# Tencent HunyuanOCR — Achieving Multiple Industry-Leading SOTA in OCR Benchmarks
**Date:** 2025-11-25 20:24 Zhejiang

Tencent Hunyuan has officially released its **self-developed OCR model**, achieving multiple **State-of-the-Art (SOTA)** results in leading OCR application benchmarks.
---
## 🆕 Introduction to HunyuanOCR
On **November 25**, Tencent Hunyuan launched the open-source **HunyuanOCR** model:
- **1B parameters** — small yet powerful
- **Native multimodal architecture** — built from the ground up for integrated vision and language processing
- Achieved **SOTA** results across multiple OCR benchmarks

### Key Advantages
- **Compact size** — easy deployment across devices
- **End-to-end architecture** — all functions use **single forward inference**
- **Efficiency over cascaded solutions** — reduces complexity and cost
- **Native multimodal design** — consistent and optimized results
---
## 🔍 Architecture
The **HunyuanOCR expert model** consists of:
1. **Native-resolution video encoder**
2. **Adaptive visual adapter**
3. **Lightweight Hunyuan language model**
Unlike traditional cascaded OCR systems, HunyuanOCR:
- Uses **fully end-to-end** training and inference
- Leverages **large-scale, high-quality, application-oriented data**
- Employs **online reinforcement learning**
- Provides robust and stable **end-to-end reasoning**

---
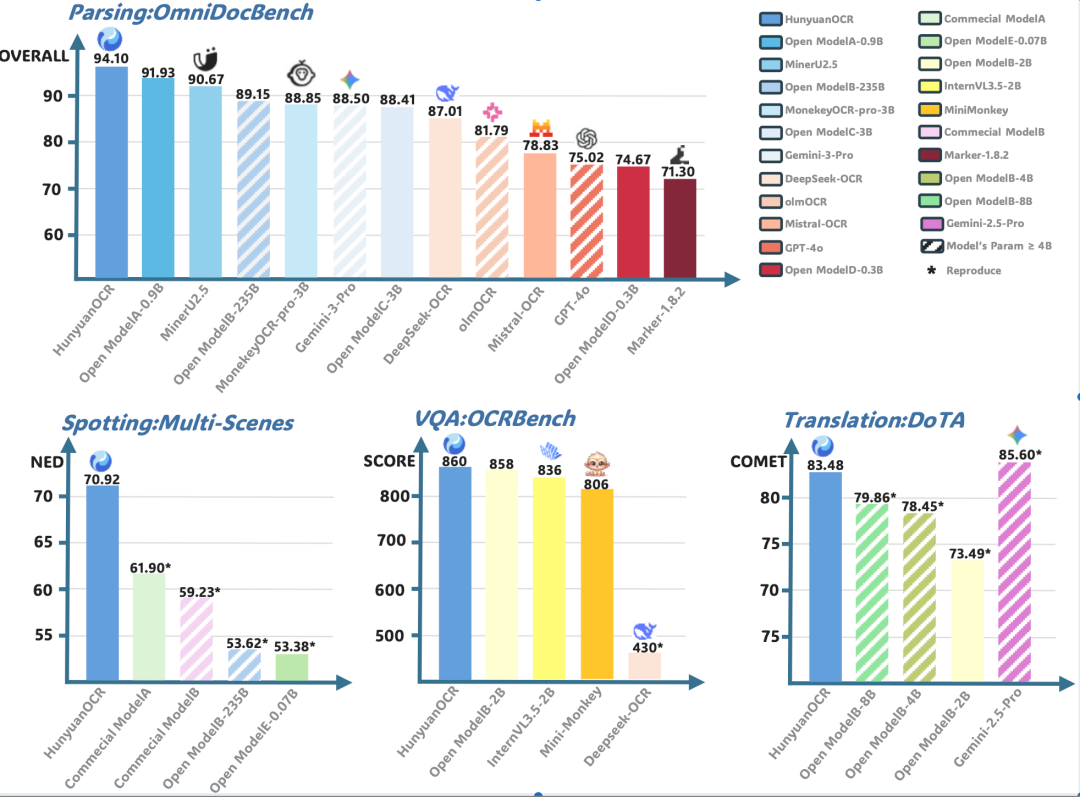
## 📊 Benchmark Results
**Core Capabilities:**
- **OmniDocBench** (complex document parsing): **94.1 score** — exceeds Google Gemini3-pro
- **Text detection & recognition**: Self-built benchmark across 9 major scenarios
- **OCRBench leaderboard** (models under 3B parameters): **860 score** with only 1B parameters
- **Low-resource language translation**: Supports 14 languages; **ICDAR2025 winner** in small-model track
**Coverage of 9 Major Scenarios:**
- Documents
- Art text
- Street scenes
- Handwriting
- Advertising
- Receipts
- Screenshots
- Games
- Videos
---
## 🌏 Language Translation
HunyuanOCR supports **bidirectional translation** between **Chinese/English** and **14 high-frequency languages**:
German, Spanish, Turkish, Italian, Russian, French, Portuguese, Arabic, Thai, Vietnamese, Indonesian, Malay, Japanese, Korean.
---
## 💼 Application Scenarios
### 1. Complex Multilingual Document Parsing
Digitizes scanned or photographed documents:
- Respects **reading order**
- Uses **LaTeX** for formulas
- Uses **HTML** for complex tables

### 2. Receipt Field Extraction
Extracts key fields (name, address, organization) from documents like IDs or receipts into **standard JSON** format.

### 3. Video Subtitle Extraction
Automatically detects and extracts **single-language or bilingual subtitles**.

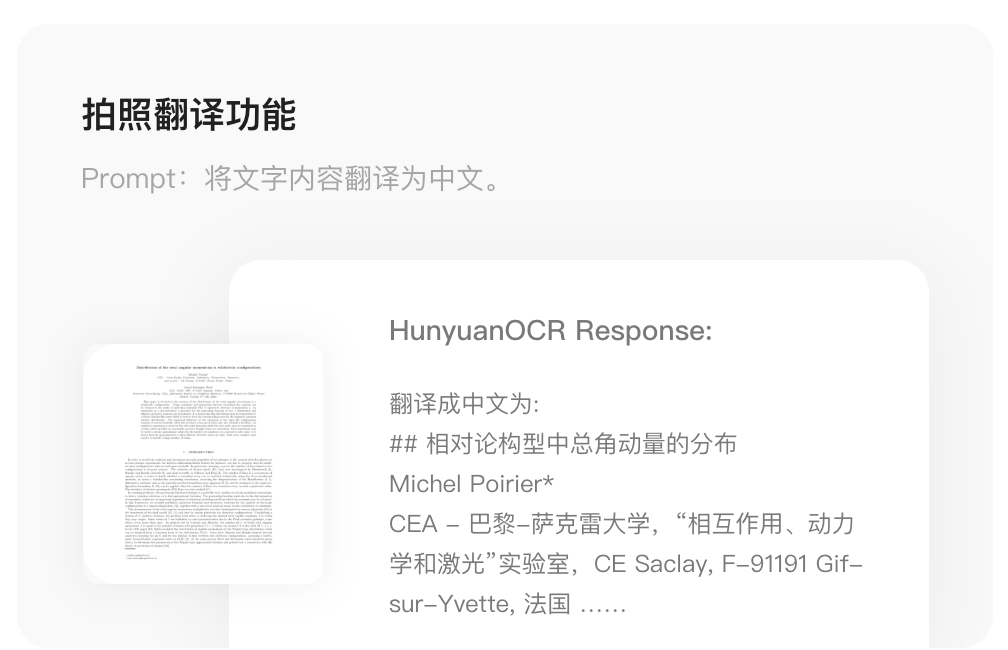
### 4. Photo Translation
Supports on-the-fly multilingual translation from images.
---
## 📥 Download & Try
- **Web:** [https://hunyuan.tencent.com/vision/zh?tabIndex=0](https://hunyuan.tencent.com/vision/zh?tabIndex=0)
- **Mobile:** [https://hunyuan.tencent.com/open_source_mobile?tab=vision&tabIndex=0](https://hunyuan.tencent.com/open_source_mobile?tab=vision&tabIndex=0)
**Open Source Repositories:**
- GitHub: [https://github.com/Tencent-Hunyuan/HunyuanOCR](https://github.com/Tencent-Hunyuan/HunyuanOCR)
- ModelScope: [https://modelscope.cn/models/Tencent-Hunyuan/HunyuanOCR](https://modelscope.cn/models/Tencent-Hunyuan/HunyuanOCR)
**Official Links:**
[Read Original](https://modelscope.cn/models/Tencent-Hunyuan/HunyuanOCR)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=98d7bb3a&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzk3NTc1NTU0Mw%3D%3D%26mid%3D2247502657%26idx%3D1%26sn%3D81f4a7251540a32b57530f34a1db70ef)
---
## 🚀 Related Platform — AiToEarn
For creators and developers integrating OCR into their workflow, **[AiToEarn](https://aitoearn.ai/)** offers:
- **Open-source global AI content monetization**
- Multi-platform publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Integrated **AI generation, publishing, analytics, and model ranking**
Explore AiToEarn:
- Blog: [AiToEarn博客](https://blog.aitoearn.ai)
- Model ranking: [AI模型排名](https://rank.aitoearn.ai)
- GitHub: [https://github.com/yikart/AiToEarn](https://github.com/yikart/AiToEarn)
---



