Hunyuan OCR Model Goes Open Source: Just 1B Parameters, Multiple Core Capabilities Achieve SOTA

HunyuanOCR — Tencent’s Self-Developed OCR Model
On November 25th, Tencent Hunyuan launched HunyuanOCR, a compact yet powerful open-source OCR model with only 1 billion parameters. Built on Hunyuan’s native multimodal architecture, it delivers industry-leading SOTA (state-of-the-art) results in OCR application benchmarks.

---
Key Features
Compact, Efficient, Easy to Deploy
- Small model size — suitable for deployment in diverse environments.
- End-to-end design — each task requires just a single forward pass, enabling higher efficiency compared to traditional multi-stage pipelines.
- High cost-effectiveness — reduced computational overhead and faster inference speeds.
Architecture Overview
HunyuanOCR’s expert model is composed of:
- Native resolution video encoder
- Adaptive vision adapter
- Lightweight Hunyuan language model
End-to-End Training and Inference
- Fully end-to-end pipeline — from image input to OCR output without cascaded modules.
- Trained on large-scale, high-quality data with online reinforcement learning.
- Strong end-to-end reasoning capabilities, enhancing recognition accuracy in complex scenarios.

---
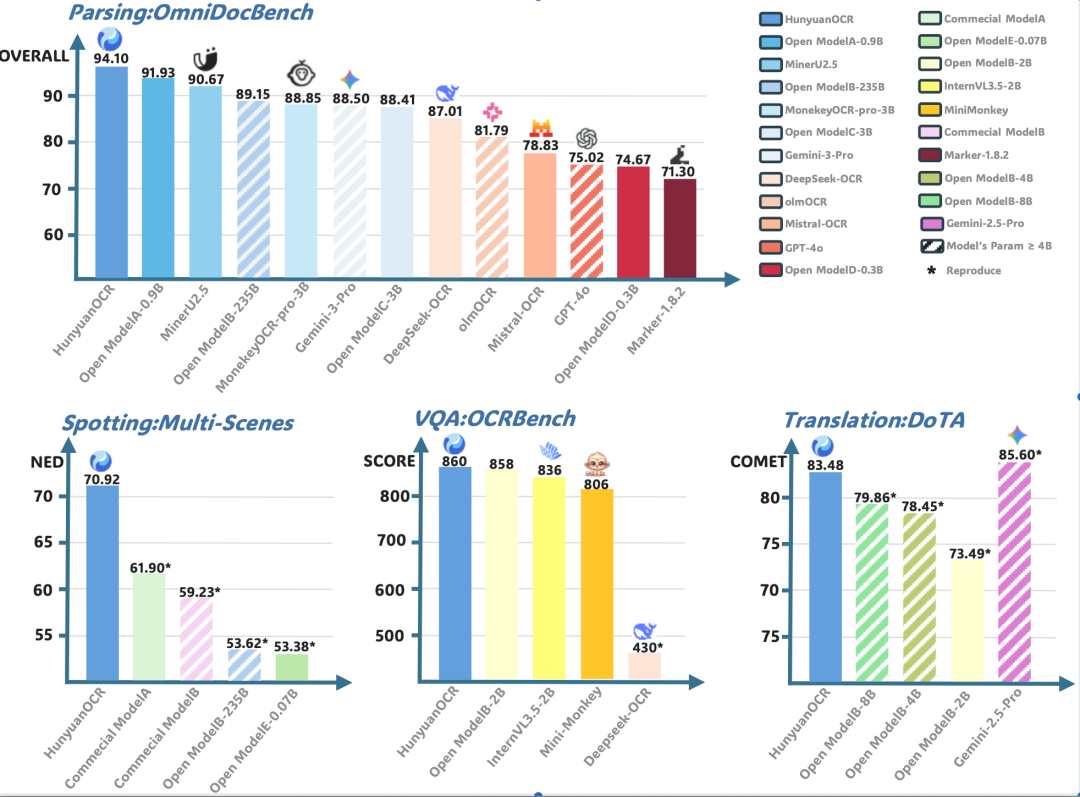
Benchmark Results
- OmniDocBench — 94.1 points, surpassing Google Gemini3-pro and other top models in complex document parsing.
- OCRBench leaderboard — 860 points with just 1B parameters, ranking #1 among all models under 3B parameters.
- Multi-scenario text detection & recognition — excels in documents, artistic text, street scenes, handwriting, ads, receipts, screenshots, games, videos.
- Language translation — 14 small-language → Chinese/English translations; ICDAR2025 End-to-End Document Translation (small model track) — 1st place.
---
Application Scenarios
1. Complex Multi-language Document Parsing
- Converts scanned or photographed multi-language documents into digital text.
- Outputs in structured formats — reading order text, LaTeX for equations, and HTML tables.

2. Receipt & Document Field Extraction
- Extracts key fields (Name, Address, Organization) from cards, certificates, receipts.
- Delivers results in standardized JSON format.

3. Automated Subtitle Extraction
- Recognizes and extracts subtitles from video frames, including bilingual subs.

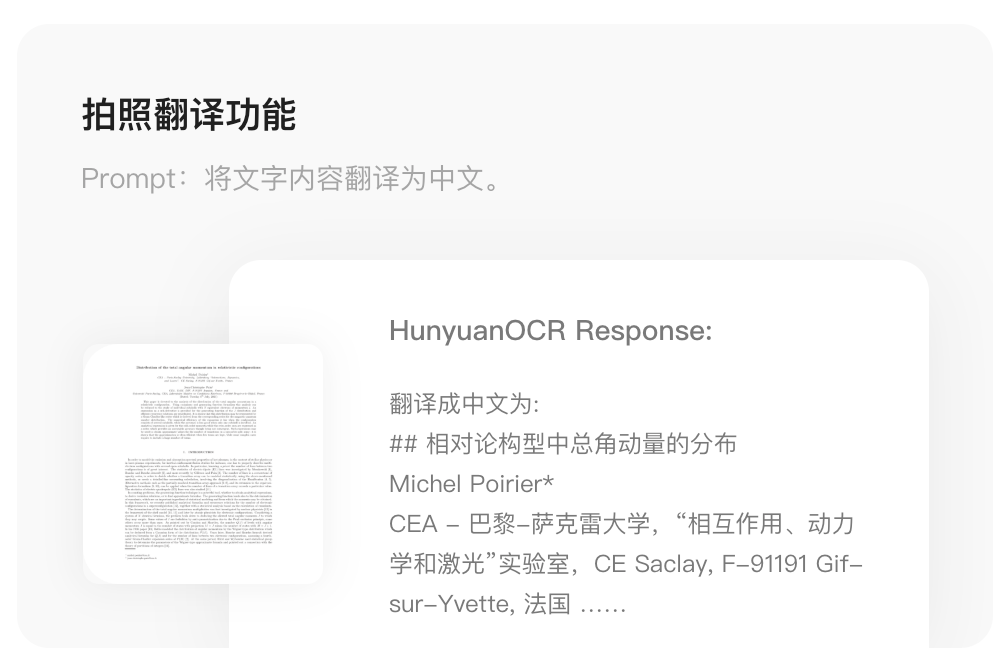
4. Instant Photo Translation
- Translates from 14 small languages (German, Spanish, Turkish, Italian, Russian, French, Portuguese, Arabic, Thai, Vietnamese, Indonesian, Malay, Japanese, Korean) to Chinese/English.
- Supports bidirectional Chinese↔English translation.
---
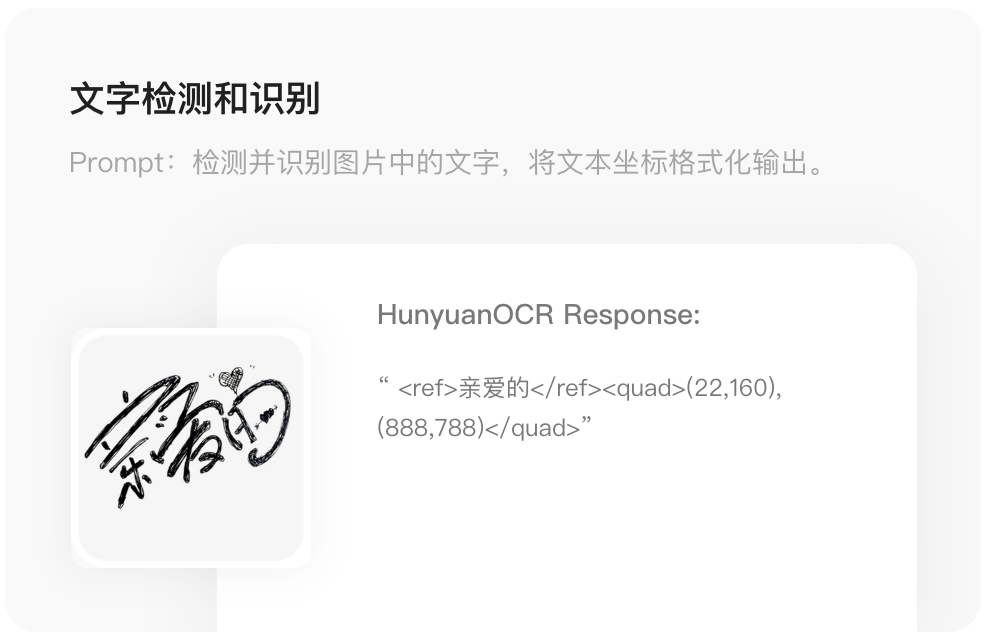
Supported Text Detection & Recognition Scenarios
- Documents
- Artistic text
- Street scenes
- Handwriting
- Advertising text
- Receipts
- Screenshots
- Game text
- Video subtitles
---
Project Links
- Web: https://hunyuan.tencent.com/vision/zh?tabIndex=0
- Mobile: https://hunyuan.tencent.com/open_source_mobile?tab=vision&tabIndex=0
- GitHub Repo: https://github.com/Tencent-Hunyuan/HunyuanOCR
- Hugging Face Model: https://huggingface.co/tencent/HunyuanOCR
- Online Demo: https://huggingface.co/spaces/tencent/HunyuanOCR
Click Read Original to view the full technical report.
---
Integration with AiToEarn
In the broader AI ecosystem, platforms like AiToEarn官网 enable creators to:
- Integrate AI models (including OCR systems like HunyuanOCR) into cross-platform publishing workflows.
- Automate content distribution to Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
- Access analytics and model ranking via AI模型排名.
- Learn more through AiToEarn博客.
This synergy allows creators to turn OCR-generated and translated content into monetizable multi-platform assets quickly and efficiently.
---
✅ Tip: If you'd like, I can also create a quick-start installation guide in Markdown for HunyuanOCR so readers can use it immediately. Would you like me to prepare that next?


