How Spotify Built a Data Platform to Analyze 1.4 Trillion Data Points
Disclaimer
The details in this post are based on publicly shared information from the Spotify Engineering Team.
All credit for technical content belongs to them. Links to the original sources are listed in the References section.
We have analyzed and interpreted the shared details — if you spot inaccuracies or omissions, please comment so we can correct them.
---
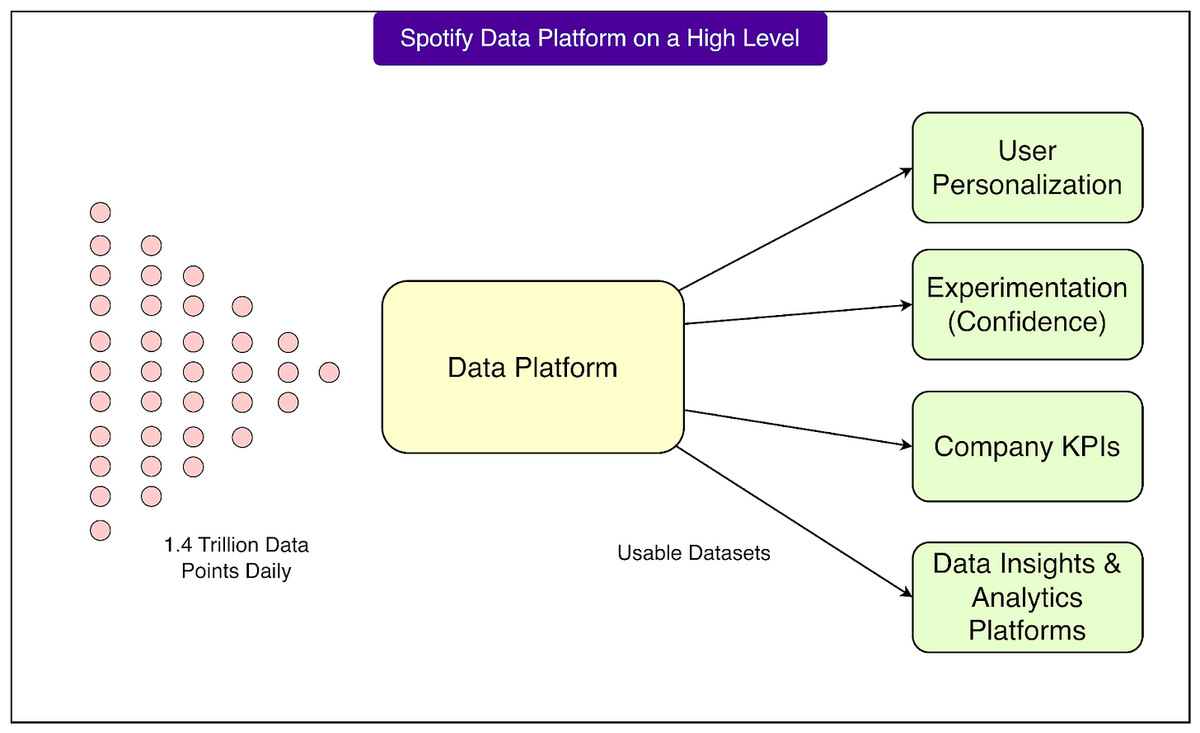
Overview: Spotify’s Data-Driven Core
Spotify processes approximately 1.4 trillion data points daily, generated by millions of global users through listening, playlist creation, and other app interactions.
Such scale demands a robust, centralized, and meticulously designed data platform that enables:
- Payment handling
- Personalized recommendations
- Product experimentation
- Advertising and reporting
Nearly every decision at Spotify is data‑driven, making its data platform one of the most critical elements of its technology stack.
---
Evolution Toward Centralization
Early on, Spotify relied on ad‑hoc, team-specific data systems.
As the business grew, fragmentation created inefficiency. The solution:
a structured, productized data platform serving the entire company, driven by two main factors:
Business Drivers
- Reliable data for financial reporting, advertising, experimentation, and personalization
- Consistency and trustworthiness for decision-making
Technical Drivers
- Infrastructure to handle data from millions of devices in near‑real time
- Defined data ownership
- Searchable datasets with integrated quality checks
- Privacy and regulatory compliance
---
Lessons for Modern Platforms
Centralized data platforms improve operational efficiency and unlock scalable innovation.
For organizations aiming to integrate AI content personalization, distribution, and monetization, solutions like AiToEarn官网 provide:
- AI content generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Analytics and AI model ranking
---
Sponsored Insight: AI-Driven Security Challenges

Key Stats from Vanta’s “State of Trust” Report:
- 61% spend more time proving security than improving it
- 59% say AI threats outpace their expertise
- 95% believe AI makes security teams more effective
Download the full report for strategies to stay ahead of AI threats.
---
Platform Composition & Evolution
In its earliest phase, a single team ran Europe’s largest Hadoop cluster.
Most workflows were manual or on shared infra. As Spotify grew, it shifted toward:
A multi‑product data platform with three functional layers:
- Data Collection – Ingesting events from millions of clients globally (apps, browsers, backend services).
- Data Processing – Cleaning, transforming, and organizing for usage via automated pipelines.
- Data Management – Ensuring privacy, security, data quality, and compliance.
---
Data Collection at Scale
Spotify’s data collection system reliably captures over 1 trillion events per day from varied clients and devices.
Developer Workflow:
- Define event schema (fields, formats)
- Automatic infrastructure creation (Pub/Sub queues, anonymization, streaming jobs)
- Handle schema changes via automated redeployment
Tech Enabler: Kubernetes Operators — managing data infrastructure as code for rapid, consistent deployments.
---
Privacy and Security
Built‑in anonymization protects sensitive data before downstream processing.
Strict access controls and internal key management ensure compliance with GDPR and similar regulations.
---
Self-Service & Ownership Model
Empowers product teams to:
- Define/update event structures
- Deploy instrumentation changes
- Monitor data quality
This reduces reliance on central teams, enabling scalability to thousands of active users internally.
---
Scale of Event Types
The system handles ~1,800 event types, supported by dedicated teams for:
- Infrastructure maintenance
- SDK development
- Building aggregated “journey datasets”
- Managing system health
---
Data Processing & Management
Spotify runs 38,000+ active pipelines (hourly or daily schedules) to:
- Aggregate plays
- Prepare recommendation datasets
- Generate financial reports
Requirements:
- Scalability, traceability, searchability
- Regulatory compliance
---
Execution Stack
Pipelines run on:
- BigQuery (large-scale analytics)
- Flink/Dataflow (stream/batch processing)
- Scio (Scala + Apache Beam for cross-engine compatibility)
Data Endpoints include:
- Explicit schemas
- Multi-partitioning
- Retention policies
- Access controls (ACLs)
- Lineage tracking
- Quality checks
---
Platform as Code
Spotify defines pipelines and endpoints entirely in code.
Custom Kubernetes Operators automatically deploy resources from code repositories, enabling:
- Clear ownership
- Consistency
- Faster iteration
Observability Layer:
- Alerts for delays/failures
- Endpoint health monitoring
- Integration with Backstage (backstage.io) for unified monitoring and documentation.
---
Conclusion
Spotify’s data platform evolved from a single Hadoop cluster to a cloud-based, multi-team system on Google Cloud, balancing central infrastructure with self-service capabilities.
A Data Platform Is Critical When:
- Cross-team searchable, democratized data is needed
- Financial/operational metrics require predictable pipelines
- Data quality & trust underpin decisions
- Experimentation needs efficient workflows
- ML initiatives require structured datasets
---
References
---
Sponsor Opportunity
Reach over 1M technology professionals, including engineering leaders.
Reserve limited ad spots by emailing sponsorship@bytebytego.com.
---
Tip for Creators: Platforms like AiToEarn官网 let you generate, publish, and monetize AI-driven content across multiple networks in one workflow — complementing ad strategies with organic, multi-channel reach.
---
Do you want me to also redesign this into a visual flow with diagrams of Spotify’s data lifecycle for even clearer readability? That could make it more engaging for technical audiences.


