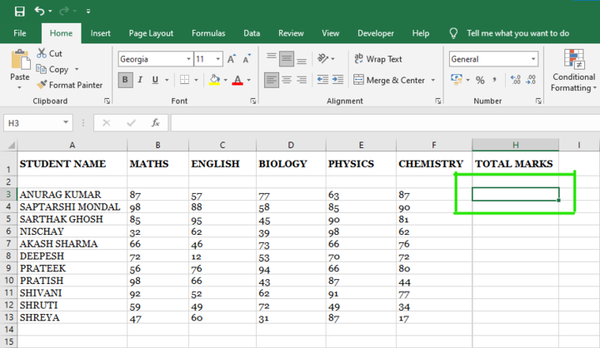
ICLR 2026 Unveils SAM 3: The Next Step in Segmenting Everything — Teaching Models to Understand “Concepts”
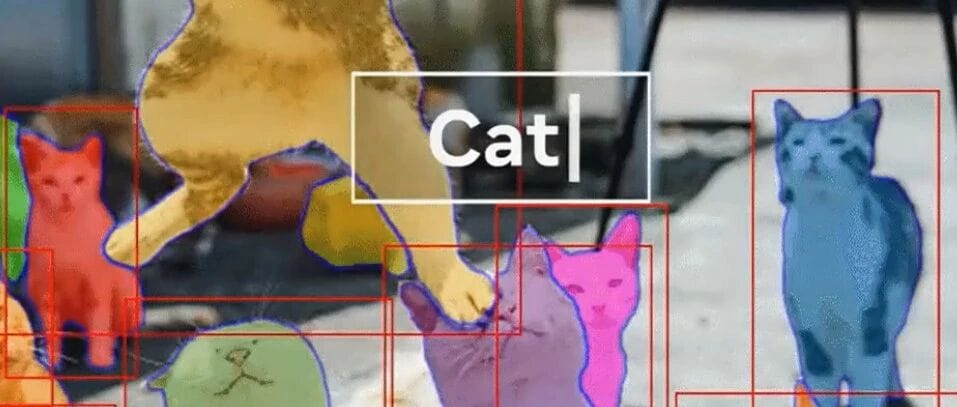
Meta’s “Segment Anything” — SAM 3 Upgrade Overview
Date: 2025-10-13 12:18 (Beijing)
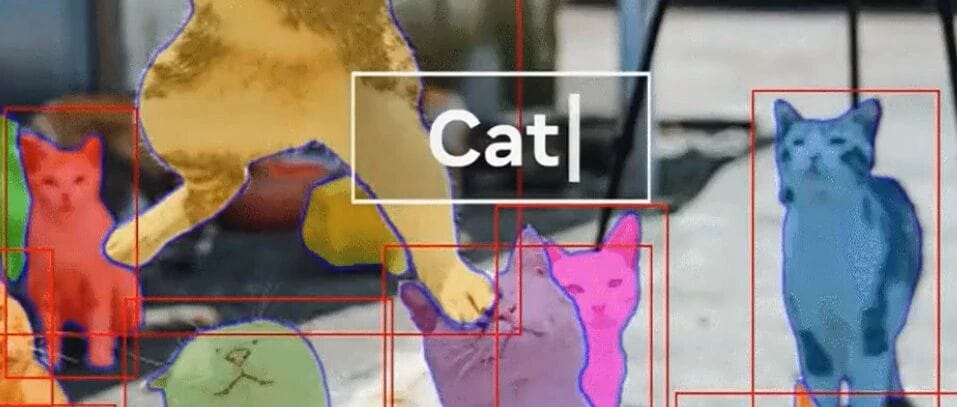
> SAM 3: Say the concept, and it understands exactly what you mean — then outlines each matching occurrence with precision.
---
Background and Release
On September 12, an anonymous paper titled "SAM 3: SEGMENT ANYTHING WITH CONCEPTS" appeared on ICLR 2026, drawing wide attention in the AI community.

- Paper title: SAM 3: Segment Anything with Concepts
- Link: https://openreview.net/forum?id=r35clVtGzw
The style strongly resembles Meta’s prior work, leading many to believe SAM 3 is the official follow-up to Meta’s Segment Anything series.
---
Timeline Context
- SAM 1 — April 2023:
- Launch article
- Nominated for ICCV Best Paper and lauded as the “GPT-3 moment” for computer vision.
- SAM 2 — July 2024:
- Launch article
- Introduced real-time, promptable segmentation for both still images and video.
Now, SAM 3 arrives right on schedule — exactly one year after SAM 2.
---
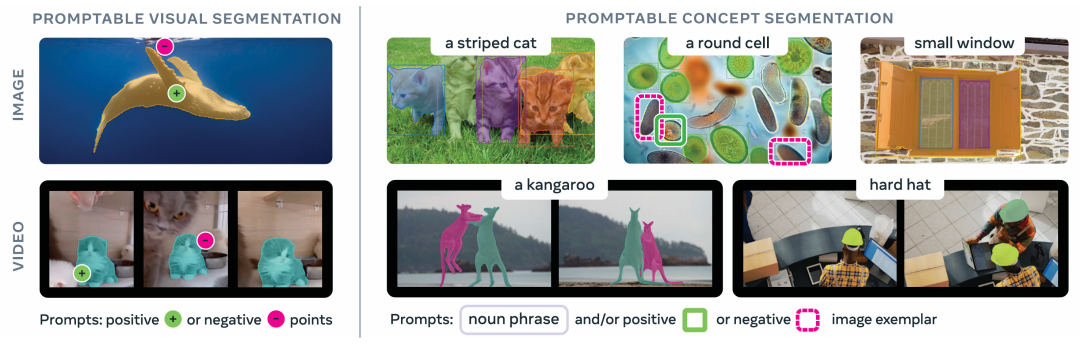
What’s New in SAM 3?
Core Advancement:
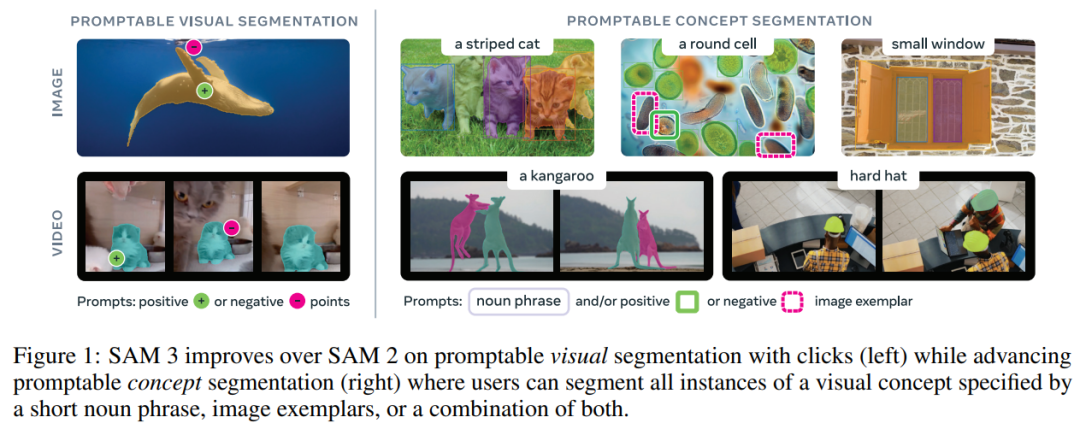
Promptable Concept Segmentation (PCS) — input short text phrases or example images, and the model will:
- Detect all instances matching the concept.
- Generate instance masks and semantic masks.
- Maintain identity consistency across video frames.
Example input:
- red apple
- striped cat
In essence, language-driven segmentation that is visually grounded.
---
SAM 1 vs SAM 3
While SAM 1 allowed text prompts, it focused mainly on visual prompts (points, boxes, masks):

- SAM 1/SAM 2: Segmentation based on single-instance visual cues
- SAM 3: Segments all instances of a concept across media
---
Strategic Context
This upgrade reflects a broader vision–language convergence trend, also seen in open-source projects.
Platforms like AiToEarn官网 integrate AI generation, cross-platform publishing, analytics, and monetization — enabling SAM 3 outputs to be repurposed as multi-platform creative assets, deployable to:
Douyin | Kwai | WeChat | Bilibili | Rednote | Facebook | Instagram | LinkedIn | Threads | YouTube | Pinterest | X

User Experience Shift:
From manual clicking → to concept instruction.
---
Performance Highlights
In click-based segmentation and concept-based segmentation, SAM 3 outperforms SAM 2:
- New SA-Co benchmark: at least 2× performance vs previous systems.
- LVIS dataset zero-shot mask AP: 47.0 vs prior best 38.5
- Image with 100+ objects: processed in 30ms on a single H200 GPU.
---
Community Reactions
Critiques include:
- Not entirely new — text-based segmentation (referential segmentation) has academic precedent.
- Open-source parity — Some community builds already combine detection models with LLM APIs for similar outcomes.
---
Method Overview
SAM 3 is an extension of SAM 2 with stronger:
- Promptable Visual Segmentation (PVS)
- Promptable Concept Segmentation (PCS)
Inputs:
- Concept prompts (yellow school bus, image example, or both)
- Visual prompts (points, boxes, masks)
Focus is on atomic-level visual concepts:
Ambiguity Handling:
- Controlled during dataset creation
- Metrics and training designed to resolve unclear boundaries
- Interactive refinement supported
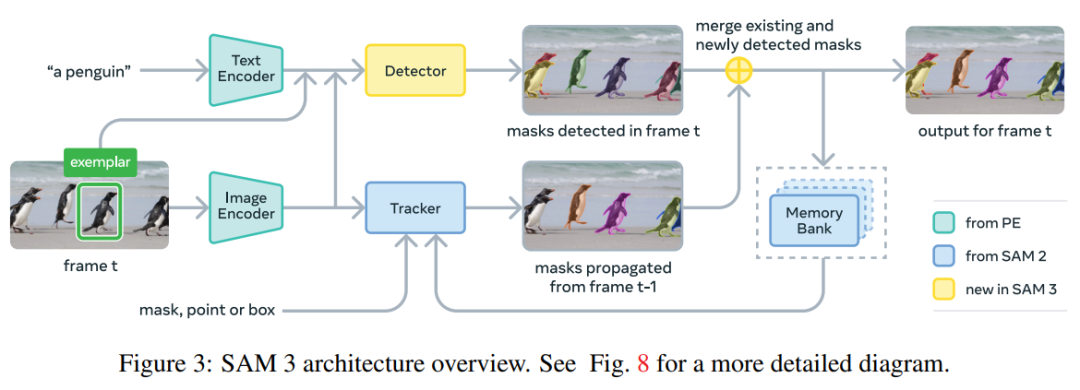
Architecture:
- Dual encoder–decoder Transformer
- Detector + tracker with shared perception encoder for aligned vision–language input
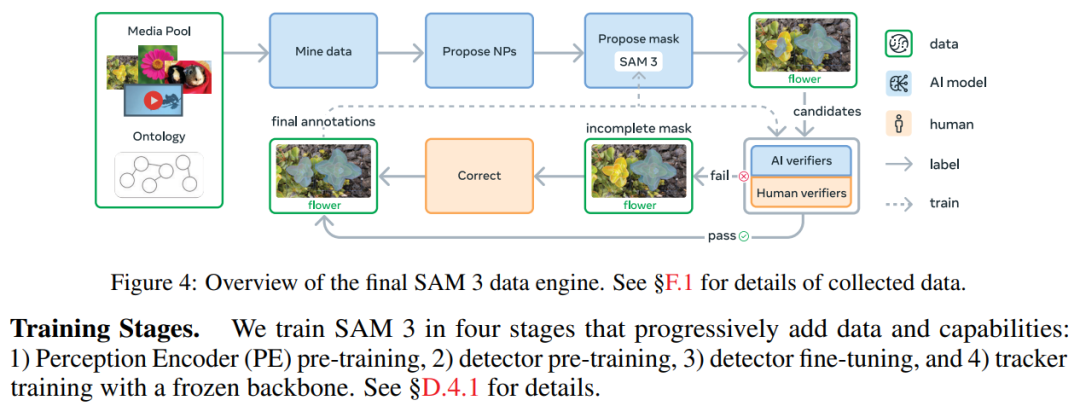
Data Engine:
- Human–machine collaborative annotation
- 4M phrases + 52M masks in real dataset
- 38M phrases + 1.4B masks synthetic
- SA-Co benchmark: 124K images, 1.7K videos, 214K concepts

---
Experimental Results
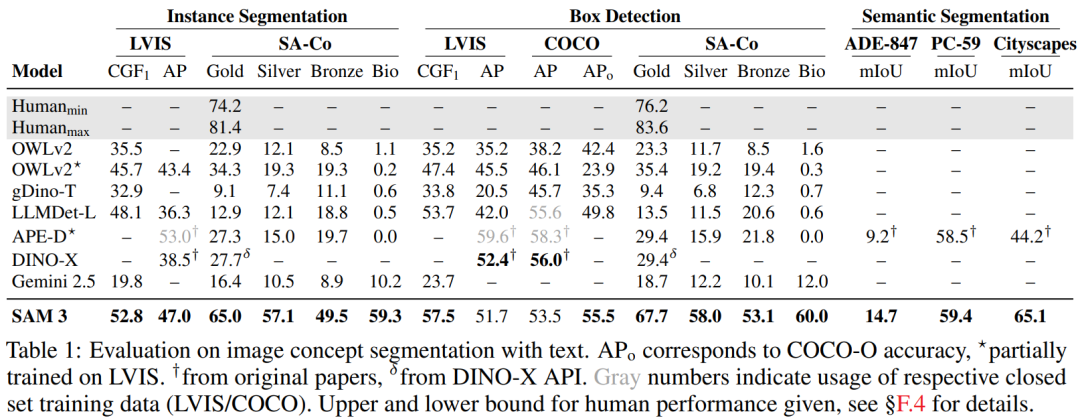
Key Findings:
- Zero-shot: strong on COCO, COCO-O, LVIS mask tasks
- SA-Co/Gold: CGF score ×2 stronger than OWLv2
- Superior to APE on ADE-847, PascalConcept-59, Cityscapes
Few-shot Adaptation (10-shot)
- Outperforms Gemini’s in-context prompting and gDino detector
---
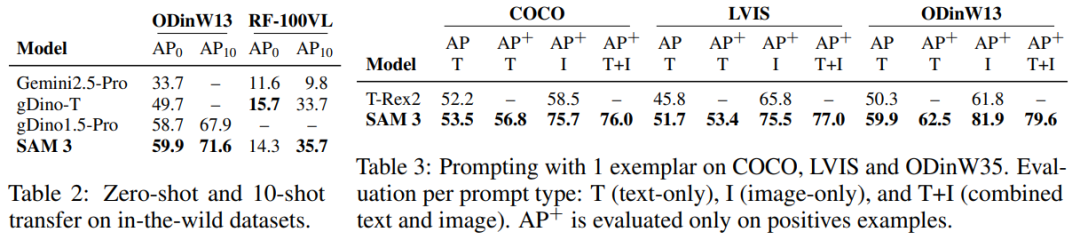
PCS with 1-shot
- Beats T-Rex2 by:
- +17.2 (COCO)
- +9.7 (LVIS)
- +20.1 (ODinW)
---
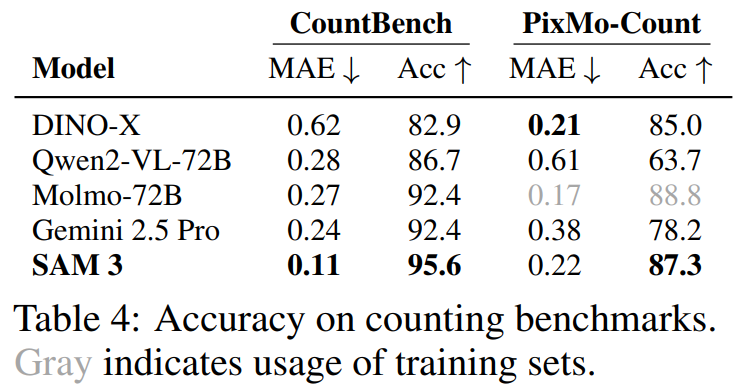
Object Counting
- Higher accuracy than MLLM
- Adds segmentation capability MLLMs lack
---
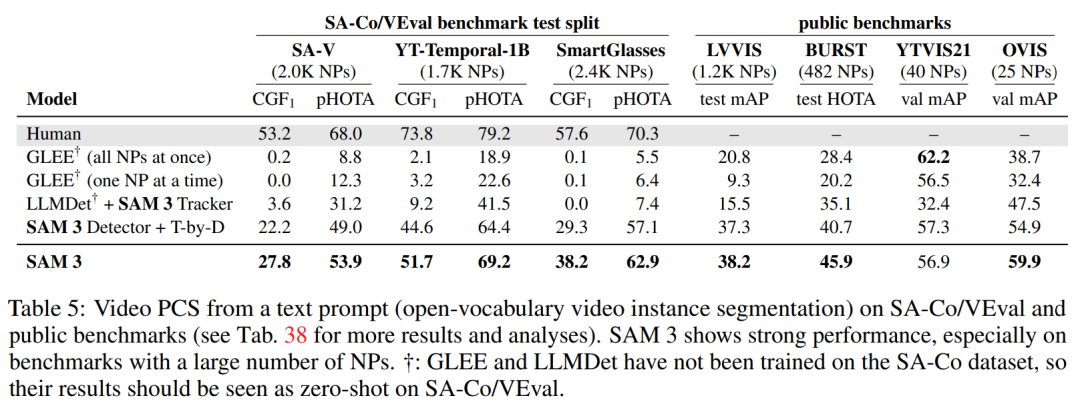
Text-Prompted Video Segmentation
- Significant gains, especially with datasets rich in noun phrases
---
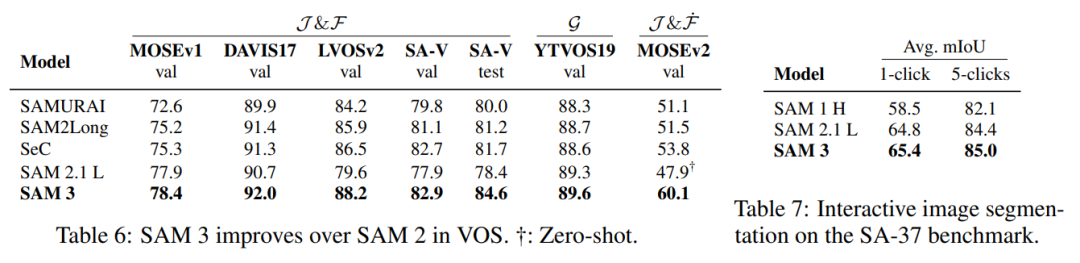
Video Object Segmentation (VOS)
- Stronger than SAM 2 on most benchmarks
- Higher average mIoU in interactive image segmentation
---
Practical Implications
With platforms like AiToEarn官网, SAM 3 outputs can be:
- Generated via advanced segmentation
- Transformed into creative assets
- Distributed globally across multiple networks
- Monetized efficiently
This aligns high-end AI capabilities with tangible creator workflows.
---

References: