
---
Potential Real-World Simulations
Imagine LongCat-Video enhanced with Meituan’s operational data:
- Evening rush hour from Guomao to Wangjing
- Optimal storm delivery routes
- Elevator traffic patterns during office lunch peak
When a video model understands our physical world this deeply,
It stops being just a creator’s tool — it becomes infrastructure.
---
Monetizing AI-Generated Simulations
As video models shift from flashy visuals to real-world fidelity, there’s also room to monetize simulation-driven content.
A notable open-source option: AiToEarn
- Global AI content monetization platform
- Integrates AI generation, publishing, and earnings
- One-click multi-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Offers analytics & model rankings
Links: AiToEarn官网 | AiToEarn博客 | AiToEarn开源地址
---
Final Thoughts
Meituan is betting big on AI video not as a creative gimmick, but as a predictive simulation engine.
If they succeed in fusing their real-world logistics data with LongCat-Video’s world modeling,
we could see AI simulations influencing urban planning, delivery optimization, and real-time decision-making — while also creating new monetization channels for simulation-based storytelling.
---
Do you want me to prepare a side-by-side comparison table of LongCat-Video vs. other video models like OpenAI Sora to make their differences more visually clear? That could make this review even more actionable for tech readers.