# Building Better Agents: Lessons from Yunxiaoer Aivis
## Introduction
This year, our team has invested heavily in **Yunxiaoer Aivis** — a digital employee in the Alibaba Cloud services domain.
It represents our evolution from traditional intelligent customer service assistance to a new **end-to-end Multi-Agent** capability.

At its core, Yunxiaoer Aivis leverages:
- **LLM-based reasoning**
- **Multi-Agent architecture**
- **MCP Tool**, **Browser Use**, and **Computer Use** integrations
These allow digital employees to *think* and *reason* more like humans — a challenge spanning algorithms, engineering, and data.
For more details, see Hong Lin’s talk at the Yunqi Conference:
*[Yunxiaoer Aivis: Moving Toward Autonomous Agents in Alibaba Cloud’s Intelligent Services][1]*
---
## Common Agent Challenges
During my talks inside and outside the team, the questions I hear most frequently include:
- **Why does the Agent still perform poorly even after prompt fine-tuning?**
- **Why does the Agent become unstable and stop following instructions after multiple interactions?**
- **Why does it hallucinate and fail to output as expected?**
From the Yunxiaoer Aivis project — and many failed experiments — we’ve distilled **key lessons** you can apply to improve your own Agent or Multi-Agent systems.
---
## Why Agents Fail
Ask yourself two fundamental diagnostic questions:
1. **What’s your exact expectation?**
Vague goals like *“I want it to be smarter”* are not actionable.
2. **How is the Agent designed to meet it?**
### Expectation Layer
Replace **fuzzy expectations** with **clear, measurable ones**:
- Clearly describe **tasks**
- Define **precise output formats**
- Set **tone/style guidelines**
### Technical Layer
Two main improvement paths:
1. **Prompt / Context Engineering** (instructions, runtime assembly, historical context, memory retrieval)
2. **Model Optimization** (SFT, DPO, RLHF — costly for most developers)
Given rapid improvements in the base **Tongyi Qianwen** model, we focus here on **Context Engineering** and **Multi-Agent design**.
---
## Prompt vs Context Engineering
**Prompt Engineering** is not about drafting one perfect static prompt.
It’s about **engineering** dynamic runtime context:
- System instructions
- Conversation history integration
- Long-term memory usage
- Real-time adaptation
Many now adopt the term **Context Engineering** to emphasize these dynamic, engineering-heavy aspects.
For a deep dive, see Manus’s post:
*[Context Engineering for AI Agents: Lessons Learned from Building Manus][2]*
---
## Ten Core Lessons for Optimizing Agents
### 1. Clarify Expectations
**Principle:** Avoid ambiguity — make requirements explicit.
Break down expectations into:
- **Task requirements** — exact logic and criteria
- **Output format** — JSON schema, Markdown, function call, etc.
- **Style and tone** — professional, apologetic, concise, etc.
**Example:** ECS Port Security Group Status
A clear expectation might specify rules for "fully open," "partially open," or "closed" based on port, IP segment, and policy.
---
#### Pitfall: Ambiguity in Professional Terms
The "ECS Instance Lock" issue has **two distinct cases**:
1. **Business Lock** — overdue payments
2. **System Lock** — OS-level account lock due to failed login attempts
Customers saying “my server is locked” often get business-lock solutions, even when they mean system lock.
**Solution:**
- Explicitly define both lock types in context
- Add tool calls to check lock type before responding
- Ask targeted clarification questions if ID/status is unknown
---
### 2. Precise Context Feeding
**Principle:** Give **needed info**, remove **noise**.
Excess irrelevant detail confuses the model:
- **Pitfall:** Checking overdue payments returned many financial fields; the model made inconsistent judgments.
- **Solution:** Filter API responses; only pass relevant fields (e.g., available funds).
---
### 3. Clarify Roles and Action History
**Principle:** Define **who is who** and **what’s been done**.
In multi-role scenarios (customer, human agent, LLM), confusion arises if dialogue and operations aren’t differentiated.
**Solution:**
1. Keep the **main thread** between user and LLM.
2. Add human agent dialogue as **reference memory**, clearly labeled.
3. Preserve **full action history**, even failed attempts.
**Tip:** *Mask, don’t remove* obsolete tools; *keep wrong stuff in* to help the model adapt.
---
### 4. Use Structured Formats
**Principle:** Express logic in structured data — JSON, YAML, pseudocode — to reduce ambiguity.
Example: Multi-step workflows are better conveyed via JSON arrays than plain text lists.
---
### 5. Try Custom Tool Protocols
**Principle:** For domain-specific, high-stability tasks, custom protocols may outperform standards like OpenAI’s Function Call.
We still use our 2023 custom tool schema for many scenarios due to its stability and accuracy.
---
### 6. Use Few-Shot Wisely
**Principle:** Few-Shots can stabilize outputs — but can also limit creativity or cause overfitting.
- **Single-task:** Use diverse, representative examples, including edge cases.
- **Flexible tasks:** Minimize to preserve adaptability.
---
### 7. Keep Context Lean
**Principle:** Trim context to improve retention and reduce costs.
Even with large context windows, performance drops after ~10k tokens.
Use **RAG** or filtering to dynamically supply relevant pieces.
---
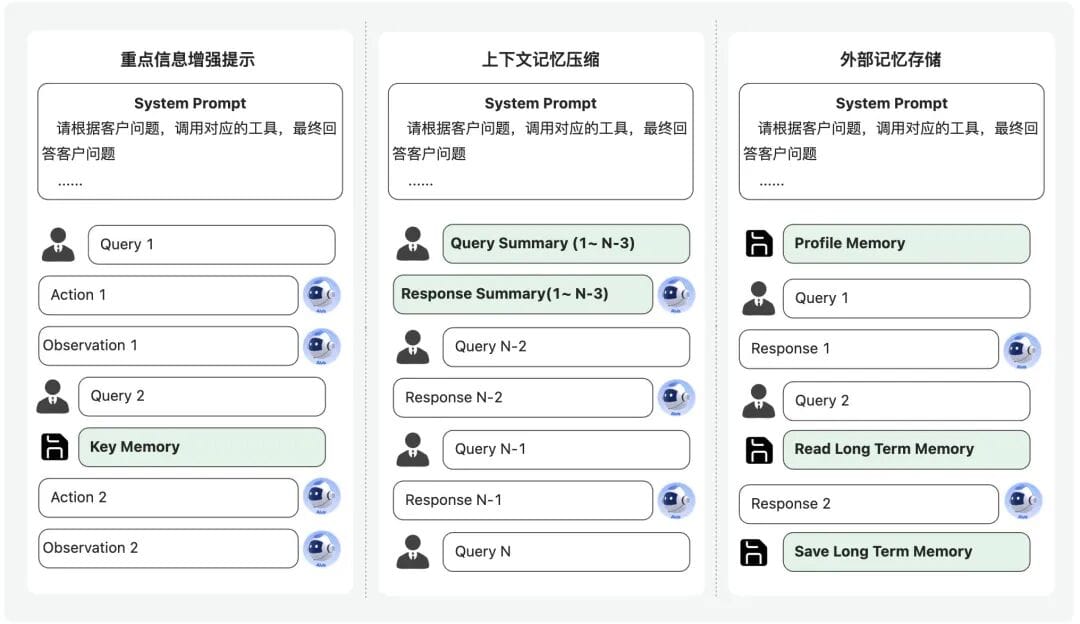
### 8. Manage Memory
**Principle:** Reinforce, compress, and store externally.
- **Reinforcement:** Reinject critical facts periodically
- **Compression:** Summarize older history
- **External storage:** Use vector DB or tools to “read/write” long-term memory as needed
---
### 9. Use Multi-Agent for Control + Flexibility
**Principle:** Combine orchestration with autonomous reasoning.
- **Main Agent:** Schedules, routes, and decides
- **Sub-Agents/Tools:** Handle fixed workflows or diagnostics
---
### 10. Keep Humans in the Loop (HITL)
**Principle:** Embed agents in **real workflows** and iterate with user feedback.
Observe human processes directly, understand reasoning steps, and refine the Agent to mirror them.
---
## Conclusion
A well-designed Agent:
- Has clear expectations
- Uses structured, precise context
- Balances control and flexibility with Multi-Agent design
- Retains history and memory effectively
- Incorporates human feedback continuously
For related practices on prompt optimization, Multi-Agent trade-offs, and dataset integration, see:
*[How to Build and Optimize Highly Available Agents?](https://mp.weixin.qq.com/s?__biz=MzIzOTU0NTQ0MA==&mid=2247550566&idx=1&sn=f4dedfb7bb47e02aa3b6e3478cc40d73&scene=21#wechat_redirect)*
---
## Related Resources
- [Yunqi Conference Session][1]
- [Manus: Context Engineering Lessons][2]
- [AiToEarn: Open-source AI content publishing](https://aitoearn.ai/)
Monetize AI content across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
See also: [AiToEarn博客](https://blog.aitoearn.ai), [GitHub](https://github.com/yikart/AiToEarn), [AI模型排名](https://rank.aitoearn.ai)
---
[1]: https://yunqi.aliyun.com/2025/session?agendaId=6008
[2]: https://manus.im/zh-cn/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus



