Hunyuan OCR Model Open-Sourced with Just 1B Parameters, Achieves Multiple SOTA Capabilities

🚀 Hunyuan's Self-Developed OCR Model is Live
On November 25, Tencent Hunyuan launched its open-source OCR expert model — HunyuanOCR.
- Model Size: Only 1B parameters
- Architecture: Native multimodal
- Performance: Achieved multiple SOTA (state-of-the-art) results across industry OCR benchmarks

---
📈 High Usability & Efficiency
HunyuanOCR is compact, easy to deploy, and powered by Hunyuan’s native multimodal large model design — enabling:
- Single forward inference for all features
- Faster & more convenient compared to cascaded solutions
- Strong cost-performance advantages
---
🏗 Model Architecture
HunyuanOCR’s architecture consists of three main components:
- Native-resolution video encoder
- Adaptive vision adapter
- Lightweight Hunyuan language model
Key Difference: Unlike other open-source OCR models, HunyuanOCR uses a true end-to-end paradigm for both training and inference, powered by:
- Large-scale, high-quality, application-oriented data
- Online reinforcement learning
- Robust end-to-end reasoning capabilities

---
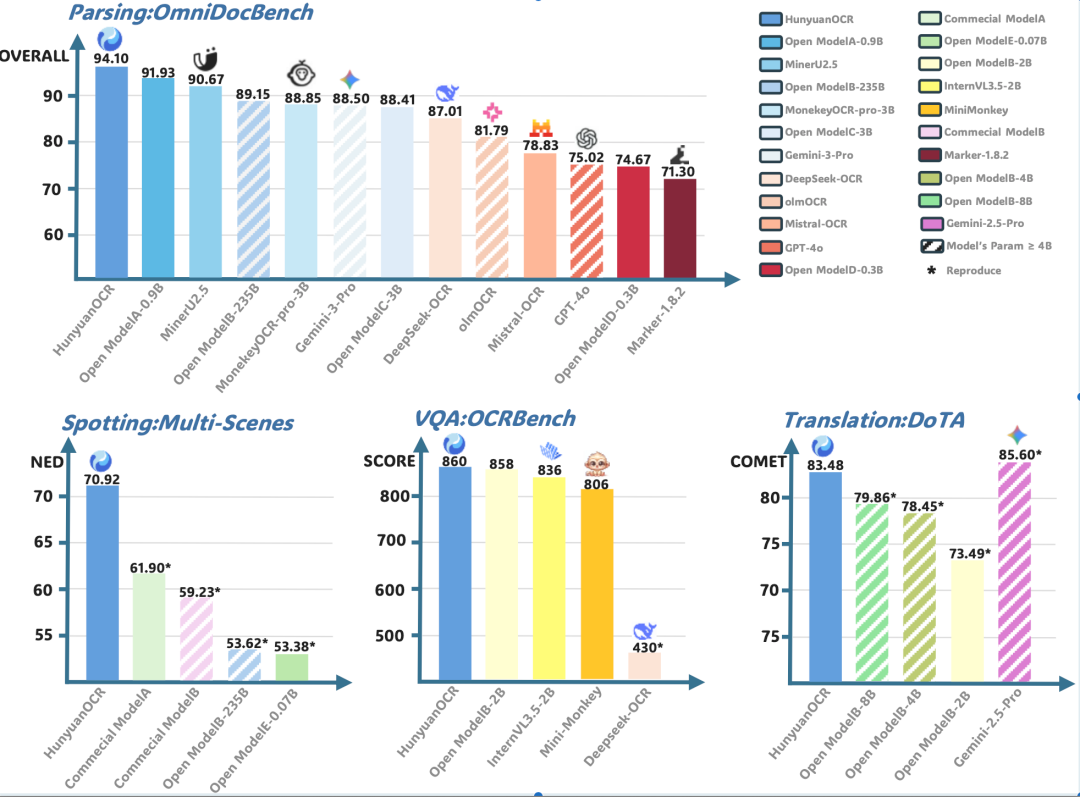
📊 Core Capabilities & Benchmark Performance
✅ Performance Highlights:
- OmniDocBench (Complex Document Parsing)
- Score: 94.1 — highest to date, surpassing Google’s Gemini3-pro
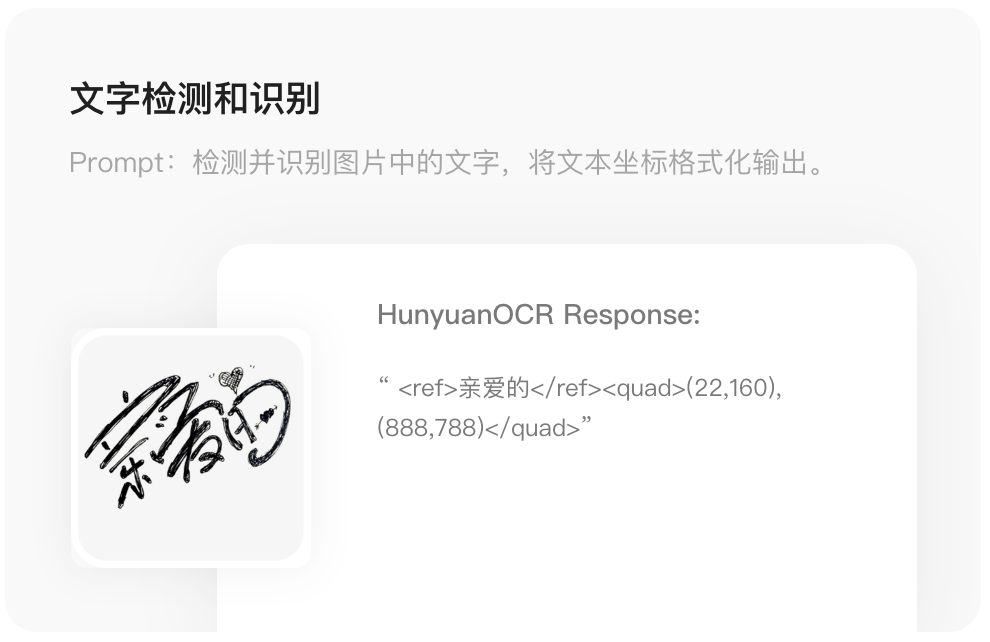
- Text Detection & Recognition
- Outperforms comparable open-source and commercial OCR models across 9 major scenarios:
- Documents
- Artistic text
- Street scenes
- Handwriting
- Advertisements
- Receipts
- Screenshots
- Games
- Videos
- OCRBench Ranking
- Score: 860 points
- SOTA among all models under 3B parameters
- Minor Language Translation
- Supports 14 high-frequency languages → Chinese/English translation
- Champion in ICDAR2025 Small-Model End-to-End Document Translation Competition
---
🌍 Application Scenarios
HunyuanOCR delivers accurate multilingual document parsing and strong text detection capabilities for scenarios such as:
- Receipt field extraction
- Video subtitle recognition
- Photo translation
Text Detection & Recognition Coverage
Documents | Artistic fonts | Street scenes | Handwriting | Advertisements | Receipts | Screenshots | Games | Videos
What is Complex Document Parsing?
It is the process of digitizing multilingual scanned or photographed documents:
- Organizing text by reading order
- Converting formulas to LaTeX
- Representing complex tables in HTML

---
📌 Common Use Cases
- Receipt & Certificate Field Extraction
- Structure data in standardized JSON format
- Video Subtitle Auto-Extraction
- Supports bilingual subtitle parsing


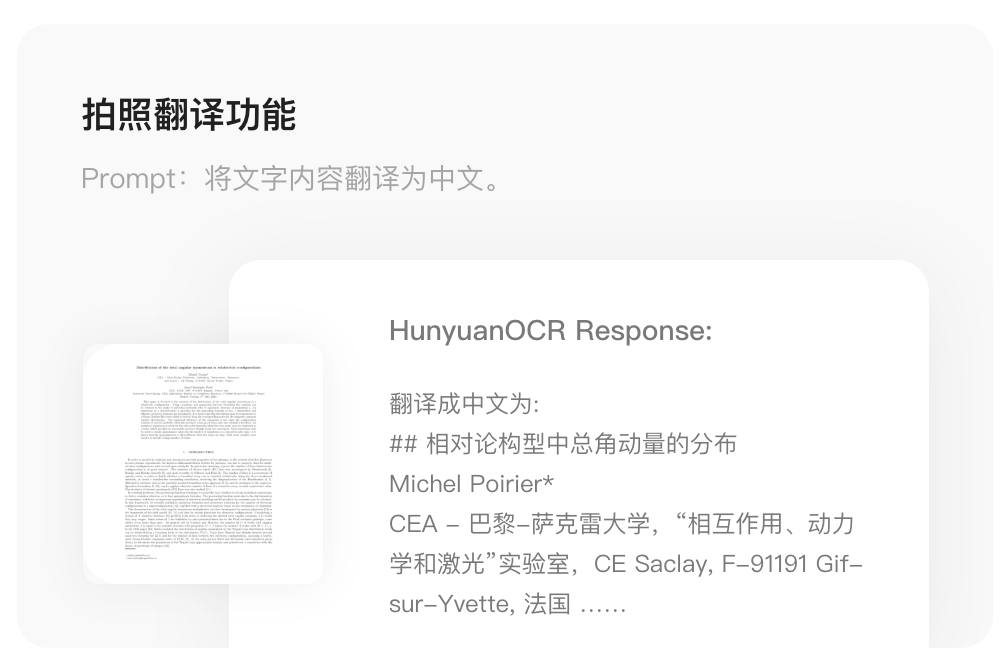
- Photo Translation
- Supports 14 languages: German, Spanish, Turkish, Italian, Russian, French, Portuguese, Arabic, Thai, Vietnamese, Indonesian, Malay, Japanese, Korean
- Translates into Chinese/English with bidirectional Chinese-English support
---
🔗 Resources & Links
Official Web Demos
- Web: https://hunyuan.tencent.com/vision/zh?tabIndex=0
- Mobile: https://hunyuan.tencent.com/open_source_mobile?tab=vision&tabIndex=0
Open Source Repository
ModelScope
---
💡 Extended Ecosystem for Creators
As AI content creation tools become more powerful, models like HunyuanOCR show how specialized AI can be efficiently deployed at scale.
For creators looking to integrate AI-driven workflows — from OCR data extraction to multilingual publishing — AiToEarn官网 provides:
- Open-source platform for generation → publishing → monetization
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Analytics & model ranking integration
This ecosystem makes it easier to turn OCR outputs into content ready for global audience distribution.
---
💬 Tip: Click “Read Original” for direct access to the model link.
---
If you want, I can follow up by adding a side-by-side comparison table of HunyuanOCR vs other OCR models for quick reference. Would you like me to prepare that?


