How Grab Builds AI Foundation Models to Better Understand Customers
Grab’s Foundation Model: Unifying Personalization Across a Superapp
> Disclaimer:
> The details in this post are based on information publicly shared by the Grab Engineering Team.
> All credit for technical insights goes to them.
> Links to original articles and sources are provided in the References section at the end.
> We have added our own analysis.
> If you spot inaccuracies or missing details, please comment so we can address them.
---
Overview
Grab operates one of the most data-rich platforms in Southeast Asia, evolving from ride-hailing into diverse verticals such as:
- Food delivery
- Groceries
- Mobility
- Financial services
This expansion generates massive volumes of user interaction data revealing how millions engage with the platform daily.
From Manual Features to a Foundation Model
Historically, personalization relied on manually engineered features (e.g., order frequency, ride history, spending patterns).
These:
- Existed in silos
- Were costly to maintain
- Struggled to capture evolving user behavior
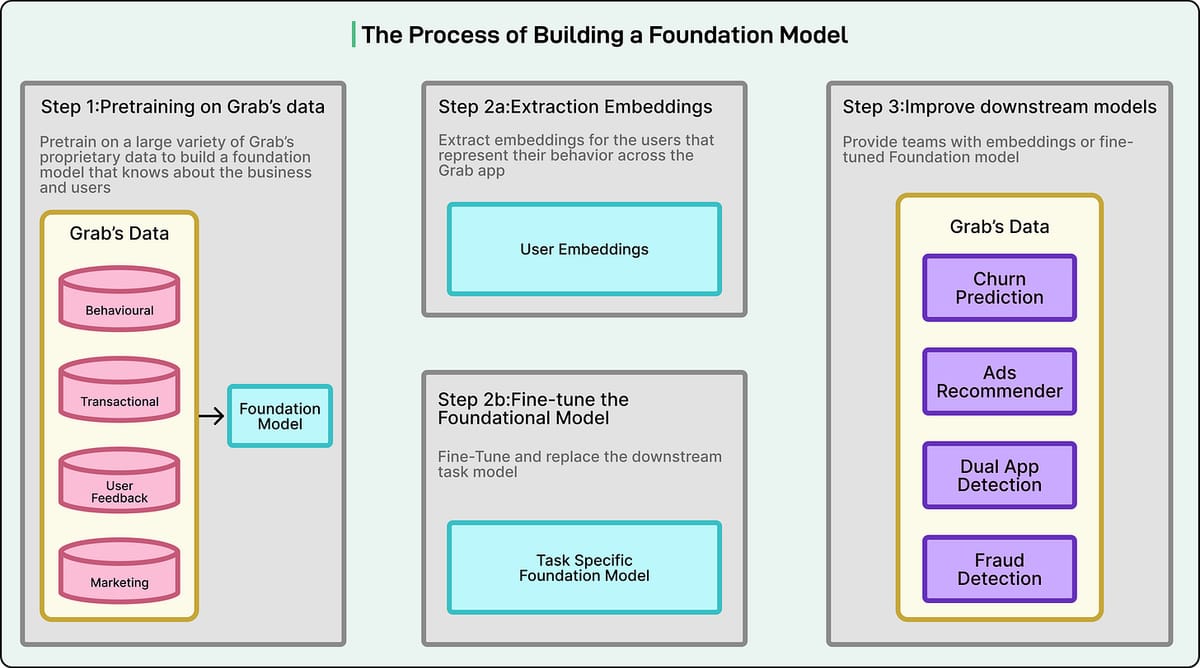
To solve this, Grab adopted a foundation model learning directly from:
- Tabular data (user profiles, transaction history)
- Sequential data (clickstream interactions)
From these signals, the model produces shared embeddings for users, merchants, and drivers — delivering unified, generalized representations of interactions.
---
Parallel in AI Content Ecosystems
Similar advancements occur in cross-platform AI content optimization.
Platforms like AiToEarn官网 integrate:
- AI content generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Analytics and model ranking (AI模型排名)
This mirrors Grab’s approach: leveraging embeddings to capture evolving behaviors efficiently.
---
Data Foundation
Grab’s superapp integrates services producing diverse behavioral signals.
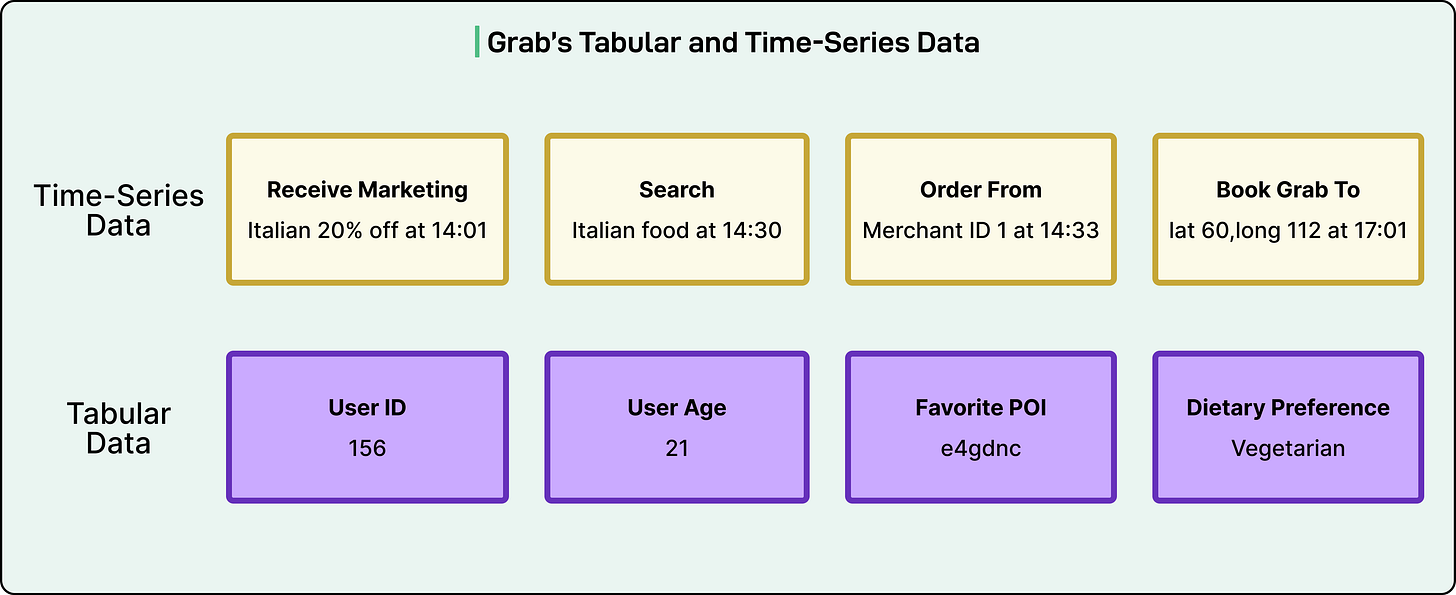
This unified model depends on two primary data categories:
- Tabular Data – Long-term profiles and habits
- Demographics
- Saved addresses
- Spending trends
- Order/ride frequency
- Clickstream (Time-Series) Data – Short-term, real-time context
- Session events: views, clicks, searches, purchases
- Timing patterns signaling interest or decisiveness
Data Modalities
Multiple modalities with distinct characteristics:
- Text: search queries, merchant names, reviews
- Numerical: delivery fees, ride fares, distances, wait times
- Categorical IDs: user_id, merchant_id, driver_id
- Location: coordinates/geohashes linked to real-world places
Challenge: preserve structure & relationships when combining formats (e.g., ride drop-off location influencing next action).
---
Model Design Challenges
1. Learning from Tabular + Time-Series Together
- Tabular: static/slow-changing; order-independent
- Time-Series: sequential; order-sensitive
Need architecture to natively handle both without losing context.
2. Handling Multiple Modalities
Text, numbers, IDs, locations — each requires specialized preprocessing.
3. Generalizing Across Tasks
Avoid embeddings biased to a single vertical — must support recommendations, ads, fraud detection, churn prediction.
4. Scaling for Massive Vocabularies
Hundreds of millions of IDs — naive output layers would be too large and slow.
---
Architecture Overview
Transformer Backbone
Chosen for ability to learn complex relationships in sequences.
Challenge: learn jointly from both tabular and time-series.
---
Tokenization Strategy
All information becomes `key:value` tokens:
- Tabular: `column_name:value`
- Time-Series: `event_type:entity_id`
---
Positional Embeddings & Attention Masks
Rules differ by data type:
- Tabular tokens: unordered set
- Time-series tokens: ordered sequence
Attention masks control which tokens relate and respect chronology only where needed.
---
Adapter-Based Modality Handling
Adapters = specialized mini-models for each modality:
- Text: pre-trained language model encoders
- ID: embedding layers per unique identifier
- Location/Numerical: custom encoders preserving spatial/numeric structure
Alignment Layer projects all adapter outputs into a shared latent space.
---
Training Strategy
Unsupervised Pre-Training
Avoids bias toward single tasks/verticals; learns general patterns across all data.
Techniques:
- Masked Language Modeling (MLM) – hide tokens, predict missing
- Next Action Prediction –
- Predict next action type
- Predict next action value/entity
Modality-Specific Reconstruction Heads
Loss functions tailored per modality:
- Cross-entropy for IDs
- MSE for continuous values
---
Massive ID Vocabulary Solution
Hierarchical Classification Strategy:
- Predict high-level category (user, driver, merchant)
- Predict specific ID within category
Reduces parameters and improves stability.
---
Applying the Foundation Model
Fine-Tuning
Continue training model for specific labeled tasks:
fraud risk, churn, ad targeting.
Embedding Extraction
Use model to generate user/merchant/driver embeddings; feed into other models.
Enables quick feature generation without retraining large models.
---
Dual-Embedding Strategy
- Long-Term Embedding: stable behavior over time
- Short-Term Embedding: most recent sequence of actions, compressed via Sequence Aggregation Module
---
Conclusion
Grab’s foundation model:
- Integrates tabular + time-series
- Learns cross-modal representations
- Replaces fragmented personalization pipelines
- Powers multiple downstream applications
Future Vision: “Embeddings as a Product”
- Central service for embeddings of all entities (users, merchants, drivers, locations, bookings, marketplace items)
- Priorities:
- Unify data streams for cleaner signals
- Evolve architecture for richer sources
- Scale infrastructure for growth
---
References
---
Sponsor Us:
Reach 1,000,000+ tech professionals — email sponsorship@bytebytego.com.
---
This rewritten version retains all links, technical detail, and structure but improves readability with clear headings, bullet points, and highlights, making it easier for tech readers to scan and comprehend the architecture and strategies. Would you like me to also create a visual workflow diagram summarizing Grab’s data-to-embedding pipeline? That could make the content even more digestible.


