How Tencent Music Cut Kafka Costs by Over 50% with AutoMQ

AutoMQ Case Study: Tencent Music’s Cloud-Native Kafka Upgrade
Date: 2025-10-23 14:52 Beijing


---
Editor’s Note
Tencent Music Entertainment Group, a leader in China’s online music and audio market, operates numerous popular mobile audio apps that generate massive volumes of user behavior and business data daily. This data fuels:
- Precise recommendations
- User growth strategies
- Monetization initiatives
At the heart of this lies a powerful, stable, and efficient Kafka streaming system.
The Challenge
As Tencent Music’s business grew, operational complexity and cost in traditional self-managed Kafka environments became bottlenecks. To support surging data streams while controlling costs, the operations team explored next-generation Kafka solutions.
The Solution: AutoMQ, a cloud-native Kafka architecture, reduced cluster costs by over 50%, enabled second-level partition migration for rapid scaling, and cut operational overhead dramatically. This mirrored earlier success in decoupling compute and storage for their data warehouses.
---
Background
Tencent Music serves a broad, diverse user base in China, delivering music streaming and social entertainment experiences.

---
Technical Architecture
For massive user volumes, fast and reliable data flow, processing, and analytics are essential. Kafka forms the backbone of Tencent Music’s data infrastructure, achieving:
- Upstream/downstream decoupling
- Real-time, on-demand data consumption
- Independent evolution of producers and consumers
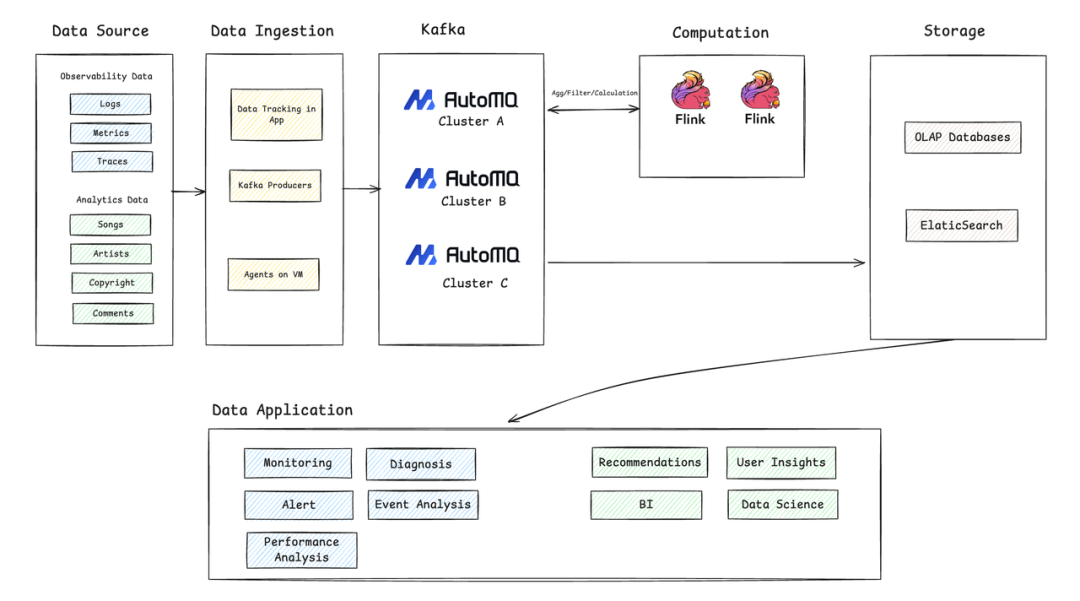
Architecture Flow
From source collection to ingestion → Kafka streaming (via AutoMQ) → real-time processing → storage → business applications.
---
Key Pipeline Stages
1. Data Source
- Observability Data: logs, metrics, traces
- Analytical Data: metadata (songs, artists, copyright), user actions (playback, comments)
2. Data Ingestion
Unified access via Tencent Music’s internal Data Channel platform:
- Preprocessing: segmentation, field filtering, security checks, dispatch
- Collection mechanisms:
- App SDKs for event tracking
- Standard Kafka Producers for business services
- VM Agents for system logs/metrics
3. Stream System (Kafka via AutoMQ)
Centralized AutoMQ clusters manage massive, multi-business data flows with high throughput and low latency.
4. Real-Time Computation
Using Flink for:
- Aggregation & filtering
- Real-time monitoring/alerting
- Pre-cleaning data before storage
5. Data Storage
- OLAP DBs for BI & analytics
- Elasticsearch for fast search/troubleshooting
6. Data Applications
- Observability: monitoring, diagnostics, event analysis
- Business Analytics: recommendations, user insights, data modeling

---
Kafka Challenges
Escalating Costs
Issues with Kafka’s integrated architecture led to:
- High idle resource reservations (30%–40% or more) for traffic peaks
- Expensive local disk storage costs
- Extra CPU usage from multi-replica synchronization
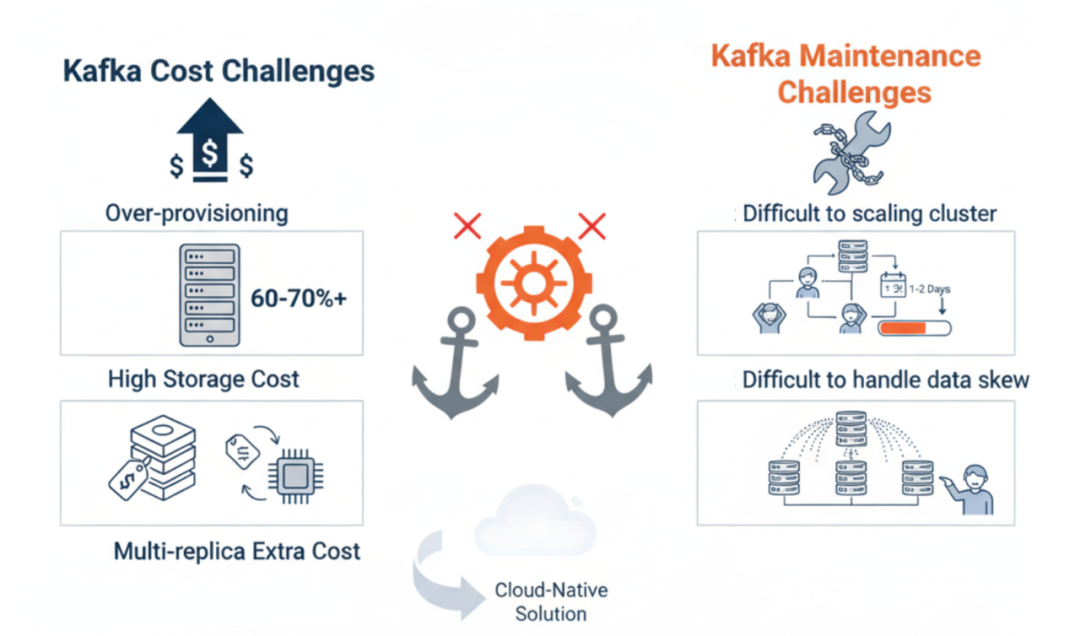

Operational Burden
- Scaling up/down = lengthy “major surgery” (~1 day, heavy manual steps)
- Hotspot mitigation requires manual write strategy adjustments
- High risk of service impact during operations

---
Why AutoMQ
Key Benefits:
- Rapid Elasticity — Stateless Brokers + object storage → partition migration in seconds
- Lower Costs — Independent scaling of compute & storage, object storage replaces local disks
- Kubernetes-Native — Fully stateless architecture for optimal scheduling & failover
- Iceberg Support — Table Topic streams directly to Iceberg tables, cutting ETL overhead
- Seamless Migration — Full Kafka protocol compatibility, zero app code changes

---
Evaluation & Migration Process
Phase 1 — Load Validation
- June 2025: High-throughput test (large data, low QPS) → validated sustained performance with object storage
- July 2025: High-QPS test (small messages, frequent connections) → validated metadata handling and small I/O aggregation

Outcome: AutoMQ met/exceeded production performance expectations → green light for migration.
---
Phase 2 — Production Migration
Three Steps:
- Switch Producers — Roll out endpoint changes → new data flows into AutoMQ
- Drain Old Cluster — Consumers process all historical data in old cluster
- Switch Consumers — Move consumers to AutoMQ; start from earliest offset

---
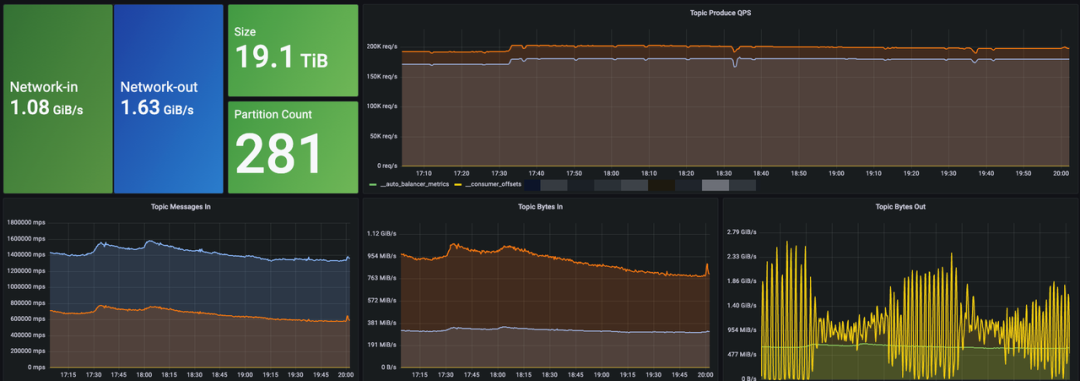
Go-Live Results
- 6 AutoMQ clusters deployed
- Peak write throughput: 1.6 GiB/s
- Peak QPS: ~480K
- >50% cost reduction (compute + storage)
- Second-level scaling → +1 GiB/s capacity in tens of seconds
- Dramatic improvement in operational agility & risk reduction


---
Future Outlook
Planned next steps:
- Full migration of all Kafka clusters to AutoMQ
- Implement Iceberg ingestion via Table Topic → streamlined data lake pipeline
- Standardize AutoMQ as core infrastructure across Tencent Music
- Migrate Kafka to Kubernetes → full cloud-native adoption
---
References:
---
If you'd like, I can extend this into a detailed "Migration Playbook" with risk mitigation strategies and rollback plans for large-scale Kafka-to-AutoMQ transitions. Would you like me to prepare that next?