Huang Delivers “Thor’s Hammer” to Musk: Nvidia Personal Supercomputer Launches Today — Bring Home a “Local OpenAI” for Just Over 20K RMB?

NVIDIA Brings Data Center DGX Power to Your Desk
Date: 2025-10-16 15:08 Zhejiang
---


After years of “collective migration to the cloud,” limitations have become clear. Now a new trend is emerging — bringing cutting-edge, cloud-grade AI capability directly to every developer’s desk.
That personal PC with true cloud AI power is now here:
NVIDIA’s personal AI supercomputer — DGX Spark — is officially on sale today.
Starting at USD $3,999 (~RMB ¥23,791), it’s available now via the NVIDIA official site.
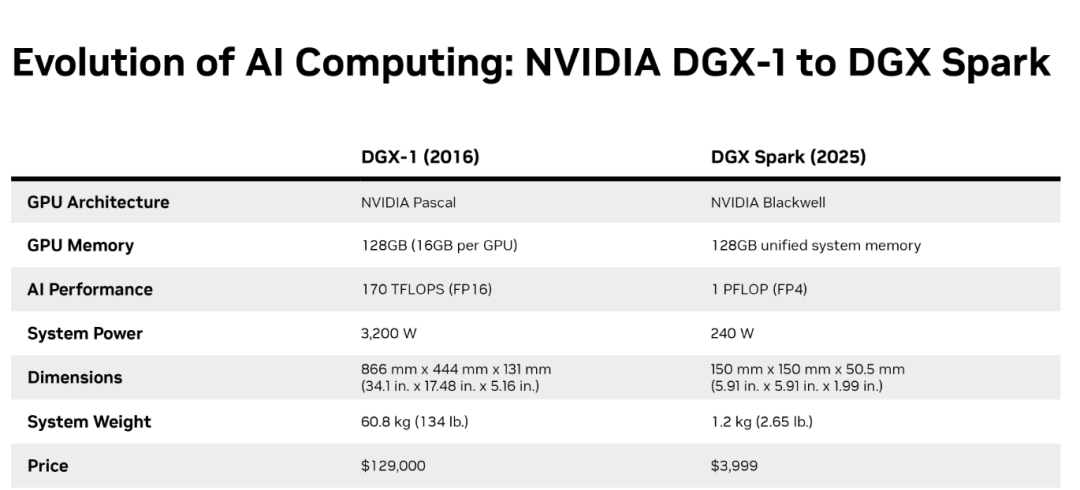
NVIDIA states that DGX Spark condenses the original DGX data center supercomputing architecture into “a personal AI supercomputer small enough to fit on a desk.”
Among the first batch of deliveries, Elon Musk received his Spark unit directly from Jensen Huang at the Starship test base.

Image source: NVIDIA official news release
> Jensen Huang: “Imagine delivering the smallest supercomputer next to the biggest rocket.”
> Elon Musk: “From a single spark, a world of intelligence! Ad astra!”

Image source: NVIDIA official news release
---
1. First-Hand Review — Why DGX Spark Stands Out
DGX Spark debuted at NVIDIA’s GTC conference in March as the smallest AI supercomputer in the world, with dimensions akin to a Mac mini.

At GTC, NVIDIA also revealed the DGX Station, a larger sibling aimed at enterprise workloads — designed as a personal cluster node for large model training.
- DGX Station: Heavy-duty, high-end training, enterprise deployment
- DGX Spark: Portable, designed for local inference and fine-tuning
---
Performance Insights from LMSYS
LMSYS, a nonprofit formed in 2023 by UC Berkeley, Stanford, Carnegie Mellon, and others, got early access and conducted detailed benchmarking:
- Medium-sized models (8B–20B parameters): DGX Spark matches or beats standalone GPU setups in the same price range, especially for batch processing with optimized frameworks.
- Large models (70B+ parameters): Usable for load testing and compatibility, though not optimal for production-grade deployment.
---
DGX Spark as a Local AI Workstation — Test Workflow
General steps tested by LMSYS:
- Model boot
- Inference optimization
- API invocation
- Interface integration
- IDE integration
- Fully local AI development environment build
Step 1 — One-click Model Service Launch
- Framework: SGLang via Docker
- Model: Llama 3.1 8B
- Result: Service remained persistently hosted on local port, mimicking cloud server behaviour → DGX Spark became a local AI node.

Step 2 — Enable Speculative Decoding (EAGLE3)
- Purpose: Tests scheduling & optimization capabilities
- Result: Smooth execution, throughput boost — proving DGX Spark can run and accelerate inference, not just execute scripts.

Step 3 — Local API Call
- API: `/v1/chat/completions` (OpenAI format)
- Result: Returned complete JSON reply — effectively delivering API service capability, comparable to cloud ChatGPT.


Step 4 — Web Interaction via Open WebUI
- Result: Browser-based UI allowing direct local model chat — no cloud, no account, zero latency jitter.
- Outcome: DGX Spark functions as a local ChatGPT-like conversation terminal.

Step 5 — IDE Integration (Zed Editor + Ollama)
- Features: Auto-completion, context-aware refactoring directly powered by DGX Spark.
- Outcome: Offline Copilot/Cursor-style development — a complete personal AI workflow.


---
Key Takeaway: DGX Spark’s real strength lies in operating persistently as a local AI server — callable from browsers, apps, or IDEs — akin to owning your own desktop OpenAI instance.
Hardware Foundation:
- Powered by NVIDIA GB10 Grace Blackwell (GB10) superchip
- Unified 128GB shared memory between CPU & GPU — removes VRAM limitations, eliminates transfer overhead
- 1 PFLOP-class AI compute → Data center DGX power in desktop form factor
---
2. Why "All-in-Cloud" Is No Longer Enough
The launch of DGX Spark is a pivotal case in AI’s reverse migration — from cloud back to local compute.
Problems from Cloud-Only Model
- Skyrocketing inference costs — continuous billing on cloud GPUs, bandwidth & traffic fees
- Privacy risks — sensitive data handled remotely
- Network bottlenecks — latency disrupts real-time applications
Basecamp famously cut costs by exiting the cloud; EasyAudit AI saw bills spike from $5k/month → $50k/month overnight due to inference loads.
---
Local Computing Power Has Caught Up
By 2025:
- DGX Spark → 1 PFLOP AI supercomputer at desktop
- Copilot+ PCs → GPT-grade local NPU inference
- Apple Intelligence → on-device inference for sensitive tasks
Economic Wins: SaaS vendors cut infrastructure bills by up to 80% via local deployment. Latency dropped to sub-50ms.
---
AI Has Shifted to Real-Time Role
- Applications include voice assistants, video generation, AR/VR, industrial control
- These demand near-zero latency → moving inference closer to end-user devices
- Distributed AI system model: Cloud = brain, Local hardware = hands/feet, Devices = nerve endings
---
Monetizing Local AI Workflows
Platforms like AiToEarn官网 let creators:
- Generate & publish AI content to multiple platforms (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X)
- Leverage analytics and AI model rankings (AI模型排名)
- Combine local AI compute with global audience outreach
---
References
- NVIDIA Spark Personal AI Supercomputer – The Verge
- Official NVIDIA DGX Spark Delivery Blog
- LMSYS DGX Spark Testing Blog
---
Related Reading
- 8,000 lines of Python + Rust to handcraft ChatGPT, earning 14.5k stars daily!
- Windows 10 Support Ends — Implications for Domestic OS
- New Python Version Removes GIL — Viral Debate
- Altman’s Super OS Vision Faces Three Bottlenecks

---
---
Question: What’s your perspective on bringing cloud AI capabilities back to the desktop via personal AI supercomputers like DGX Spark?