# Ilya Sutskever on the Future of AI: From Scaling to Research
**Date:** 2025‑11‑30
**Location:** 浙江

---
## Overview
Former OpenAI Chief Scientist **Ilya Sutskever** recently shared a provocative perspective:
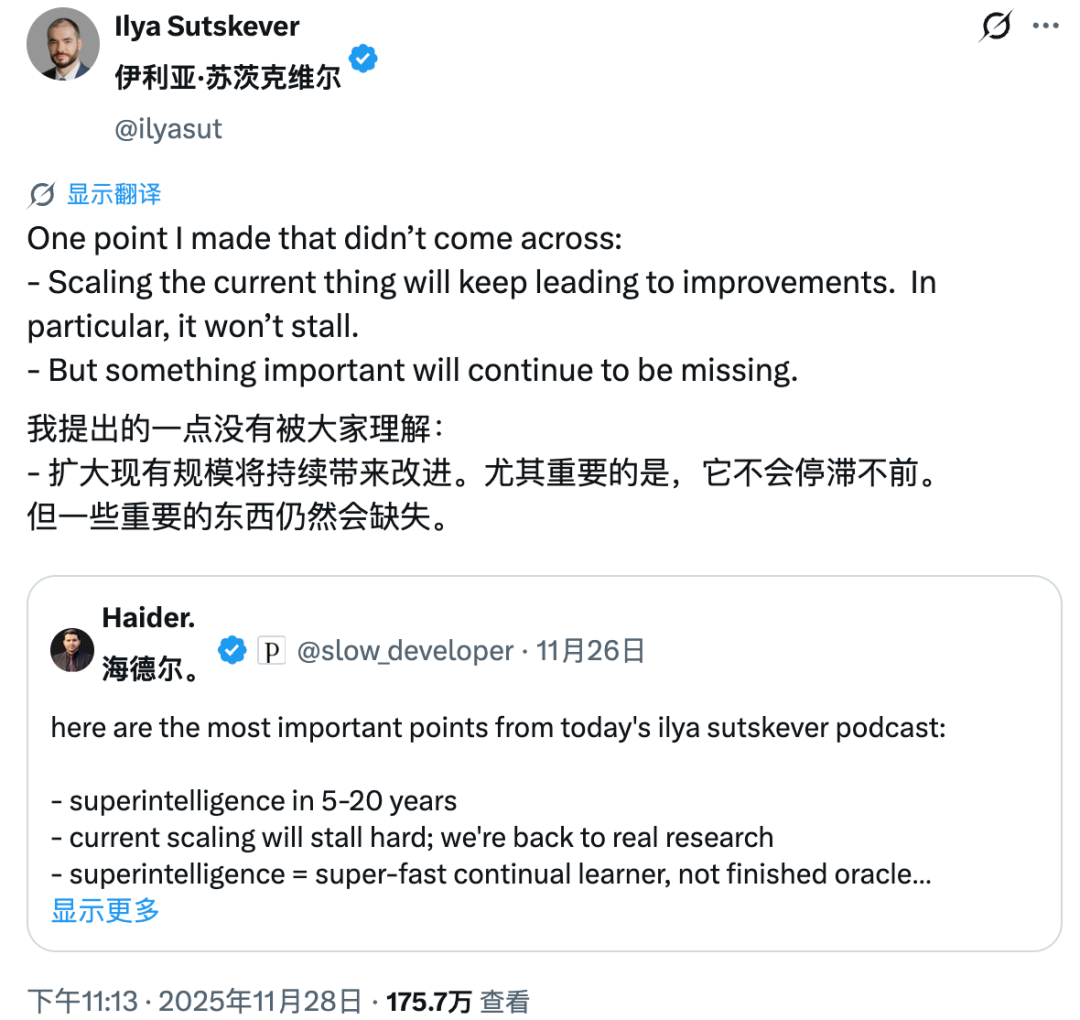
Even with **100× more resources** than before, we may no longer see the kind of *qualitative leaps* in AI capabilities that characterized the past.
The era of **“big brute force miracles”** could be ending.

**Editor:** Tina
Sutskever’s remarks sparked speculation online, with many reading it as “the end of scaling laws.” He later clarified on social media: scaling technology will **continue to bring incremental improvements**, but **something crucial is still missing**.
---
## Industry Reactions
OpenAI researcher **Noam Brown** analyzed the debate:
- Social media often distills AI discourse into extremes:
- *Skeptics*: LLMs are doomed to fail
- *Believers*: superintelligence is imminent
- Careful reading of top experts’ real positions reveals consensus:
1. Current paradigms can already have huge economic/social impact without further breakthroughs.
2. Achieving AGI still likely requires key innovations — **continual learning** and **sample efficiency** are top candidates.
3. AGI is *likely achievable within 20 years*.
Brown emphasized: **No one credible thinks ASI is a fantasy or centuries away**. The disagreements are about *which breakthroughs* and *how fast they’ll arrive*.
Turing Award winner **Yann LeCun** openly agreed with this framing.
---
## Key Takeaways from Sutskever’s Long Interview
### Intelligence vs Real-World Robustness
- Current LLMs ace benchmarks yet fail at **simple real-world tasks** — indicating "fragile intelligence".
- **Over-optimizing for benchmarks** via RL may harm generalization to authentic use cases.
- In humans, **emotions act as value functions** — simple yet robust signals guiding decisions.
- Pure scalability ("just make it bigger") is losing dominance; **research-driven innovation** on top of large compute is returning.
- The **core bottleneck** now: poor generalization compared to humans — low sample efficiency and difficulty learning complex tasks.
- Evolution gifted humans strong priors in ancestral skills like vision/motion — making us naturally outperform AI there.
- Modern learning uses **internal value functions** to self-score, not just external rewards.
- Compute is abundant; **novel ideas are scarcer than companies**.
- Public exposure to powerful AI is vital for understanding its impact.
- Misleading terms:
- **AGI**: better thought of as an *entity with exceptional continual learning*
- **Pre‑training**: foundation for scaling
---
## Example: Model "Jaggedness"
Sutskever describes puzzling gaps: a model can perform brilliantly on hard evals yet mess up basic tasks.
Two possible causes:
1. **RL narrowness** — overly single-goal focus reducing flexibility.
2. **Biased RL data selection** — optimized toward benchmarks rather than real tasks.
---
## Human Analogy: Competitions vs Real Work
- **Student A**: 10,000 hours training for contests → world-class competitor.
- **Student B**: 100 hours, broad skills → better in professional settings.
- AI training often mirrors **Student A**, overfitting to narrow domains.
---
### Pre‑training vs RL
- **Pre‑training**: massive, naturally selected data; difficult to analogize perfectly to humans.
- Humans use **emotions/value functions** for decision-making — AI lacks comparable built-ins.
---
## Scaling: Past, Present, Future
- **2012–2020**: Research-driven.
- **2020–2025**: Scaling-driven — bigger models, more data, more compute.
- Now: scaling hits limits → back to research with **supercomputers**.
- Pre‑training is finite — **data ceiling** approaches.
- Next recipe? Possibly **enhanced pre‑training**, RL, or entirely new methods.
---
## Why Humans Generalize Better
- Evolution gave humans powerful **priors** in perception and motor control.
- Driving: humans need ~10 hours; AI needs vastly more data.
- Even in newer domains — language, math, programming — humans have mechanisms enabling rapid capability acquisition.
---
## Value Functions and Continual Learning
- Value functions measure mid‑process promise:
- E.g., knowing a chess move is bad *before* checkmate.
- Essential for **efficient long-horizon learning**.
---
## Deployment Strategies: Straight Shot vs Gradualism
- SSI explores a **“straight to superintelligence”** approach but acknowledges:
- Gradual public exposure will occur naturally during deployment.
- Superintelligence as **fast learners**, not omniscient products.
- Economic impact could be rapid and transformative.
- Coordination and safety likely require cross‑company collaboration and possibly regulation.
---
## Alignment Goals
- Possible target: **AI that cares about all sentient life** — potentially easier than human-only care.
- Concerns: future AI populations may vastly outnumber humans — governance implications.
---
## Long-Term Equilibrium Ideas
- **Personal AIs for everyone** could be risky — humans may become passive.
- Alternative: **human–AI integration** (Neuralink++) to keep humans actively engaged.
---
## SSI’s Position
- Distinct technical roadmap focused on **understanding generalization**.
- Belief in convergence of alignment strategies as capabilities grow.
- Timeline: **5–20 years** for human-level learners → potential superintelligence.
- Expect market competition to create **specialized narrow-domain superintelligences**.
---
## Diversity Among AI Agents
- Current pre‑training yields similar models.
- Diversity emerges later in RL/post‑training.
- **Self-play and adversarial setups** may foster methodological diversity.
---
## Research Taste
- Guided by **aesthetic sense**: beauty, simplicity, elegance, correct inspiration from neuroscience.
- Maintain **top‑down conviction** when data temporarily contradicts the vision.
---
## Events & Further Reading
### AICon 2025 — Beijing, Dec 19–20
Topics: Agents, context engineering, AI product innovation.
**10% discount available.**

---
### Recommended Articles
- [Chinese math models dominate; DeepSeek Math V2 crushes competition](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247649665&idx=1&sn=dba5ea1ea89d2205be7801b60ea94d4d&scene=21#wechat_redirect)
- [Xiaomi recruits robotics experts, including ex-Tesla Optimus engineer](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247649639&idx=1&sn=bd438d162078062887036650100821ff&scene=21#wechat_redirect)
- [AI chips enter 'Three Kingdoms' era — Google, Meta, NVIDIA, AMD updates](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247649613&idx=1&sn=5eb74fe63fa97e439efe0180346edc4e&scene=21#wechat_redirect)
- [Claude Opus 4.5 reclaims programming crown](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247649534&idx=1&sn=c7158068b89c872e1f4e39f2665962b6&scene=21#wechat_redirect)
- [80M quant code theft case; Haomo Zhixing rumors; lottery GPU dispute | AI Weekly](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247649452&idx=1&sn=0bb6284567786cf3bae76f17ab2fc795&scene=21#wechat_redirect)

---
## Related Resource: AiToEarn Global Platform
Throughout the conversation, parallels are drawn to **[AiToEarn官网](https://aitoearn.ai/)** — an open-source global AI content monetization ecosystem.
It connects:
- AI generation tools
- Cross‑platform publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Analytics and [AI模型排名](https://rank.aitoearn.ai)
- [Open-source code](https://github.com/yikart/AiToEarn)
AiToEarn mirrors some AGI deployment challenges: integrating diverse outputs, scaling impact, enabling incremental learning from multi-instance environments, and distributing benefits broadly.
---
[Read the original](2247649767)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=00d8ca8e&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzU1NDA4NjU2MA%3D%3D%26mid%3D2247649767%26idx%3D2%26sn%3Ddebdc09588032f3cc7e8caa1a39a86eb)



