Higher IQ, Faster Thinking! Ant Open-Sources Latest Trillion-Parameter Language Model with Multiple Complex Reasoning SOTAs
Ant Group Releases Trillion-Parameter Ling-1T Model
Another trillion-parameter-level Chinese open-source model has arrived!
Just moments ago, Ant Group officially unveiled the first flagship model in its BaiLing series: Ling‑1T, a general-purpose language model with 1 trillion parameters.
---
Key Highlights at Launch
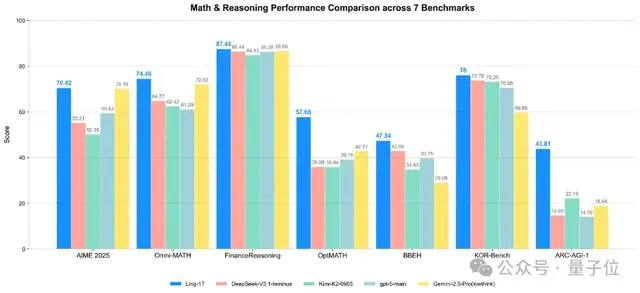
- Outperforms top open-source models — DeepSeek‑V3.1‑Terminus, Kimi‑K2‑Instruct‑0905
- Beats notable closed-source models — GPT‑5‑main, Gemini‑2.5‑Pro
- Achieves SOTA (State of the Art) under limited output tokens in:
- Code generation
- Software development
- Competition-level mathematics
- Professional mathematics
- Logical reasoning
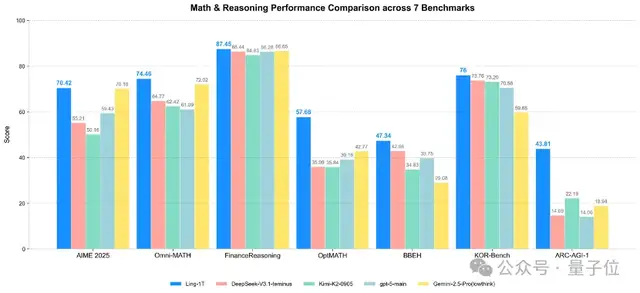
Ling‑1T also excelled in efficient thinking and precise reasoning — topping the AIME 25 competition mathematics leaderboard.
---
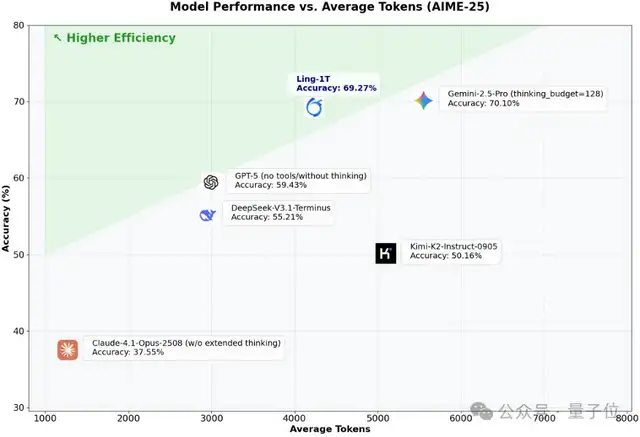
Remarkable Inference Speed
Ling‑1T begins reasoning immediately upon receiving input, delivering:
- Complex logical deductions
- Multi-turn, long-text generation
- Fast responses with smooth output
---
Hands-On Reasoning Tests
Test 1: Spatial Geometry Problem
> Let a 7-meter-long sugarcane pass through a door that is 2 meters high and 1 meter wide.
- Problem Identification: Classic spatial geometry optimization
- Obstacle Analysis

- Solution Proposals — four possible methods, each with concrete steps

- Feasibility Validation — physical conditions and risks evaluated
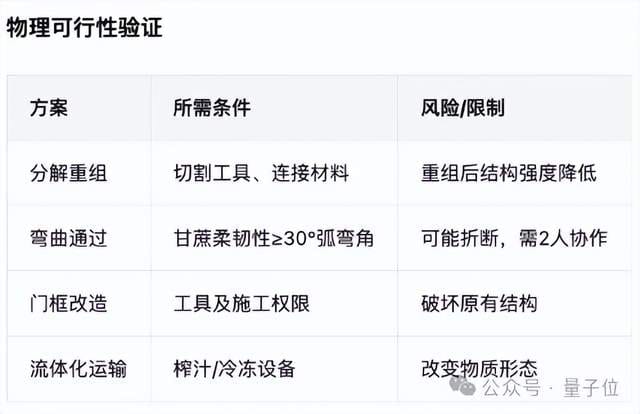
Result: Solid, accurate reasoning.
---
Test 2: Probability Problem — “Alien Splitting”
> An alien arrives on Earth. With equal probability, it will:
> 1. Self-destruct
> 2. Split into two aliens
> 3. Split into three aliens
> 4. Do nothing
>
> Each alien chooses once per day, independently.
>
> Find the probability that eventually no aliens remain.

- Reaction Speed: Instant analysis
- Approach: Problem type recognized → Mathematical model built
- Answer: \( \sqrt{2} - 1 \)
---
Test 3: Code Generation — Nobel Prize Website
Result Produced:

Ling‑1T, without special prompting, intelligently structured content into:
- Overview
- Categories
- Historical timeline
User benefit: Quick navigation with clear hierarchy.
---
Test 4: Travel Itinerary Planning
Ling‑1T:
- Categorizes attractions by unique features
- Suggests a one-day schedule
- Estimates costs
- Recommends transportation
- Lists local specialty foods
Outcome: Well-labeled options — easy decision-making.
---
AI Monetization Connection: AiToEarn
Innovations like Ling‑1T highlight rapid AI progress and everyday utility. For creators and businesses, platforms such as AiToEarn官网 offer:
- Open-source global AI content monetization
- Multi-platform publishing: Douyin, Kwai, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
- Integration with AI模型排名
- AI-powered content generation + publishing + analytics — efficient & profitable

---
Syntax–Function–Aesthetics Hybrid Rewards
Ling‑1T’s hybrid reward mechanism ensures generated code is:
- Correct
- Functionally complete
- Visually and aesthetically refined
Result: Top spot in ArtifactsBench front-end benchmark among open-source models.
---
Technical Insights — “Mid-training + Post-training” Approach
Ant Group has disclosed Ling‑1T’s technical blueprint.
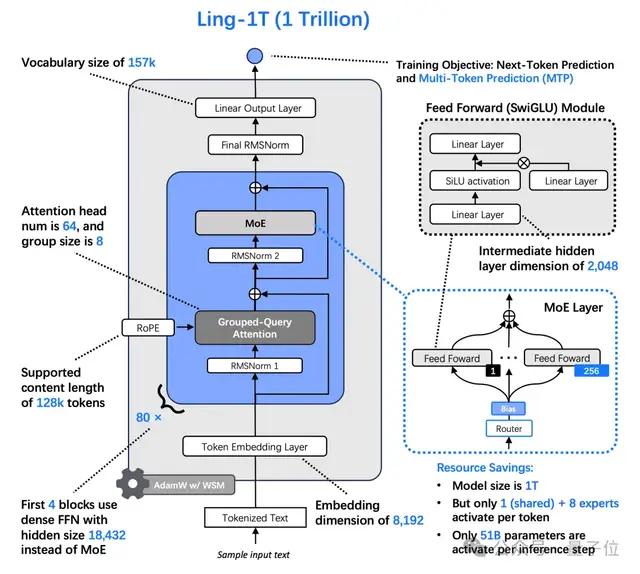
Goals:
- Scale model size → Enhanced memory & reasoning
- Boost reasoning ability → Greater accuracy in complex tasks
Model Specs:
- Ling 2.0 architecture
- 1 trillion parameters
- ~50B parameters activated per token
- Pre-trained on 20T tokens of high-quality, reasoning-rich data
- Context window: 128K tokens
---
Three-stage Pre-training:
- Phase 1: 10T tokens — high-knowledge-density data
- Phase 2: 10T tokens — high-reasoning-density data
- Mid-training:
- Expand to 32K context
- Increase reasoning data proportion
- Add Chain-of-Thought corpus
---
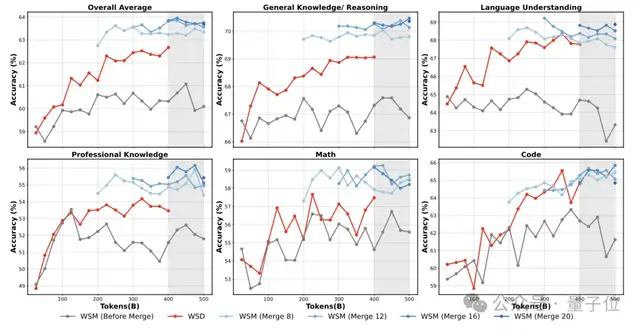
Ling Scaling Laws & WSM Learning
- Ling Scaling Laws guide learning rates & batch sizing
- WSM (Warmup-Stable-and-Merge) replaces WSD strategy:
- Warmup — gradual start
- Stable — maintain learning speed
- Merge — integrate checkpoints
Merging Insight:
Performance depends on merge timing and window, not number of merges.
---
Post-training — LPO Innovation
Current RL algorithms:
- GRPO: Token-level → overly fragmented semantics
- GSPO: Sequence-level → oversmoothed rewards
Ant Group’s LPO (LingPO):
- Sentence-level policy optimization
- Balanced semantic integrity & logical structure
- Importance sampling & clipping at sentence level
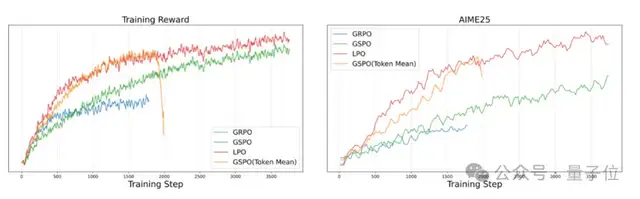
Outcome: Greater stability + better generalization vs GRPO & GSPO.
---
China’s Big Model Momentum
2025 releases show China’s open-source rapid pace:
- DeepSeek disrupted foundations
- Qwen family challenged LLaMA dominance
- National Day: Qwen3-Next, Qwen3-VL, Qwen-Image-Edit-2509
- DeepSeek V3.1 & V3.2 releases — rumors of bigger models
- Post-holiday: Ant releases Ling‑1T
---
Ling‑1T Summary:
- Joins trillion-parameter open-source club
- New architecture → efficient cognitive reasoning
- Evolutionary Chain-of-Thought → iterative optimization & transparency
- Rapid response in complex mathematics, logic, code, and scientific analysis
---
Impact for Creators
Platforms like AiToEarn官网 empower creators to:
- Generate AI content
- Publish across platforms simultaneously
- Analyze & monetize effectively
By connecting generation, publishing, ranking, and monetization tools, AiToEarn turns cutting-edge AI — like Ling‑1T — into tangible impact and income.
---
Next big surprise in AI?
Given recent trends — highly likely to come from China.



