HuggingFace Releases 200+ Page “Practical Guide” for Training Large Models — From Decision-Making to Deployment

AI Focus – 2025-11-09 · Beijing

A practical journey into the challenges, decisions, and messy realities of training state-of-the-art large language models (LLMs).
---
Overview
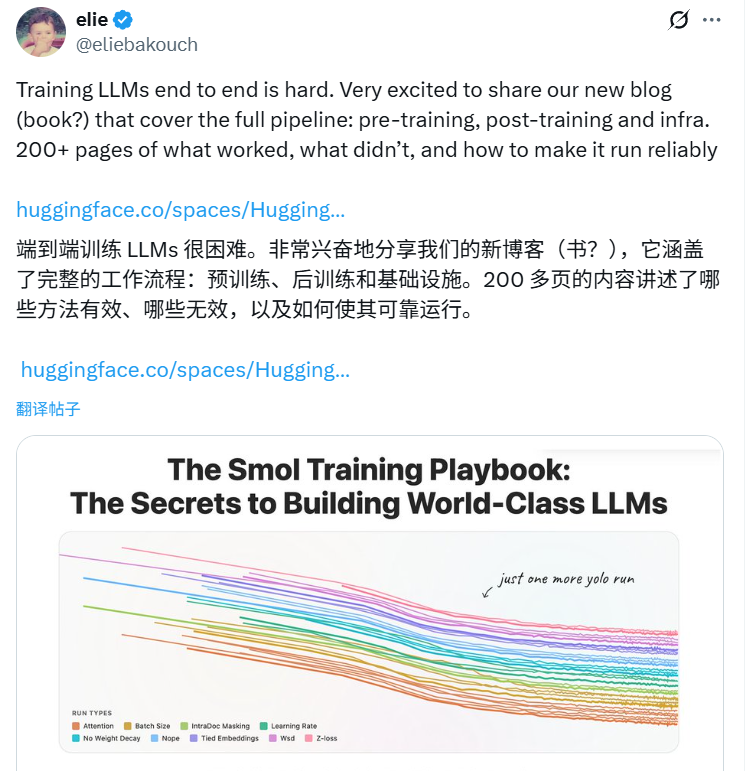
Recently, Hugging Face published an extensive 200+ page technical blog that systematically documents their end-to-end process of training advanced LLMs.
The blog focuses on the messy reality of model development, candidly sharing:
- Which methods work.
- Which ones fail.
- How to avoid common traps in large-scale engineering.
It is based on live project experience, particularly the training of the 3B-parameter SmolLM3 model using 384 H100 GPUs.
The content is rich with technical insights, code snippets, and debugging strategies, making it invaluable for anyone attempting to build an LLM.
🔗 Read full blog here: Smol Training Playbook#positional-encodings--long-context
---
Training Compass: Why → What → How

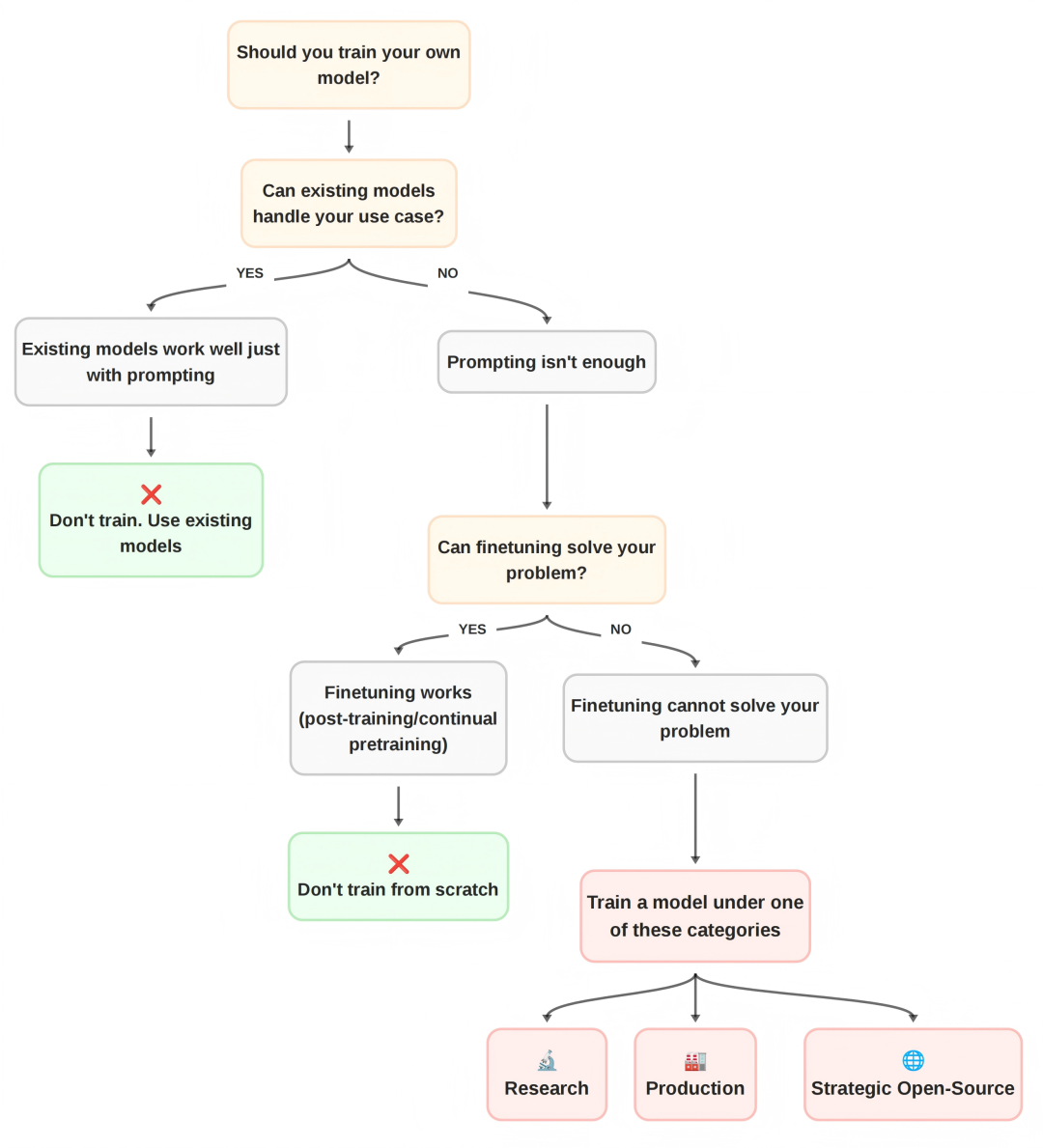
Before learning how to train, ask: Do you actually need to train a new model?
Why?
Open-source LLMs like Qwen, Gemma, and Llama are already high-quality.
Poor reasons to train a model include:
- We have idle compute.
- Everyone else is doing it.
- AI is the future.

Use Hugging Face’s decision flowchart to evaluate.
Training from scratch makes sense only if:
- No existing model fits.
- Prompt engineering doesn’t solve it.
- Fine-tuning doesn’t solve it.
Valid reasons:
- Research: Test a new optimizer, architecture, or dataset.
- Production: Handle niche vocabulary or constraints (e.g., latency, hardware limitations, regulations).
- Strategic Open Source: Fill a known gap in the ecosystem.
---
What?
Once “Why” is clear:
- Decide your model type (dense, MoE, hybrid).
- Pick size, architecture, and data mix.
Example mappings:
- Edge deployment → small, efficient models.
- Multilingual → large vocab.
- Ultra-long context → hybrid architectures.
Two decision steps:
- Planning: Map constraints to specs.
- Validation: Run experiments to verify approach.
Core team success factors:
- Rapid iteration: Quarterly model releases seem optimal.
- Data obsession: Quality beats architecture tweaks.
- Small but well-resourced teams (2–3 people initially).
---
Every Large Model Starts Small: Ablation Studies
Reasoning alone can mislead. Example:
> Using only “high-quality” arXiv papers harms small-model performance — too specialized.
Solution: Perform ablation experiments.
Key steps:
- Start from verified baseline (e.g., Llama 3.1, Qwen3).
- Modify one thing at a time, verify, integrate if beneficial.
- Choose a framework (Megatron-LM, TorchTitan, nanotron).
- Use fast, reliable experiments:
- Full-size model + small dataset.
- Smaller proxy model for huge target sizes.
- Evaluate intelligently:
- Training loss isn’t enough.
- Cloze Format often beats Multiple Choice early in training.
---
Model Architecture Design: SmolLM3 Example
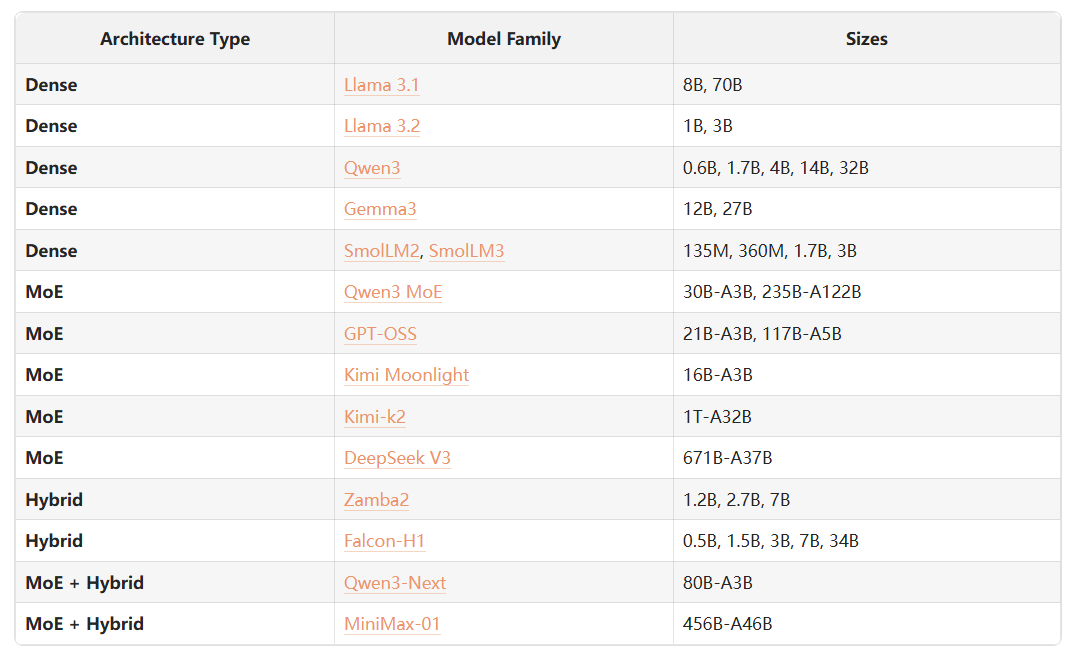
Attention Mechanism:
- MHA → high memory.
- MQA → compressed, potential loss.
- GQA → similar performance to MHA, less KV cache.
Long Context Strategies:
- Document masking — essential for packed sequences.
- Hybrid positional encoding — RNoPE + RoPE mix for balanced short/long context.
Embedding Sharing:
- More layers > bigger embedding.
- SmolLM3 shares embeddings.
Stability Enhancements:
- Remove weight decay from embedding layer.
Architecture Choice:
- Stayed dense due to memory constraints for edge deployment.
Tokenizer:
- Chose Llama3’s 128k vocab for balance and coverage.
---
The Art of Data Management
Data decides what the model learns — impact > architecture.
Modern evolution:
- From static mixes → multi-stage mixes.
- Early stage: diverse, lower-quality data (web).
- Final stage: scarce, high-value data (math, code).
Multi-stage strategy:
- Detect plateau → inject newer high-quality datasets.
Experiment types:
- From-scratch → test initial mixes directly.
- Annealing → resume from checkpoint with altered mixes.
---
Training as a "Marathon"
Once architecture, data, and hyperparameters are settled:
- Conduct preflight checks (infra, eval systems, recovery).
- Be ready for debugging throughput loss, noisy loss curves, etc.
Example — SmolLM3 training used:
- Multi-stage curriculum: general → reasoning → long-context.
- Dynamic adjustments guided by monitoring.
---
Post-Training Phase
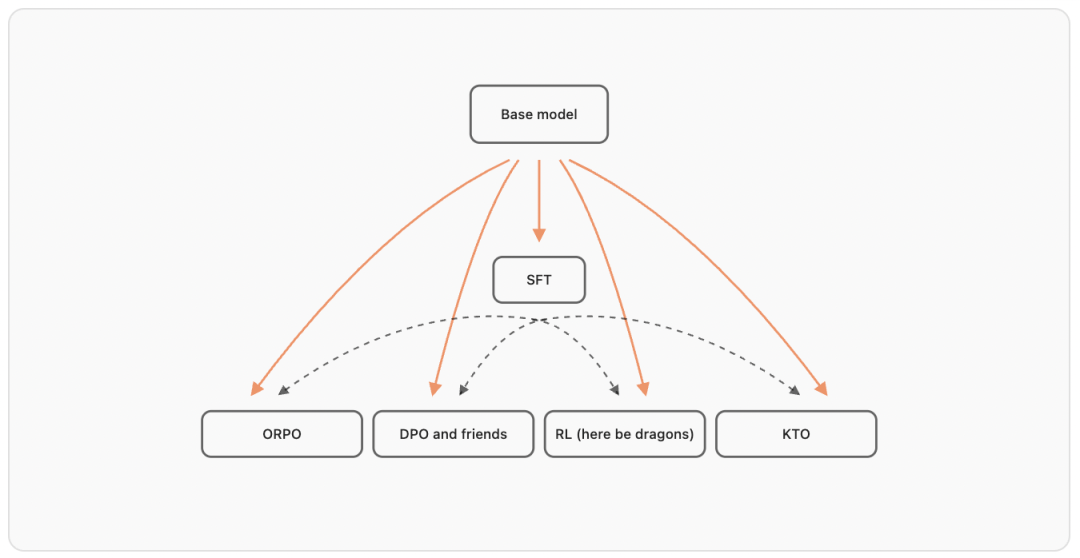
Ask first:
- Do you really need post-training?
- Do you have quality domain data?
- Can you measure success?
Goals define paths:
- Strict assistant?
- Tone-flexible helper?
- Reasoning/maths specialist?
- Multilingual conversationalist?
Phases:
- Supervised Fine-Tuning (SFT) — cost-effective and stable baseline.
- Preference Optimization (PO).
- Reinforcement Learning (RL).
- Ongoing evaluation + curation.
Framework choice impacts all stages.
---
Infrastructure — The Hidden Hero
Training SmolLM3:
- 384 H100 GPUs
- ~11 trillion tokens
- ~4 weeks runtime
Infrastructure essentials:
- GPU procurement and readiness.
- CPU–GPU communication optimization.
- Health monitoring throughout (GPU Fryer, NVIDIA DCGM).
GPU count formula:
- Balances FLOPs, throughput, target duration.
- Example: SmolLM3 yielded ~379 GPUs; used 384 to allow fault tolerance.
---
Final Takeaways
SmolLM3’s successes relied on:
- Clear why, tailored what, proven how.
- Relentless ablation testing.
- Strategic multi-stage data mix.
- Stable infrastructure and iteration speed.
The lessons here benefit any complex AI pipeline.
If deploying or monetizing outputs, open platforms like AiToEarn can bridge training → publishing → analytics → monetization across major global channels.
---