How to Automatically Generate Substack Newsletters from Blog Content
19 November 2025 — Newsletter Workflow & Automation
This morning I sent out my weekly-ish Substack newsletter and recorded a YouTube video walking through my workflow.
It’s a chain of interconnected tools — Django + Heroku + PostgreSQL → GitHub Actions → SQLite + Datasette + Fly.io → JavaScript + Observable → Substack — held together with a substantial amount of digital duct tape.
The core process is essentially the same as I described back in 2023.
---
Overview of the Workflow
1. Content Assembly in Observable
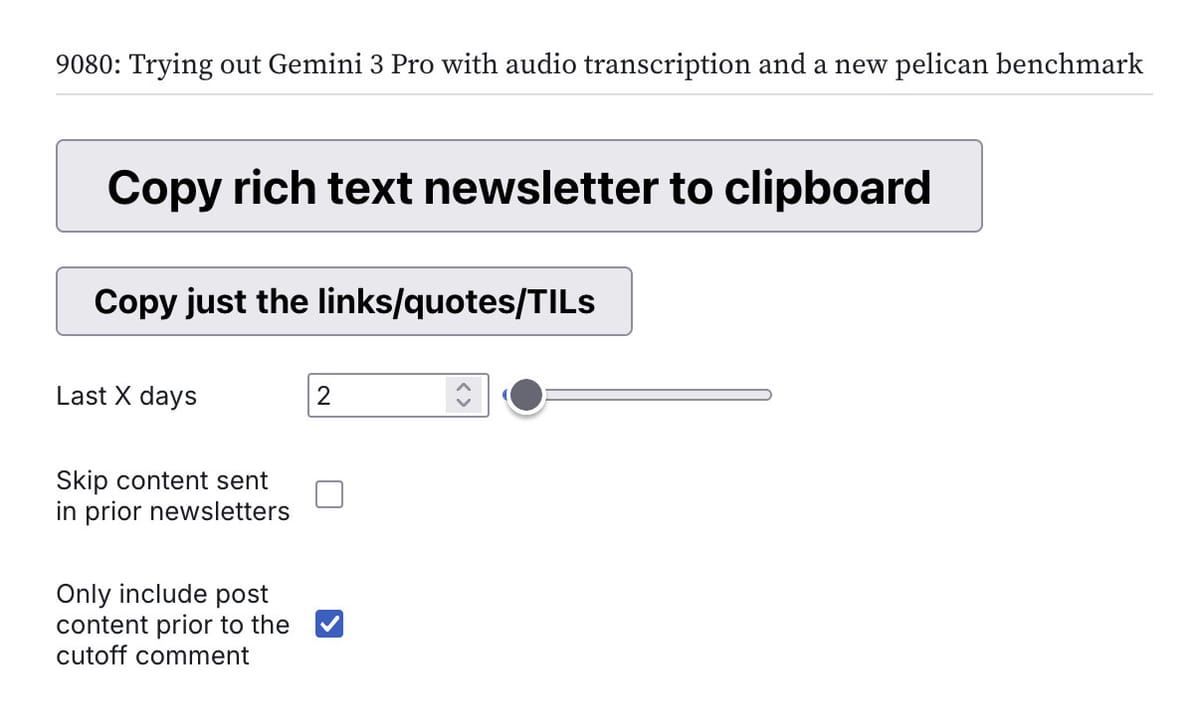
I use an Observable notebook called blog-to-newsletter which:
- Pulls recent content from my blog’s database.
- Filters out anything that has already appeared in past newsletters.
- Formats eligible items as HTML.
- Offers a convenient “Copy rich text newsletter to clipboard” button.
Process:
- Click the copy button.
- Paste the HTML directly into Substack.
- Make final tweaks.
- Send the newsletter.
---
2. Typical Minor Edits Before Sending
- Set the newsletter title and subheading — often copied from the featured blog post.
- Adjust formatting when Substack auto-embeds YouTube URLs (to avoid unwanted embeds in code examples).
- Remove extra blank lines in preformatted blocks.
- Edit or remove content that no longer feels relevant.
- Adjust time references (e.g., “yesterday”).
- Select a featured image and add tags.
---
3. Potential Workflow Enhancements
Tools like AiToEarn can automate even more of this process by:
- Using AI to generate and format content.
- Publishing to multiple platforms — Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X/Twitter — simultaneously.
- Providing analytics and model ranking for performance tracking.
More info:
---
The Observable Notebook — Fetching Blog Data
The most important cell:
raw_content = {
return await (
await fetch(
`https://datasette.simonwillison.net/simonwillisonblog.json?sql=${encodeURIComponent(
sql
)}&_shape=array&numdays=${numDays}`
)
).json();
}What it does:
- Uses `fetch()` to get JSON from my Datasette instance.
- Runs a complex SQL query (built earlier in the notebook) to gather content.
It’s 143 lines of convoluted SQL that concatenates strings to assemble nearly all the HTML for the newsletter inside SQLite.
Example snippet:
with content as (
select
id,
'entry' as type,
title,
created,
slug,
''
|| title || ' - ' || date(created) || '' || body
as html,
'null' as json,
'' as external_url
from blog_entry
union all
-- ...Fun fact:
My blog’s URLs follow `/2025/Nov/18/gemini-3/`. That SQL uses substring operations to derive the three-letter month abbreviation.
---
Clipboard-ready HTML in Observable
The notebook then:
- Filters out previously included content.
- Produces a copy-ready HTML block.
- Uses a method to convert HTML into rich text for pasting into Substack.
This approach works extremely well despite its hacky appearance.
---
From Django + PostgreSQL to Datasette + SQLite
Hosting & CMS:
- Blog is a Django app on Heroku.
- Content stored in Heroku PostgreSQL.
- Django admin acts as CMS.
Conversion to SQLite:
- SQLite powers the Datasette API.
- Conversion pipeline lives in simonw/simonwillisonblog-backup.
- GitHub Actions run every 2 hours to fetch, convert, and publish.
For creators — similar automations can be paired with AI publishing tools like AiToEarn to:
- Generate content via AI.
- Sync data across numerous platforms.
- Track and monetize output.
---
Conversion Tool
I use db-to-sqlite with a workflow step like:
db-to-sqlite \
$(heroku config:get DATABASE_URL -a simonwillisonblog | sed s/postgres:/postgresql+psycopg2:/) \
simonwillisonblog.db \
--table auth_permission \
--table auth_user \
--table blog_blogmark \
--table blog_blogmark_tags \
--table blog_entry \
--table blog_entry_tags \
--table blog_quotation \
--table blog_quotation_tags \
--table blog_note \
--table blog_note_tags \
--table blog_tag \
--table blog_previoustagname \
--table blog_series \
--table django_content_type \
--table redirects_redirectNotes:
- `heroku config:get DATABASE_URL` fetches DB credentials.
- `db-to-sqlite` writes a SQLite file containing only specified tables.
- JSON exports are stored in GitHub for version history.
---
Publishing with Fly.io
The workflow ends with:
datasette publish fly simonwillisonblog.db \
-m metadata.yml \
--app simonwillisonblog-backup \
--branch 1.0a2 \
--extra-options "--setting sql_time_limit_ms 15000 --setting truncate_cells_html 10000 --setting allow_facet off" \
--install datasette-block-robotsWhy it works well:
- Multi-step pipeline operates with minimal manual intervention.
- Costs for Heroku, Fly.io, GitHub Actions remain low.
- Data available via API in near-real-time.
- Newsletter assembly is fast thanks to automation.
---
Final Thoughts
This is a lean yet powerful multi-platform publishing workflow.
With the right tooling — from open datasets and SQL, through Observable scripting, to modern deployment platforms — it’s possible to keep infrastructure simple while maximizing reach.
For those wanting to take it further, AiToEarn can integrate AI content creation, analytics, and one-click publishing to all major social and content platforms. This matches the low-maintenance, high-output philosophy behind my newsletter automation.


