How Perplexity Is Building the Google of AI
## Disclaimer
The details in this post are based on information publicly shared by the **Perplexity Engineering Team**, **Vespa Engineering Team**, **AWS**, and **NVIDIA**.
All technical credit belongs to the respective teams. Links to original articles and sources are provided in the **References** section at the end.
We have added our analysis and perspective. If you notice inaccuracies or missing information, please leave a comment and we will correct them promptly.
---
## Vision: From Blue Links to an Answer Engine
At its core, **Perplexity AI** was built on a simple yet powerful vision:
**Transform online search from a list of links into a direct *answer engine*.**
### The Goal
- Read through web pages *on behalf of the user*
- Extract the **most crucial information**
- Present it as a **single, clear answer**
### Unique Approach
Unlike traditional AI chatbots relying on static training data:
1. **Scans the live Internet** to find the most up-to-date, relevant data
2. Interprets and synthesizes these findings into a **concise answer** with **citations**
**Key Problems Addressed:**
- Inability to reflect **real-time events**
- Tendency to **hallucinate** or fabricate data
By grounding answers in **verifiable web content** with citations, Perplexity aims to be **trustworthy** and **reliable**.
---
## Background and Pivot
Interestingly, Perplexity didn’t start with this vision.
The original project was an **English-to-database-query tool**.
**Turning Point:**
- Late 2022: ChatGPT release
- Observed ChatGPT criticism: **no verifiable sources**
- Realized their internal prototype solved this
- **Strategic pivot**: Abandoned 4 months of work, focusing on **web-based answer engine**
---
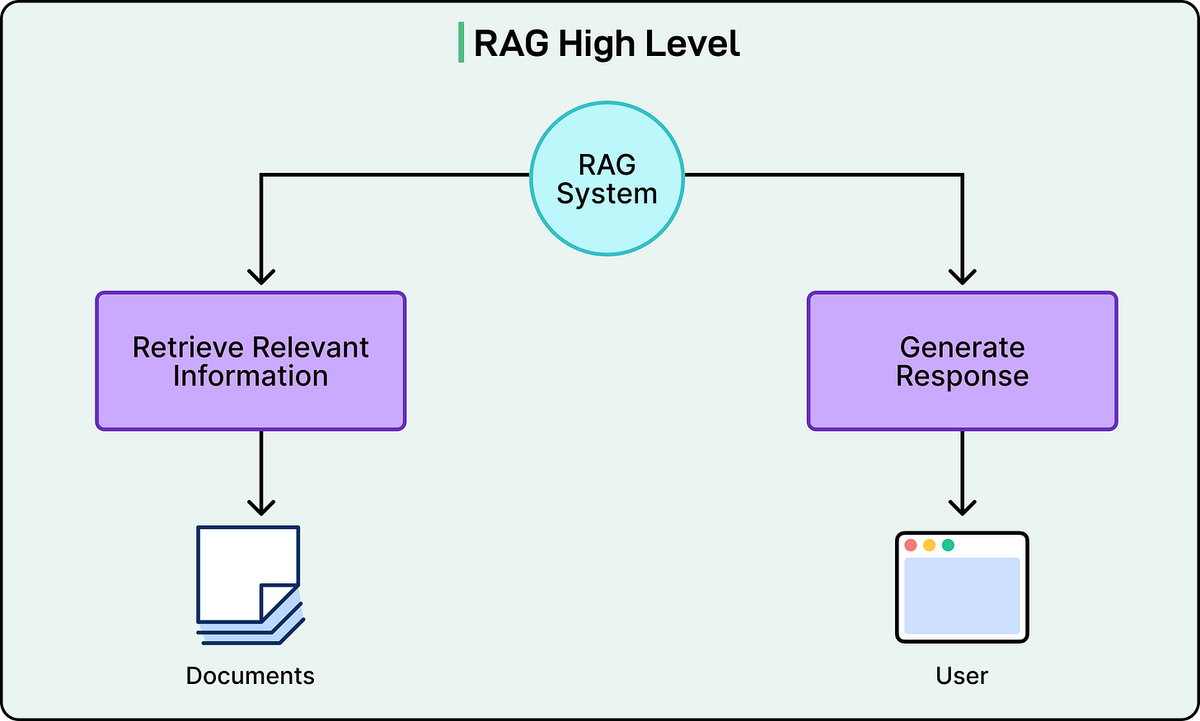
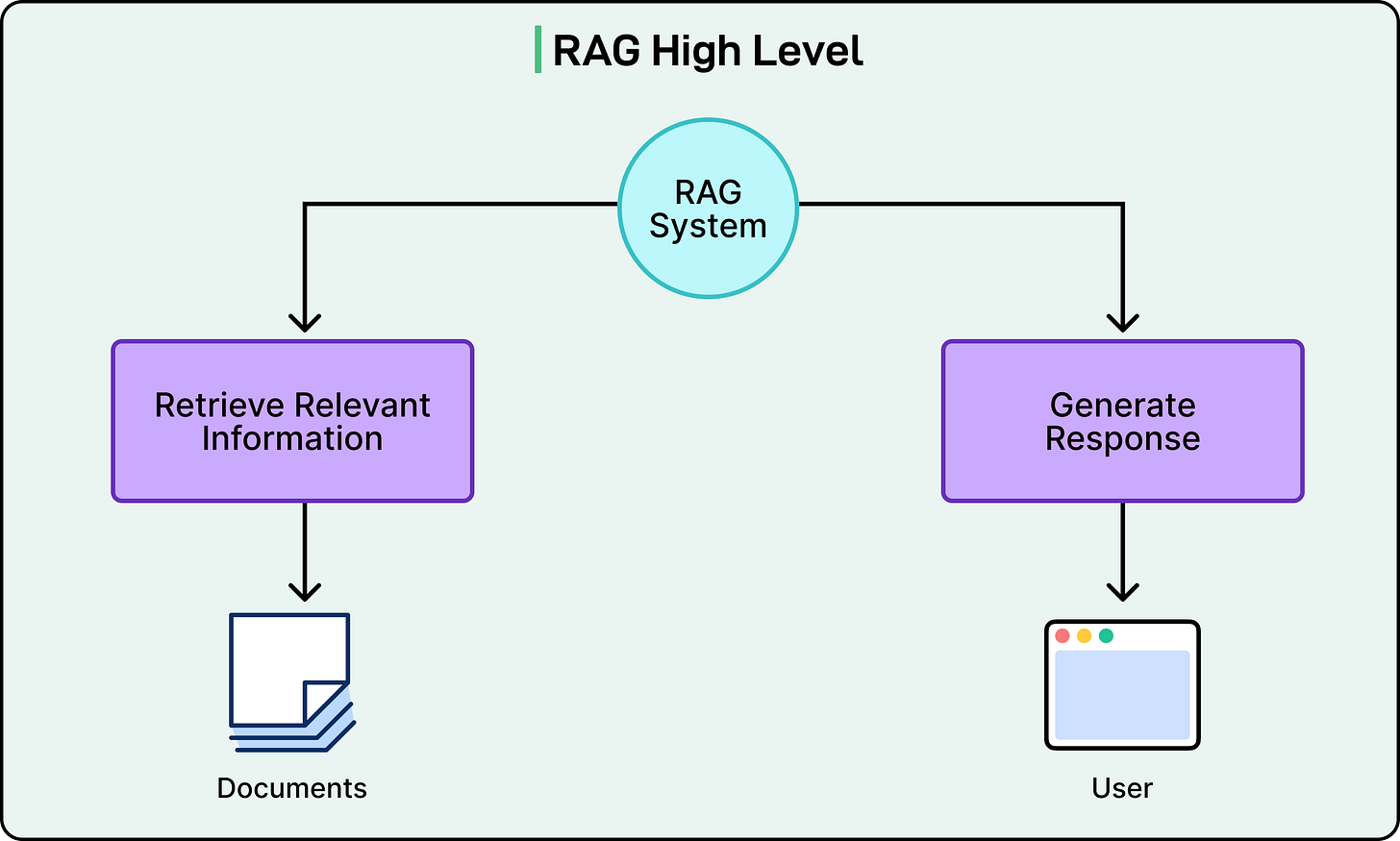
## Perplexity’s RAG Pipeline
The backbone of Perplexity’s service is **Retrieval-Augmented Generation (RAG)** — a multi-step process executed for nearly every query.
[](https://substackcdn.com/image/fetch/$s_!hGt1!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F7b2afcc8-5cf4-4aca-a9ba-9f1711a3919b_2526x1518.png)
### Five Stages of Perplexity’s RAG
1. **Query Intent Parsing**
- Uses Perplexity’s fine-tuned models or GPT-4 to understand query semantics beyond keywords
2. **Live Web Retrieval**
- Mandatory step: retrieves current, relevant pages/documents
3. **Snippet Extraction & Contextualization**
- Extracts most relevant chunks; builds “context” for LLM
4. **Synthesized Answer Generation with Citations**
- Generates response based strictly on retrieved context
- Adds **inline citations** for verification
5. **Conversational Refinement**
- Maintains conversational context
- Integrates follow-up queries with fresh retrieval
---
## The Orchestration Layer
Perplexity’s strength lies in **model orchestration**, not a single superior LLM.
**Key Design Features:**
- **Model-agnostic architecture**
- Mix of proprietary **Sonar models** and external models (GPT, Claude)
- **Intelligent routing** system:
- Lightweight classifiers assess query scope
- Route to smallest viable model OR powerful model for complex tasks
**Benefits:**
- Optimal **performance vs. cost**
- Avoids **vendor lock-in**
- Adapts quickly to evolving LLM landscape
---
## The Retrieval Engine: Powered by Vespa AI
**Why Vespa?**
- Real-time, scalable performance
- Unified capabilities:
- Vector search
- Lexical search
- Structured filtering
- Machine-learned ranking
](https://substackcdn.com/image/fetch/$s_!UPE0!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F392ab003-09fe-4a29-845b-182b0429ca4a_3060x1774.png)
*Source: [Perplexity Research Blog](https://research.perplexity.ai/articles/architecting-and-evaluating-an-ai-first-search-api)*
---
## Indexing and Retrieval Infrastructure
### Key Capabilities
1. **Web-Scale Indexing**
- 200B+ unique URLs
- Tens of thousands of CPUs
- 400+ PB hot storage
- Distributed architecture with co-located data & logic
2. **Real-Time Freshness**
- Tens of thousands index updates per second
- Efficient real-time mutations without query slowdown
3. **Fine-Grained Content Understanding**
- Breaks content into chunks
- Ranks paragraphs/sentences for relevance
4. **Self-Improving AI Parsing**
- AI-driven ruleset optimization
- Iterative refinement via LLM evaluations
5. **Hybrid Search and Ranking**
- Dense (vector) search for semantic match
- Sparse (lexical) search for precision
- Machine-learned ranking combining multiple signals
---
## Generation Engine
Two-part strategy:
1. **Perplexity’s Sonar Models**
- Fine-tuned open-source bases for summarization & citation adherence
2. **External AI Leaders**
- GPT & Claude for advanced reasoning tasks
- Integrated via **Amazon Bedrock**
**Objective:**
Balance cost, speed, and access to frontier AI capabilities.
---
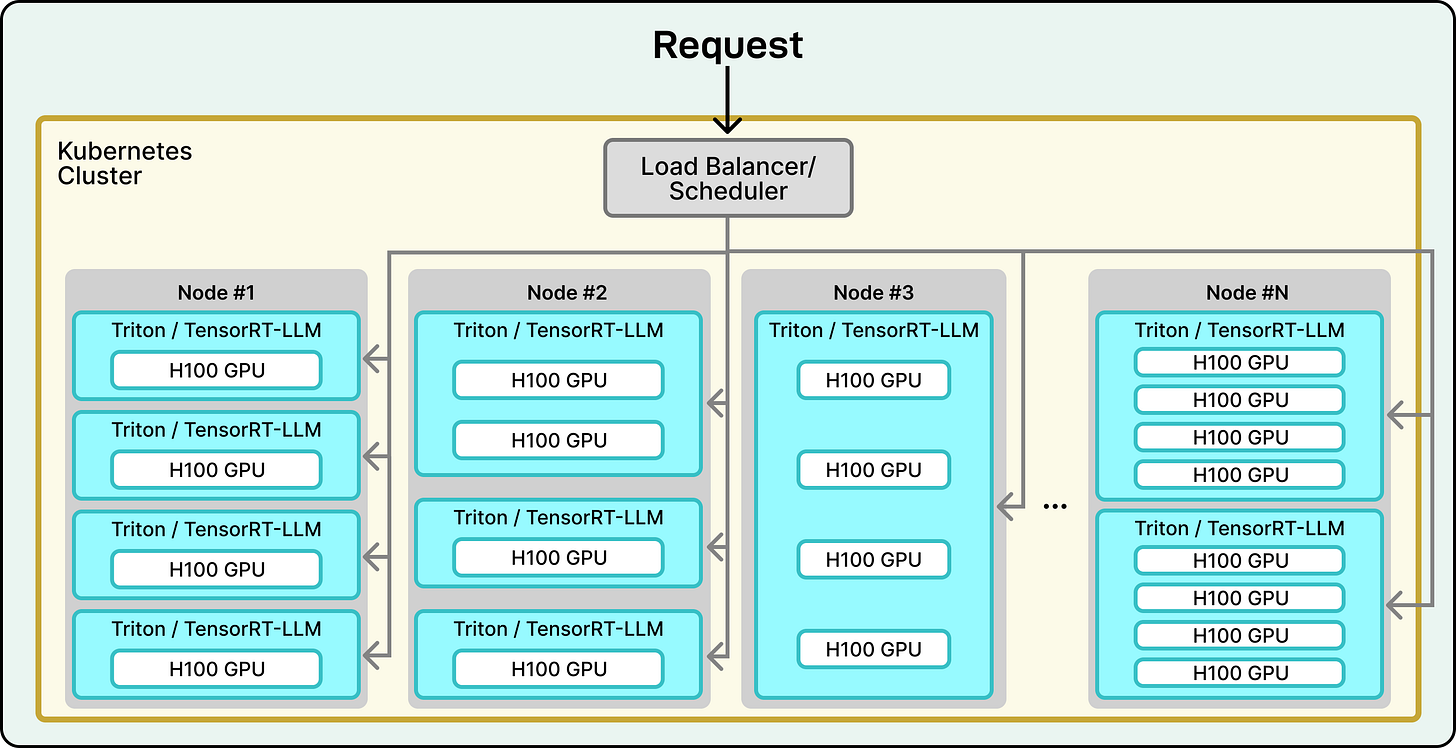
## Inference Stack: ROSE Engine
**Purpose:** Power fast, cost-efficient answers
**Design:**
- Flexible integration of new models
- Extreme optimization for performance
- Python + PyTorch core
- Critical components migrating to Rust
- Speculative decoding & multi-token strategies to minimize latency
- AWS deployment with NVIDIA H100 GPU pods
- Kubernetes cluster orchestration
](images/img_006.png)
*Source: [NVIDIA Technical Blog](https://developer.nvidia.com/blog/spotlight-perplexity-ai-serves-400-million-search-queries-a-month-using-nvidia-inference-stack/)*
---
## Conclusion
### Three Pillars of Perplexity AI:
1. **World-Class Retrieval Engine** (Vespa-powered)
- High-quality, current, relevant data foundation
2. **Flexible Orchestration Layer**
- Model-agnostic routing for performance & adaptability
3. **Hyper-Optimized Inference Stack** (ROSE)
- Full-stack control for speed and cost-efficiency
---
## References
- [Architecting and Evaluating an AI-First Search API](https://research.perplexity.ai/articles/architecting-and-evaluating-an-ai-first-search-api)
- [How Perplexity Beat Google on AI Search with Vespa AI](https://research.perplexity.ai/articles/architecting-and-evaluating-an-ai-first-search-api)
- [Spotlight: Perplexity AI Serves 400 Million Search Queries a Month Using NVIDIA Inference Stack](https://developer.nvidia.com/blog/spotlight-perplexity-ai-serves-400-million-search-queries-a-month-using-nvidia-inference-stack/)
- [Deep Dive Read With Me: Perplexity CTO Denis Yarats on AI-Powered Search](https://www.ernestchiang.com/en/notes/saas/perplexity-cto-denis-yarats-on-ai-powered-search/)
- [Perplexity Builds Advanced Search Engine Using Anthropic’s Claude 3 in Amazon Bedrock](https://aws.amazon.com/solutions/case-studies/perplexity-bedrock-case-study/)
---
## Sponsor Us
Reach **1,000,000+ tech professionals** — engineering leaders and senior engineers who influence major technology decisions and purchases.
Space fills fast! Reserve by emailing **sponsorship@bytebytego.com**.
Ad slots often sell out 4 weeks ahead.
This rewrite introduces clear headings, highlighted keywords, and logical grouping of steps so it’s easier to navigate, while preserving all original links and structure.


