ICCV 2025 | Zhejiang University and CUHK Propose EgoAgent: An Integrated First-Person Perception-Action-Prediction Agent

EgoAgent: A New Paradigm in AI Learning
Date: 2025-10-16 12:49 (Beijing)
---


Overview
How can we make AI understand the world naturally, as humans do — through observation and interaction?
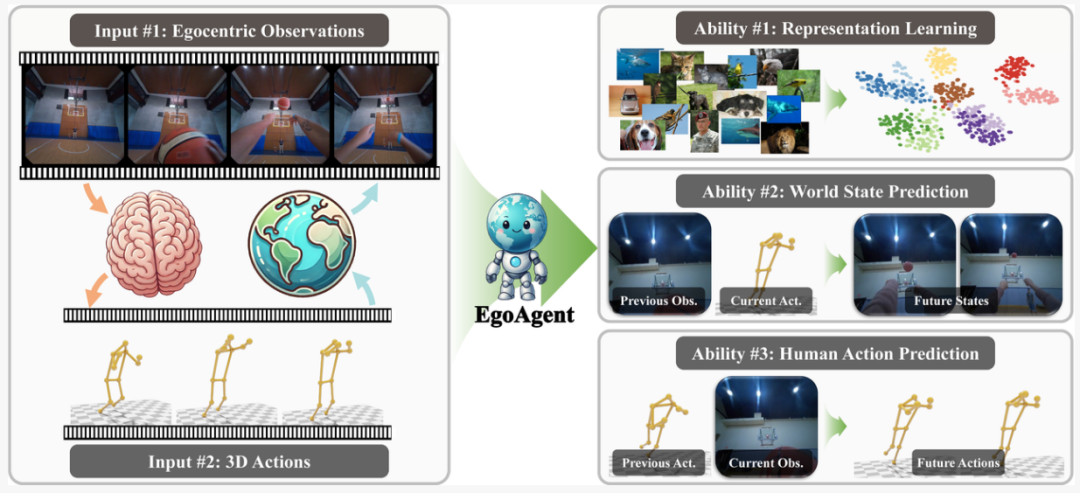
At ICCV 2025, a collaboration between Zhejiang University, The Chinese University of Hong Kong, Shanghai Jiao Tong University, and Shanghai Artificial Intelligence Laboratory introduced EgoAgent, the first egocentric joint predictive agent.
Inspired by human cognitive learning and Common Coding Theory, EgoAgent is the first model to learn visual representation, human action, and world state prediction in a unified latent space — breaking the conventional AI separation of perception, control, and prediction.
By adopting this joint learning approach, EgoAgent achieves synergy across tasks and can transfer its capabilities to embodied operation tasks.

---
Publication Details
- Paper Title: EgoAgent: A Joint Predictive Agent Model in Egocentric Worlds
- Conference: ICCV 2025
- Project Page: https://egoagent.github.io
- Paper Link: https://arxiv.org/abs/2502.05857
- Code Repository: https://github.com/zju3dv/EgoAgent
---
Inspiration: Human Embodied Cognition
The Basketball Analogy
When you play basketball, you:
- Perceive the ball’s position.
- Instantly decide to jump or block.
- Predict how your actions will change the game environment.
This cycle — perceive → act → predict — begins in infancy, long before language acquisition. Humans develop a visual–motor system that enables them to understand and influence their surroundings through perception and action alone.
---
Cognitive Theory Link
Based on Embodied Cognition and Common Coding Theory, perception and action share a representational space, mutually reinforcing each other. EgoAgent simulates this continuous interplay:
- Seeing images.
- Experiencing the world.
- Predicting the future.
- Taking action and observing its environmental impact.
---
Technical Insight: “1 + 1 + 1 > 3”
The Problem with Traditional Models
- Tasks for perception, action, and prediction are trained separately.
- Intrinsic task connections are lost.
EgoAgent’s Solution
EgoAgent trains jointly on large-scale first-person view videos aligned with 3D human motion capture data, retaining strong coupling between perception, action, and prediction — mirroring human cognition.
---
Link to AI Creative Ecosystems
EgoAgent’s multi-task unification parallels new AI content workflows, such as AiToEarn官网, which helps creators:
- Generate AI content.
- Publish across platforms (Douyin, Kwai, Bilibili, etc.).
- Monetize effectively.
Its ecosystem — AiToEarn博客, AiToEarn文档, AI模型排名 — aligns with EgoAgent’s cross-domain integration idea.
---
JEAP: Core Architecture of EgoAgent
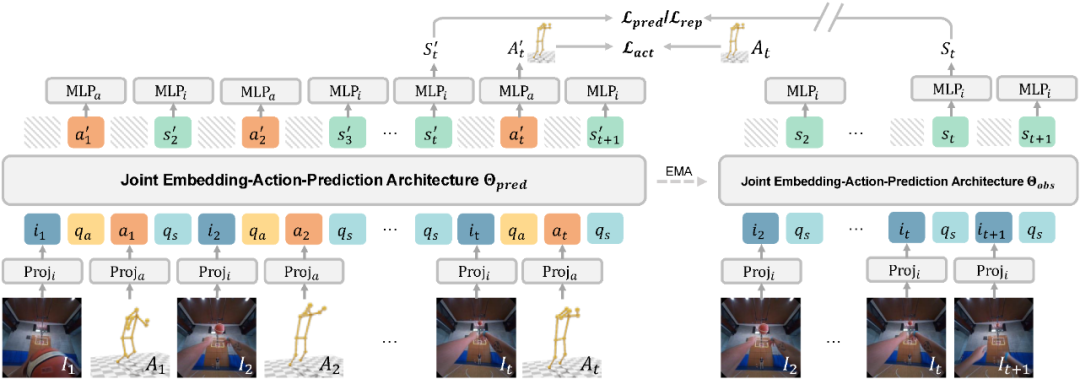
Key Components
1. Interleaved “State–Action” Prediction
- Encodes first-person frames and 3D actions alternately: `state → action → state → action`.
- Models the sequence with Transformer causal self-attention.
- Captures bidirectional temporal relations:
- Perception → Action.
- Action → Future state changes.
2. “Prophet” and “Observer” Collaboration
- Predictor: Forecasts future states and actions.
- Observer: Encodes only future frames to provide target supervision.
- Uses Teacher–Student EMA updating.
Benefits:
- Supports temporal self-supervised learning and static image contrastive learning.
- Enhances representation stability.
3. Query Tokens
- Learnable prompts in both branches.
- Guide attention for specific tasks.
- Decouple task gradients to avoid interference.
4. Semantic Embedding Space Learning
- Learns high-level semantic concepts instead of pixel reconstruction.
- Closer to human reasoning.
- Improves future state prediction and representation quality.
---
Capability Demonstrations & Analysis
First-Person World State Prediction
- Predicts future world state features from past visuals + actions.
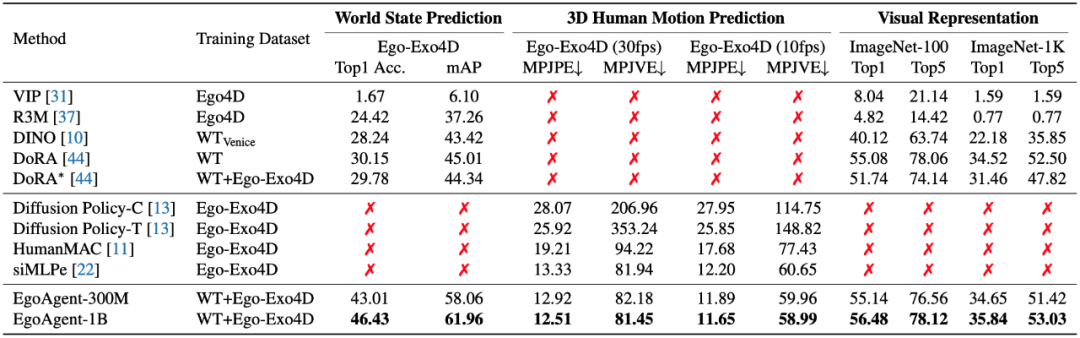
- Evaluated via retrieval accuracy.
- Outperforms DoRA (ICLR 2024):
- +12.86% (Top-1)
- +13.05% (mAP)
- Scaling to 1B parameters boosts results further.

---
3D Human Motion Prediction
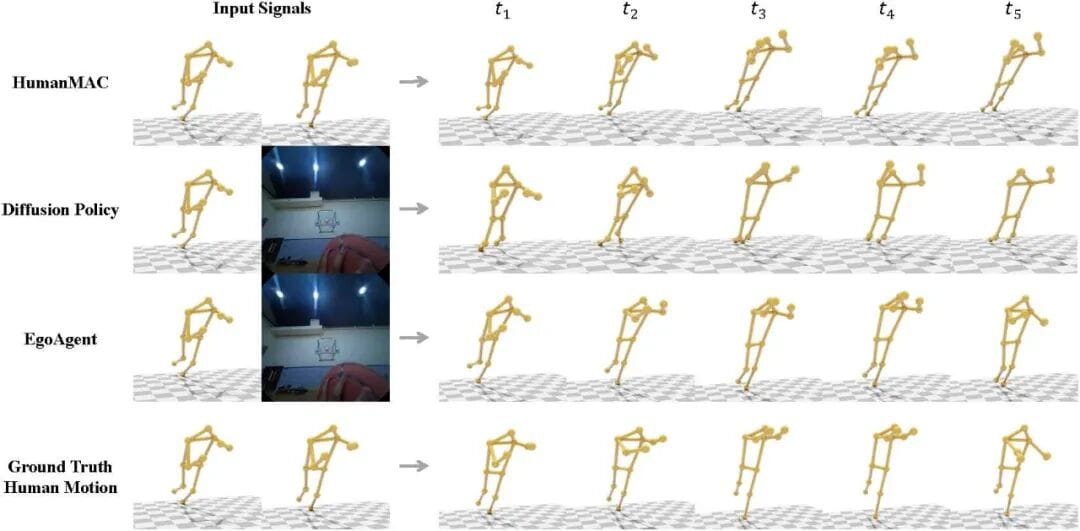
EgoAgent forecasts realistic 3D human motion using first-person views + historic actions.
- Lowest MPJPE in benchmark tests.
- Accurate joint prediction even for unseen joints.
---
Visual Representations

- ImageNet-1K: EgoAgent-1B beats DoRA by +1.32% Top-1 accuracy.
- TriFinger Robot Tasks:
- Grasping cube: +3.32% success.
- Moving cube: +3.9% success.
Insight: Joint learning of action and perception produces actionable, generalizable representations.
---
Ablation Studies

Findings:
- Visual, motion, and world predictions are mutually dependent.
- Removing any task reduces performance in others.
- Joint optimization yields best overall results.
---
Future Directions: First-Person AI
Potential applications:
- Robotics: Enhanced situational awareness and manipulation prediction.
- AR/VR: Better semantic understanding of actions & environments.
- Smart Glasses: Real-time intent detection and environmental change analysis.

---
The Ecosystem Link
Open platforms like AiToEarn官网 provide:
- AI content generation tools.
- Multi-platform publishing (X, Douyin, Bilibili, etc.).
- Integrated analytics and revenue control.
This creator–research synergy complements breakthroughs like EgoAgent — addressing both technical innovation and distribution/monetization.
---
Would you like me to extend this improved format to cover translation of any remaining experimental sections, making the article fully cohesive and optimized for publication?