How AI Agents Use File Systems for Context Engineering
How Agents Can Use Filesystems for Context Engineering
Source: Original LangChain Blog
---
Introduction: Filesystems as a Key Tool for Deep Agents
Deep Agents have a core capability: using filesystem tools to read, write, edit, list directories, and search files within their own environment.
Why is this important? To answer that, we must first examine where agents fail:
- The model itself isn’t intelligent enough.
- The model fails to obtain the correct context information.
Context engineering — described by Andrej Karpathy as “the subtle art and science of putting just the right amount of information into the context window for the next step” — is essential for building reliable agents.
---
Understanding Context Engineering
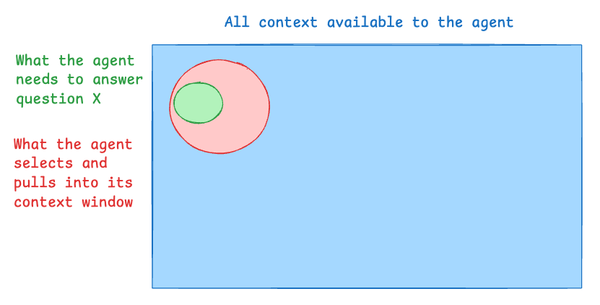
In modern AI workflows, agents often have huge volumes of available context (docs, code, FAQs), but they only need a small, relevant subset to answer a given question.
Context window = the AI’s short-term memory; the limited amount of data it can process at one time.
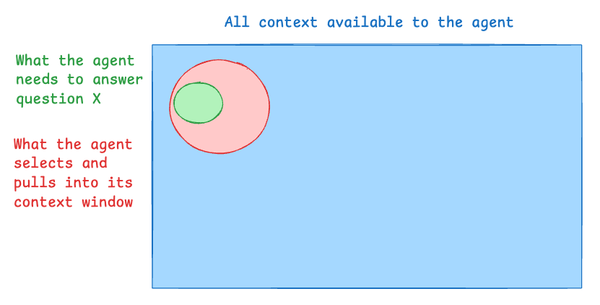
Common Failure Modes
- Missing Context: Required info is not indexed or accessible.
- Retrieval Failure: Info is available but not fetched.
- Over-retrieval: Too much irrelevant context wastes time, tokens, and costs.
- > (Tokens ≈ words/characters; retrieving excess context inflates costs and harms reasoning.)
Goal: Align the “needed context” zone with the “retrieved context” zone.
---
Challenges in Context Isolation
1. Token Overload
Large tool outputs bloat conversation history → high costs & degraded performance.
2. Massive Context Requirements
Some tasks need huge context volumes that exceed the window size.
3. Niche or Rare Information Retrieval
Crucial facts hidden in many files can be hard to locate.
4. Learning Over Time
Agents often lack mechanisms to incorporate newly acquired information for future use.
---
Why Filesystems Boost Agent Capabilities
A filesystem offers a flexible, persistent interface to store, retrieve, and update unlimited context. Here’s how it addresses the challenges:
---
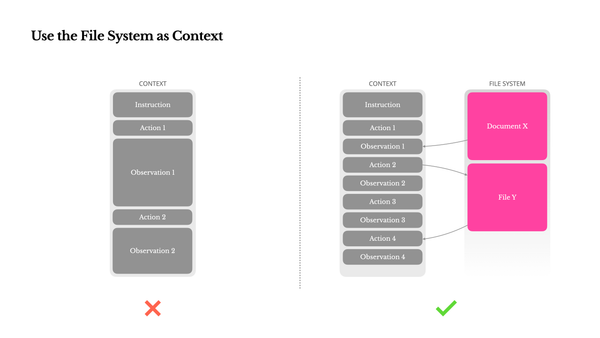
1. Managing Token Overload
Instead of dumping raw tool outputs into history, write them to the filesystem. Retrieve only relevant data when needed.
Example: Manus’ blog post
Use commands like `grep` to find exact matches in stored data.
> (grep = command-line tool to search for strings in files.)
Benefit: Acts as scratch space for large data, reducing token waste.
---
2. Handling Massive Context
Use the filesystem for structured, long-term storage:
- Long-Term Tasks: Write plans to disk; retrieve them later for focus.
- Subagent Collaboration: Subagents write knowledge to shared files, avoiding information loss.
This enables persistent, multi-source, and coordinated workflows.
---
3. Storing Complex Instructions
Keep operational guidelines in files rather than bloating System Prompts.
Example: Anthropic’s Skill Library
---
4. Finding Niche / Rare Information
Semantic Search ≠ perfect for all cases (e.g., code/API references).
Filesystem search via `ls`, `glob`, `grep` is often better:
- Models are trained to navigate filesystems.
- Folder structures provide natural organization.
- Tools can locate exact lines/characters.
- `read_file` enables partial file reads.
Example hybrid strategy: Cursor blog on semantic search.
---
5. Learning Over Time
Treat instructions/skills like any other context:
- Identify gaps in agent performance.
- Collect expert (or user-provided) instructions.
- Store/update them in filesystem files for future runs.
This allows agents to “remember” facts like user preferences across sessions.
---
Practical Applications: AiToEarn Integration
Platforms like AiToEarn官网 combine:
- AI generation
- Cross-platform publishing
- Analytics
- Model ranking
Supported Platforms: Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
For multi-platform creators, file-system-enabled agents make content handling more organized, scalable, and monetizable.
---
Using Deep Agents with Filesystems
LangChain’s Deep Agents repository:
- Available in Python and TypeScript.
- Built-in file system context engineering patterns.
- Extensible for future use cases.
Try it out and explore emerging best practices.
---
Conclusion
File systems offer AI agents:
- Persistent context storage
- Selective retrieval
- Efficient collaboration
- Dynamic learning over time
Combined with platforms like AiToEarn, they enable robust, cost-effective, and scalable AI workflows.
---
Subscribe for LangChain team updates and community insights.


