Huawei launches "near-trillion-scale MoE inference" with two killer optimization technologies released as open source

Machine Heart Report: Ultra-Large MoE Inference Breakthroughs
---
2025 Landscape: Inference Efficiency Takes Center Stage
As 2025 concludes, large AI models have evolved from niche tools into foundational infrastructure powering enterprise systems. In this shift, inference efficiency has become the critical factor for scalable deployment.
For ultra-large-scale MoE (Mixture-of-Experts) models, complex inference pipelines demand extreme optimization in:
- Computation
- Inter-node communication
- Memory access
Industry-wide, the challenge is ensuring highly efficient, controllable inference pathways.
---
Huawei’s Near-Trillion Parameter MoE Stack
Huawei has introduced a comprehensive technical solution:
- Model: `openPangu-Ultra-MoE-718B-V1.1`
- Near-trillion parameter MoE architecture
- Key Technologies:
- Omni Proxy scheduling
- AMLA acceleration (boosts Ascend hardware utilization to 86%)
👉 Open-source project: GitCode - Ascend Inference Cluster
---
Why Inference Efficiency Matters Now
Previously, large-model innovation focused on training scale and capability breakthroughs.
Today, the central question is:
> Who can run the model stably, at lower cost, with minimal latency?
Especially for ultra-large MoE models, real deployment means tackling:
- Optimal parallelism strategies
- Tight cost control — down to each operator call and communication node
- Avoiding latency amplification in coupled pipelines
---
OpenPangu-Ultra Deploys Efficiently on Ascend Hardware
With deep optimization:
- Peak operator performance
- Multi-stream concurrency for communication–computation
- Hidden inter-node communication delays
China’s surging token demand drives the need for maximal inference efficiency — critical for monetizing large models.
---
The Industry’s Core Challenge
> Run MoE models at hundreds of billions to near-trillion parameters with:
> - High speed
> - Stability
> - Production-grade deployment readiness
Huawei meets this challenge with Ascend-optimized inference acceleration and intelligent scheduling.
---
Model Overview
- openPangu-Ultra-MoE-718B-V1.1
- 718B total parameters
- 39B activated parameters
- Enhanced tool invocation & integration
- Quantized version: `openPangu-Ultra-MoE-718B-V1.1-Int8` (openPangu-Ultra)
- Proven feasible inference path on Ascend hardware
---

---
Ascend-Affinity Acceleration Technology
Objective: A faster, more stable route for near-trillion parameter MoE inference.
This approach integrates:
- Hardware synergy
- Intelligent scheduling
- Algorithmic optimization
Result: Production-ready AI deployment.
---
Ecosystem Synergy — AiToEarn
Platforms like AiToEarn官网 extend Huawei’s deployment advantages into content monetization:
- AI generation across major social networks (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Real-time analytics, publishing, and model ranking (AI模型排名)
This shows technology deployment + monetization infrastructure enables full commercial potential.
---
Omni Proxy Innovations for MoE Scheduling
Omni-Infer Integration
- Optimized for vLLM and SGLang
- Plug-and-play with Ascend hardware
- No need to rewrite application logic
---
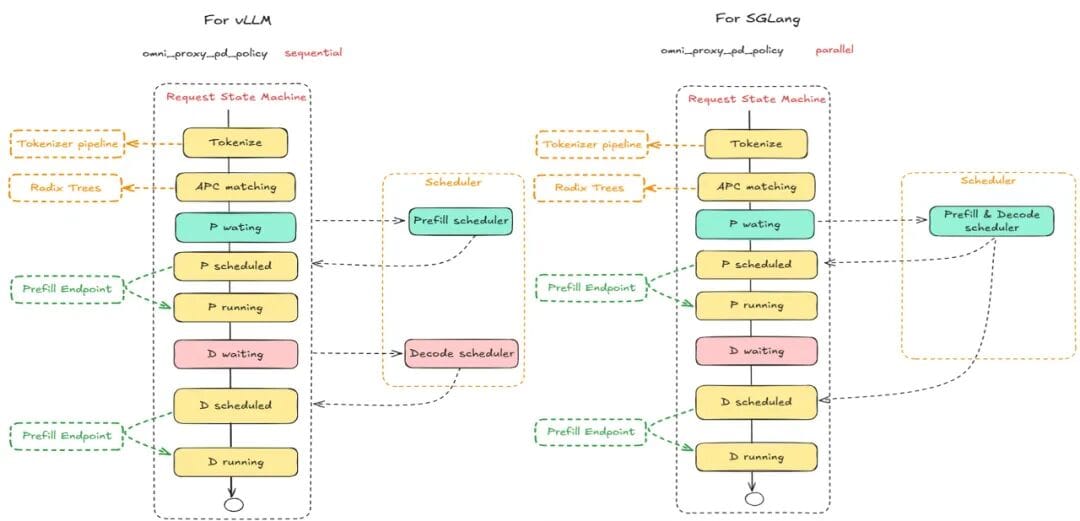
Omni Proxy vs. Traditional Scheduling
Large model inference requests face:
- Cyclic load patterns (long Prefill, short Decode cycles)
- Scheduler blind spots — missing tokenization, batch size, KV cache metrics
- Poor KV cache matching
- Duplicate tokenization in multi-node P/D setups
---
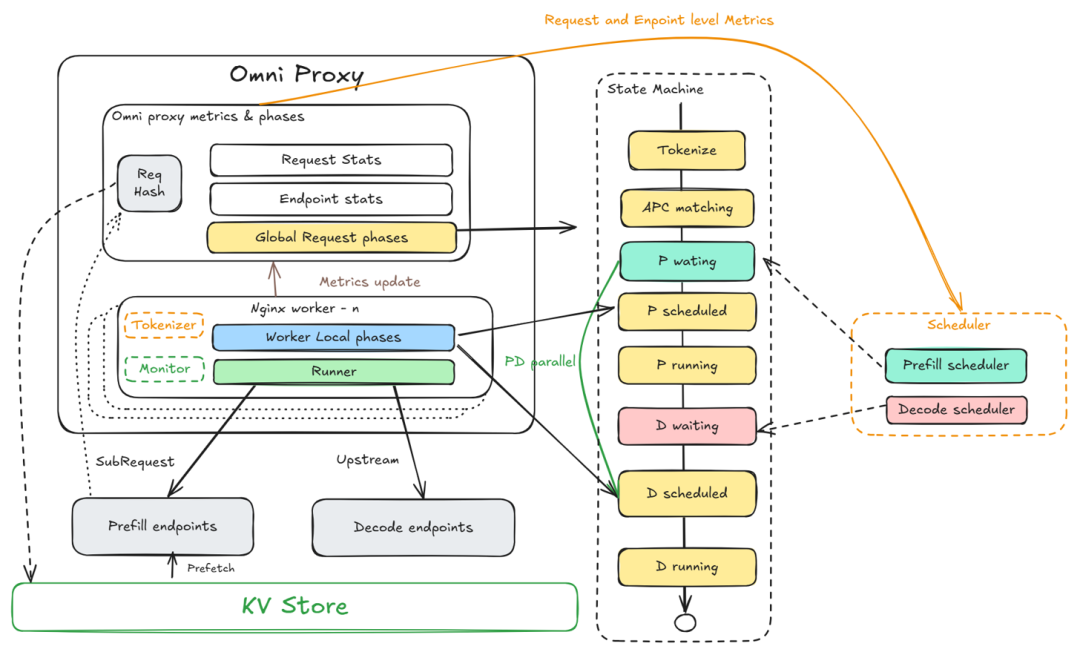
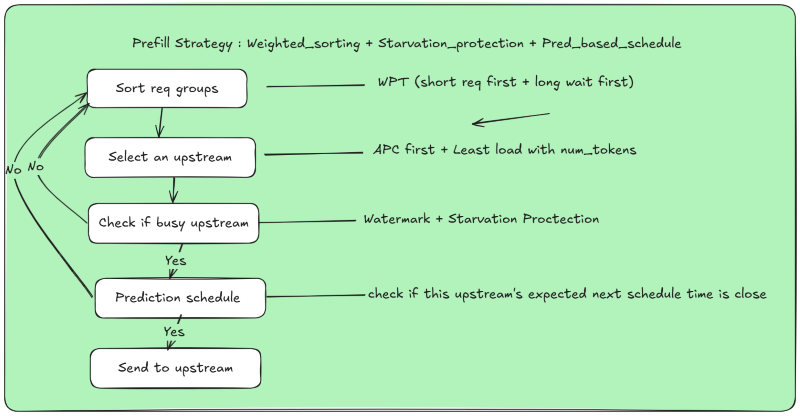
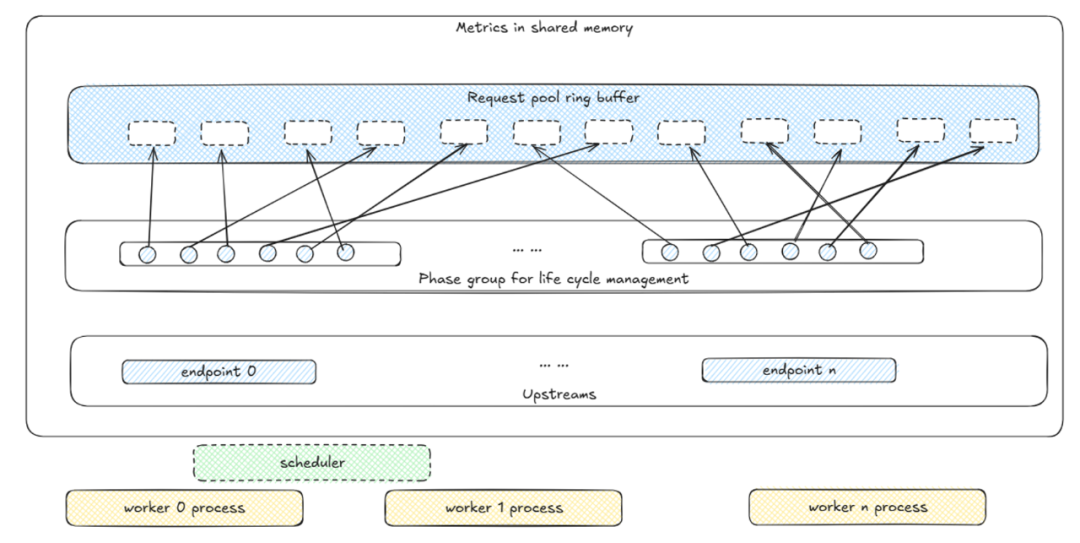
Omni Proxy — Six Key Innovations
- Full-lifecycle scheduling
- 10 stage decomposition for fine-grained control
- Dual request modes
- Sequential & parallel Prefill–Decode scheduling
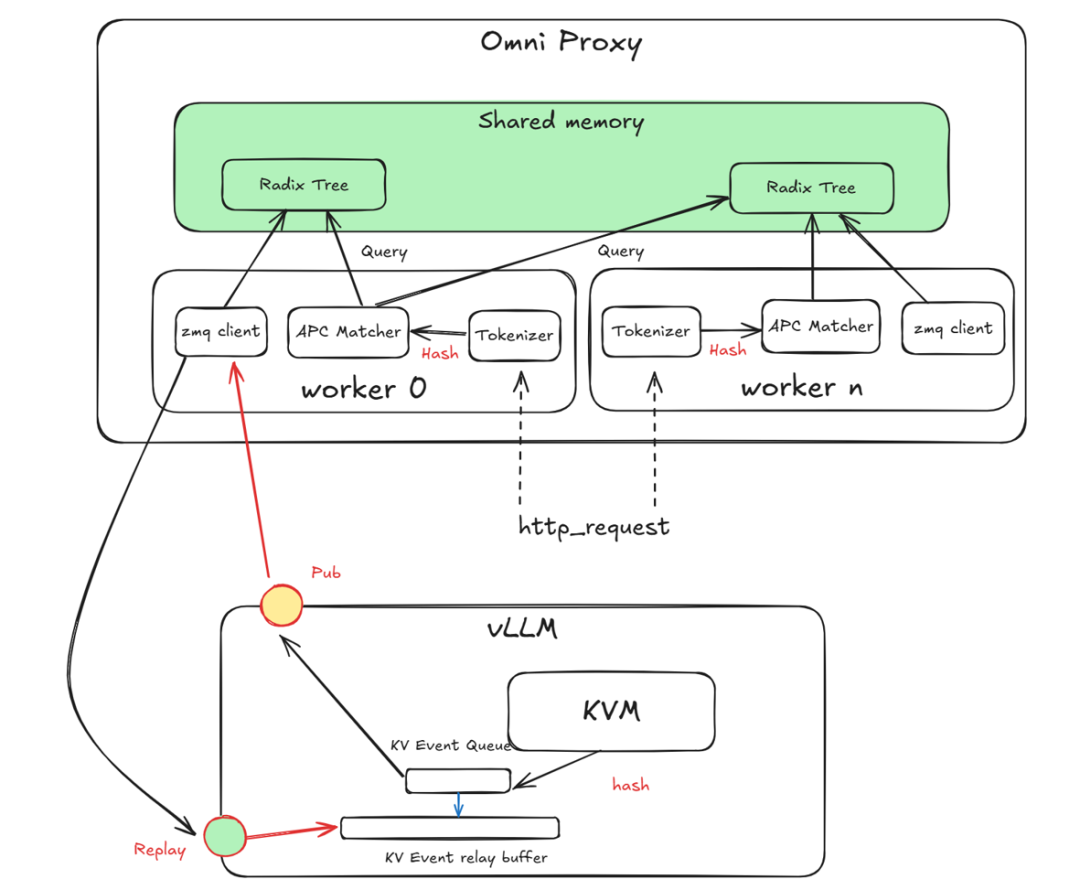
- APC-aware cache reuse
- Global KV state & precise matching
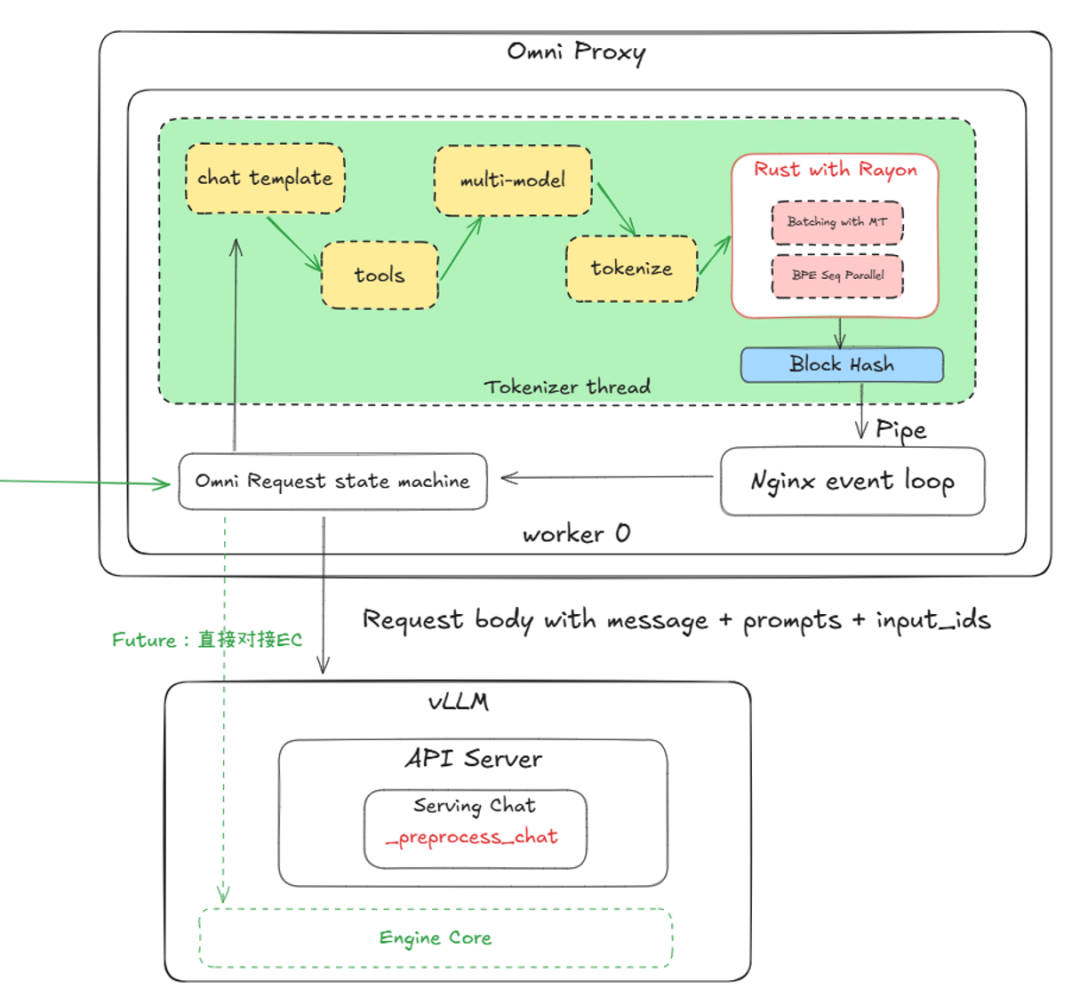
- Tokenizer result reuse
- 30% reduction in tokenizer overhead for multi-machine operations
- Weighted request sorting
- Length + wait-time balancing for throughput
- Master-slave scheduling with shared memory
- Global consistency and scalability
---
---
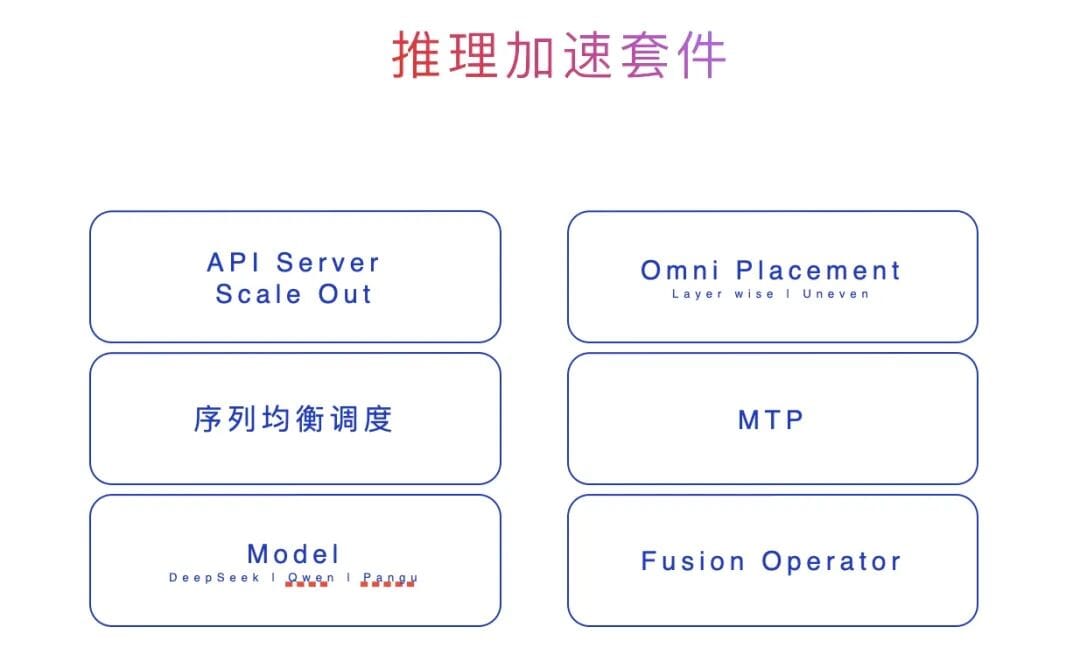
Full-Stack Inference Acceleration
Core Components
- API Server & Scale Out: Smooth cluster scaling
- Omni Placement: Expert placement for uneven cross-layer MoE configurations
- MTP (Multi-Token Prefill): Parallel multi-token generation
- Fusion Operator: Reduce redundancy via operator fusion
---
---
AMLA — Ascend Hardware FLOPS Utilization at 86%
Why It Matters
MoE inference performance = full chip utilization + operator optimization + efficient communication.
This directly impacts cost per token and system stability.
---
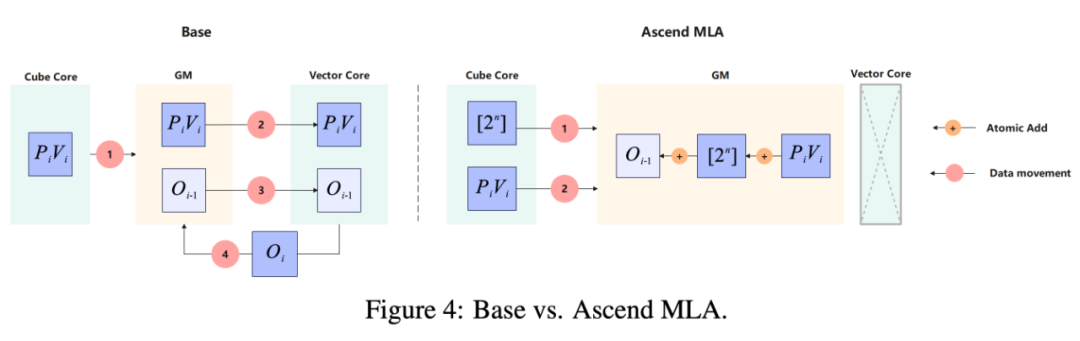
AMLA Two Breakthroughs
- Addition Instead of Multiplication
- Converts expensive FP multiplications into light INT additions
- Eliminates GM–UB roundtrips, slashing memory latency
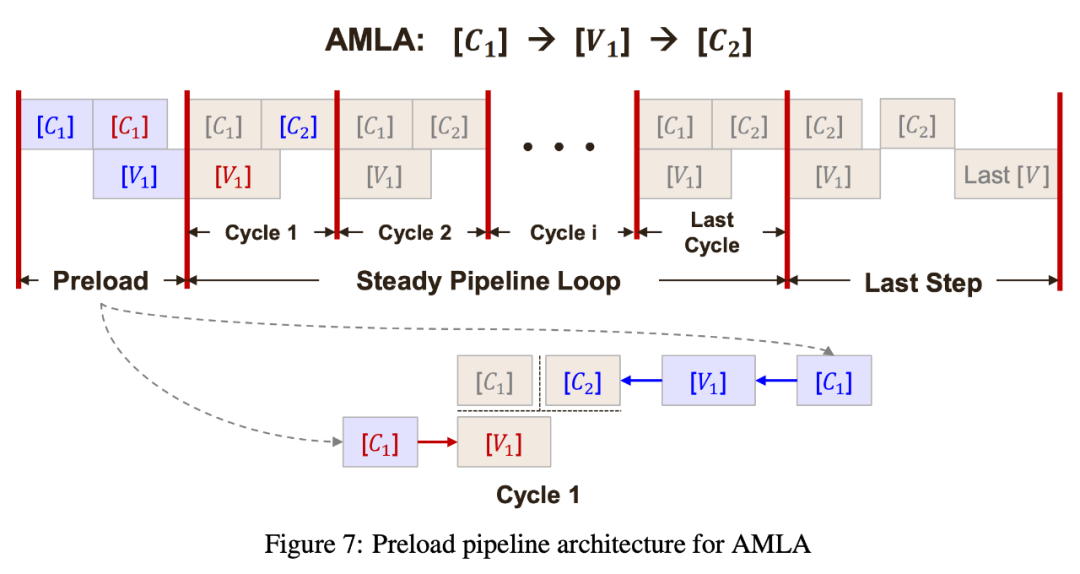
- Preload Pipelining + Hierarchical Blocking
- Cube & Vector cores operate concurrently
- Continuous data flow for max FLOPS utilization
---

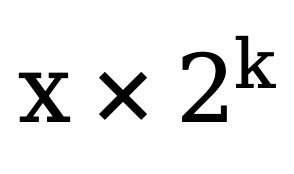
---
Performance Results
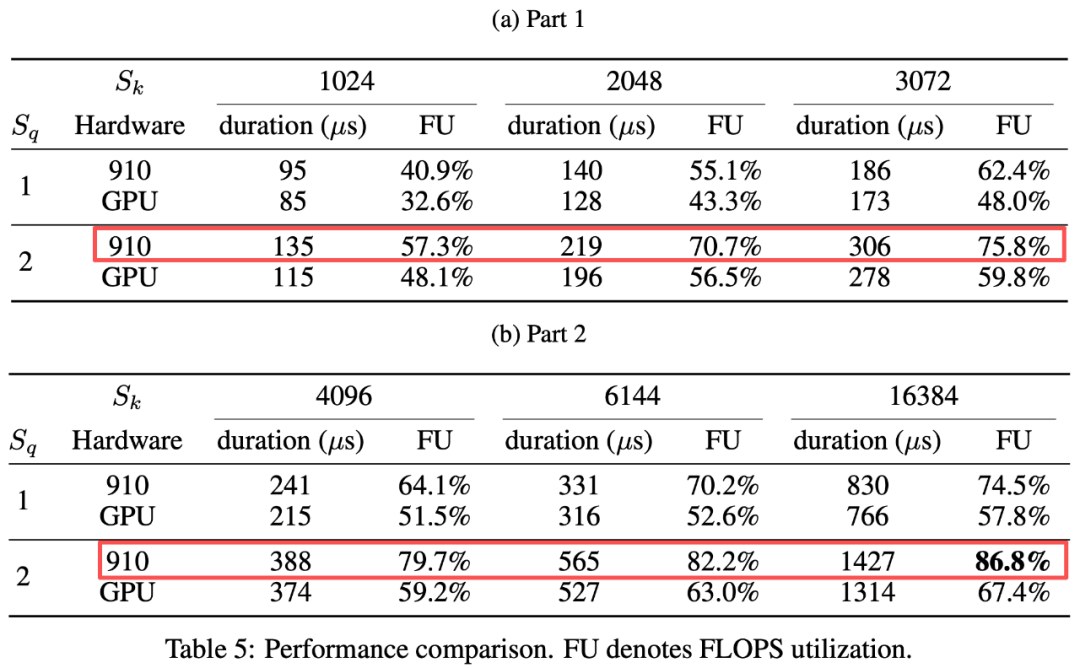
- 614 TFLOPS on Ascend hardware
- 86.8% compute utilization — near theoretical peak
- Beats open-source FlashMLA (~66.7% utilization on NVIDIA H800 SXM5)
---
Conclusion: Deployment Feasibility Achieved
Huawei’s integrated approach — OpenPangu-Ultra + Ascend Optimization Stack — combines:
- Framework-level accelerators for vLLM/SGLang
- Omni Proxy for smart scheduling
- AMLA for low-level operator performance
This achieves a balanced trifecta of:
- Cost control
- Performance stability
- Scalable deployment
---
Commercial Impact
As Scaling Law benefits plateau, optimized inference efficiency is enabling large models to reach industrial deployment scale.
Open ecosystems like AiToEarn mirror this principle — combining technical capability with operational monetization efficiency.
Creators, researchers, and enterprises now have a clear blueprint:
> Optimize both model capability and operational efficiency for sustainable success.
---
Would you like me to also create a summary infographic showing Huawei’s MoE stack architecture and the Omni Proxy + AMLA interaction for quick executive understanding? That would make this Markdown even more presentation-ready.


