# Vision-Driven Token Compression: A Future Standard for Long-Context LLMs
**Date:** 2025-11-10 12:38 Beijing
## 📢 Overview
A research team from **Nanjing University of Science and Technology**, **Central South University**, and **Nanjing Forestry University** has introduced a groundbreaking framework — **VIST** (*Vision-centric Token Compression in LLM*) — in their NeurIPS 2025 paper.
This novel approach offers a *visual solution* for efficient long-text reasoning in large language models (LLMs), built on principles similar to the recently popular **DeepSeek-OCR**.

---
## 1. Research Background
Modern LLMs excel at short-text understanding but face challenges with **very long contexts**.
Real-world applications such as:
- 📄 Long-document comprehension
- ❓ Complex question answering
- 🔍 Retrieval-Augmented Generation (RAG)
require handling contexts of **tens or hundreds of thousands of tokens**.
At the same time, **model parameters** have ballooned from billions to trillions.
📉 **Token compression** has evolved from an optimization into a *necessity*:
- Without compression, even the most capable LLMs struggle to process huge inputs efficiently.
**VIST** was designed specifically to address this dual challenge.
---
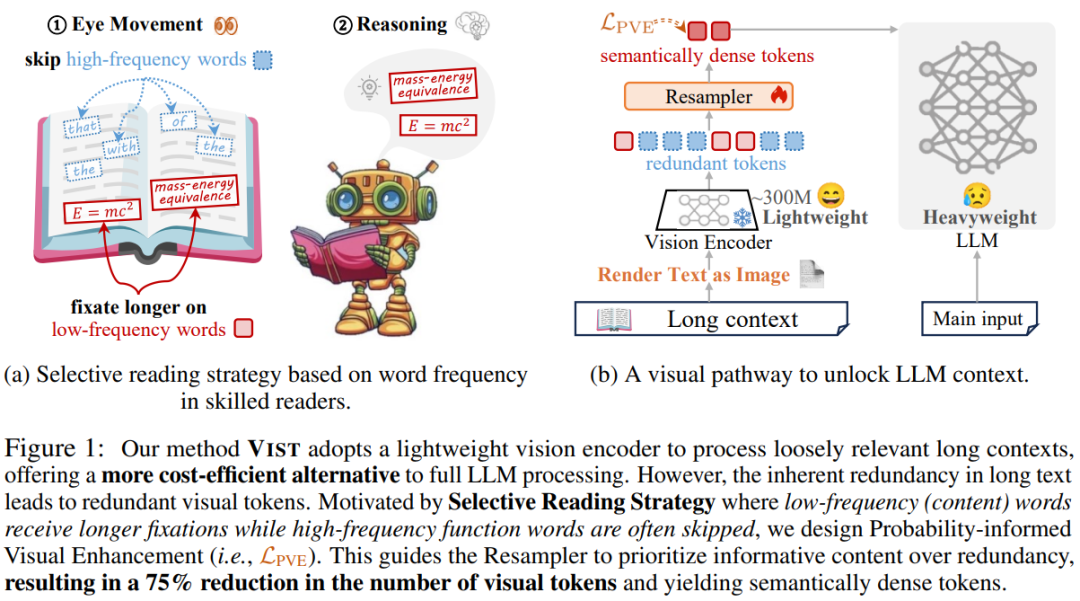
## 2. Teaching LLMs to Read Like Humans
> Inspired by human reading habits — scanning redundant words while focusing on meaning-rich content.
Humans naturally skip high-frequency functional words ("the", "of", "and") and concentrate on low-frequency, meaningful ones (nouns, verbs, numbers).
**VIST** applies this selective reading via a **visual compression mechanism** modeled after the human *Slow–Fast Reading Circuit*:
### Slow–Fast Dual Path
- 🏃 **Fast Path**:
- Render far or less important context into images
- Feed to a **frozen lightweight visual encoder**
- Quickly extract salient semantic cues
- 🧠 **Slow Path**:
- Send important near-context text directly to the LLM
- Perform deep reasoning and language generation
This **vision + language** interplay mirrors eye-brain cooperation:
Scanning globally, zooming in on details for deep thought.
**Efficiency Gains**:
- 56% fewer visual tokens vs. traditional text tokenization
- 50% lower memory consumption

📄 **Paper:** *Vision-centric Token Compression in Large Language Model*
🔗 [https://arxiv.org/abs/2502.00791](https://arxiv.org/abs/2502.00791)
---
## 3. Unlocking Long-Text Understanding via Visual Compression
Traditional LLM tokenizers convert text into discrete tokens for high semantic resolution.
However, visual encoders — trained on large-scale image-text datasets (e.g., CLIP) — often exhibit **self-emergent OCR capabilities**, making them capable of reading text directly from images.
**VIST** leverages this by:
- Rapid scanning (visual encoder path)
- Deep comprehension (text input path)
---
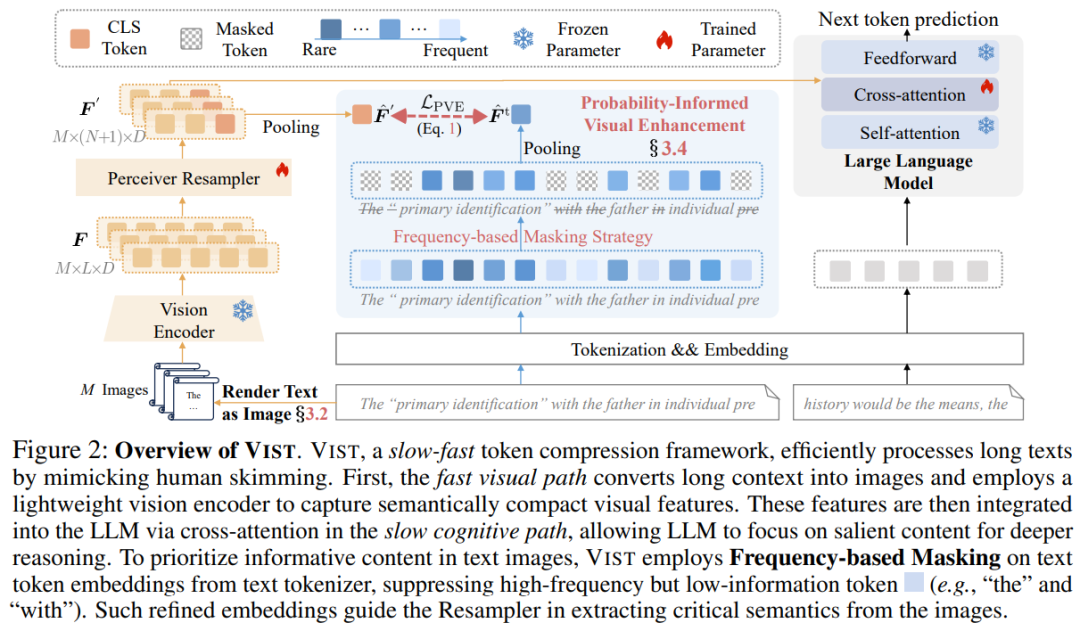
## 4. Practical Integration Steps
- Render secondary long-range context as images → process with lightweight visual encoder
- Apply **4× compression** using a Resampler
- Merge compressed visual features into LLM’s primary input via **cross-attention**
- Pass core text directly via the slow path for deep reasoning
Result:
"Scan the distance, focus on the near" — mimicking human reading.
---
## 5. Probability-Informed Visual Enhancement (PVE)
### Challenge
- Visual encoders excel at natural imagery but have slower adaptation to rendered text
- Long texts have redundant information → indiscriminate processing wastes compute
### Solution
**PVE** teaches models to *skim-read* by prioritizing meaningful content:
- **Frequency-based Masking Strategy**:
- Mask high-frequency, low-information words
- Retain low-frequency, high-information words
These optimized embeddings guide the Resampler to extract core semantics efficiently.

---
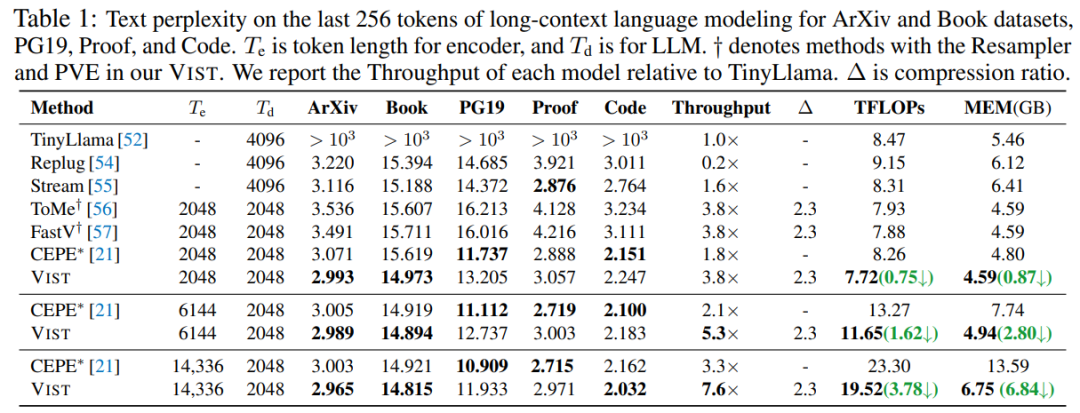
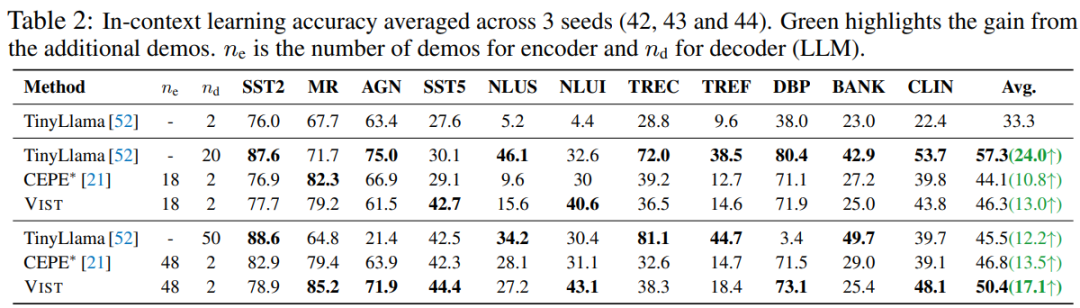
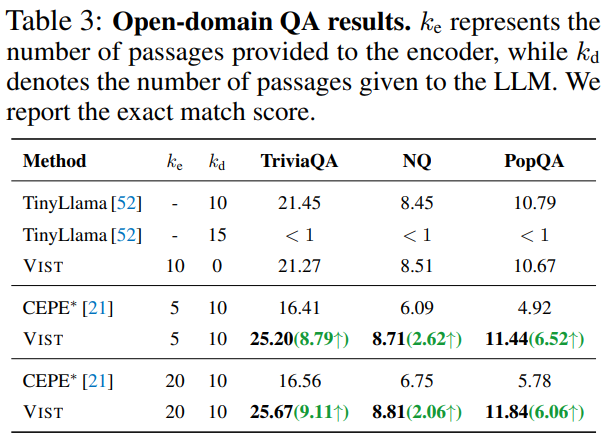
## 6. Benchmark Performance
In:
- **Open-domain QA**
- **11 In-Context Learning (ICL)** benchmarks
**VIST** consistently outperforms **CEPE** (text encoder compression).
Even with visual-only processing, it matches **TinyLlama** performance on QA tasks.
**Compression Benefits**:
- Compression ratio: ≈ 2.3 (1024 → 448 visual tokens)
- GPU memory: ↓ 50%
---
## 7. Visual Text Tokenization: Let LLMs “Read with Their Eyes”
**Advantages:**
1. **Simplified process** — skip multi-step manual preprocessing
2. **No vocabulary constraints** — avoid multilingual tokenization issues
3. **Noise robustness** — resist spelling/character-level attacks
4. **Multilingual efficiency** — significant token reduction for Japanese (62%), Korean (78%), Chinese (27%)
---
## 8. 🚀 Conclusion & Future Outlook
Vision-driven compression like **VIST** can:
- Make LLMs *read like humans*
- Enhance efficiency in multilingual, multimodal, and extreme long-text scenarios
📈 **Potential Standard Feature**:
As LLMs grow, "look first, then read" strategies can maintain comprehension while reducing compute demands.
🔗 Related Resources:
- [AiToEarn官网](https://aitoearn.ai) — Open-source global AI content monetization platform
- [AI模型排名](https://rank.aitoearn.ai) — AI model ranking tools
- [Blog: 人类看文字](https://csu-jpg.github.io/Blog/people_see_text.html)

---
### Additional Links
- [Original Article](2651000759)
- [Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=fcd7cd19&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzA3MzI4MjgzMw%3D%3D%26mid%3D2651000759%26idx%3D2%26sn%3D37f6f1db14572b10b673ff9373c6cba2)