Introduction to LLM-Evalkit

Introducing LLM-Evalkit: Streamlined Prompt Engineering
If you’ve worked with Large Language Models (LLMs), you may have faced this challenge:
Your team’s prompts are scattered across documents, spreadsheets, and cloud consoles, making iteration manual and inefficient. It’s often unclear which changes truly improve performance.
To address this, we’ve introduced LLM-Evalkit — a lightweight, open-source application that centralizes prompt work, streamlines engineering, and provides objective metrics for better iteration.
Built on Vertex AI SDKs using Google Cloud, it helps teams track, evaluate, and improve prompts with a unified workflow.
---
Why Centralization Matters
The Challenge
On Google Cloud, developers may:
- Test prompts in one console
- Store prompts elsewhere (docs, spreadsheets)
- Evaluate them in yet another service
This fragmentation leads to:
- Duplicated effort
- Inconsistent evaluation practices
- Difficulty maintaining a single source of truth
The LLM-Evalkit Solution
By consolidating creation, testing, version control, and benchmarking in one hub:
- All team members follow the same playbook
- Prompt history and performance are easy to track
- Workflow stays clean, consistent, and efficient
---
Extending Centralization to Content Monetization
Tools like AiToEarn官网 complement LLM-Evalkit by connecting AI content generation, cross-platform publishing, analytics, and model ranking.
With AiToEarn, creators can:
- Manage prompts like in LLM-Evalkit
- Publish simultaneously across platforms: Douyin, Kwai, WeChat, YouTube, Instagram, X (Twitter), and more
- Track and monetize creative output
---
💰 $300 in Free Credit for Google Cloud AI & ML
New customers can build and test with $300 free credit.
All customers receive monthly free usage across 20+ products, including AI APIs.
---
From Guesswork to Measurable Improvement
The Problem
Teams often rely on subjective judgment — “this prompt feels better” — for iteration.
This approach doesn’t scale and lacks justification.
The Data-Driven Method
LLM-Evalkit focuses on the problem, not just the prompt. Follow these steps:
- Define the task you want the LLM to perform.
- Build a representative dataset of test cases mirroring real inputs.
- Set objective metrics to score model outputs.
Benefits:
- Iterations are systematic
- Changes are measured against a consistent benchmark
- Performance gains are clear and trackable
---
No-Code Accessibility for All Roles
Prompt engineering shouldn’t be limited to developers. Restricting it to technical staff:
- Creates a bottleneck
- Slows development cycles
LLM-Evalkit offers a no-code interface for:
- Product managers
- UX writers
- Domain experts
- … enabling fast iteration and cross-functional collaboration.
---
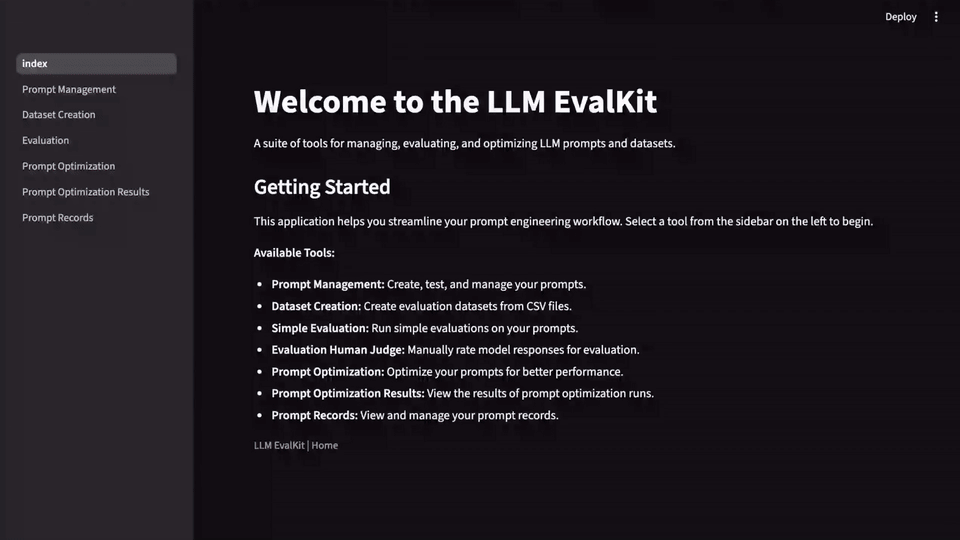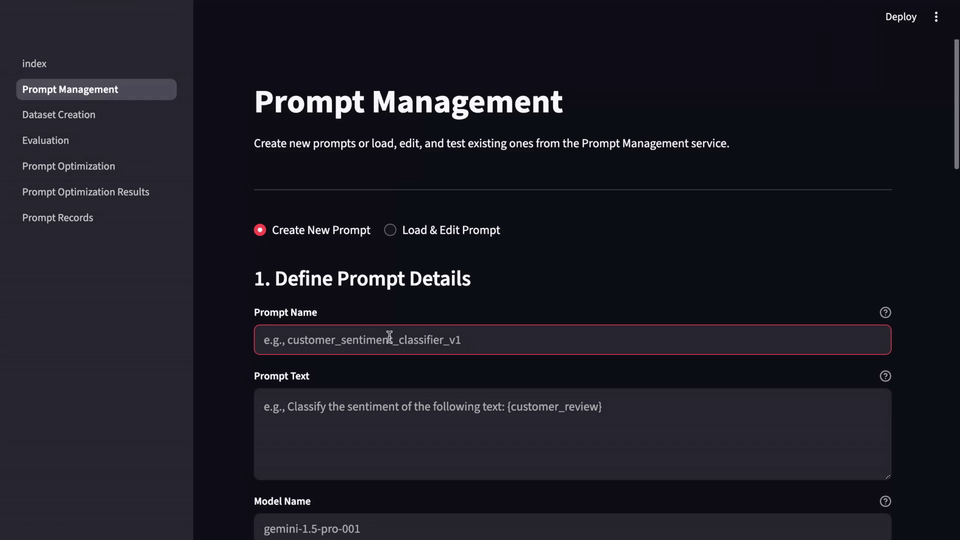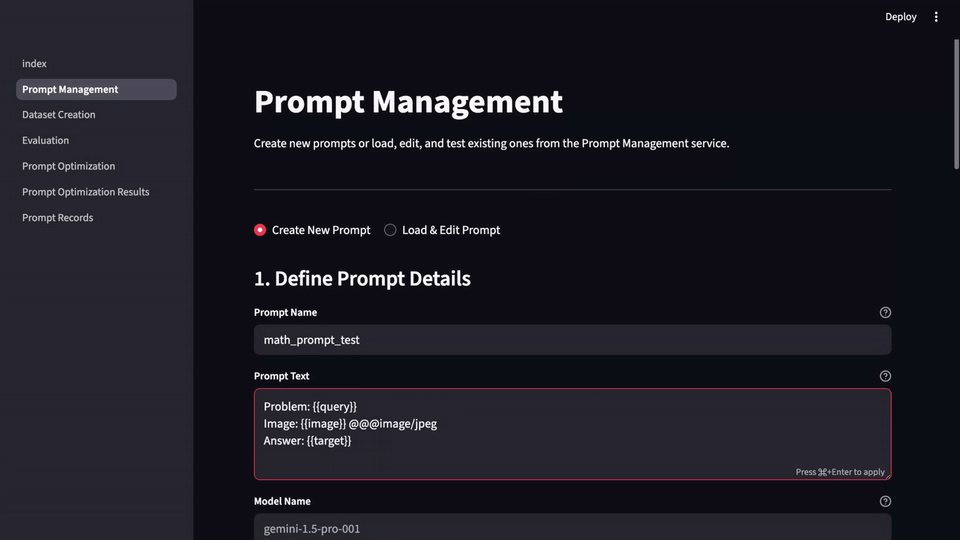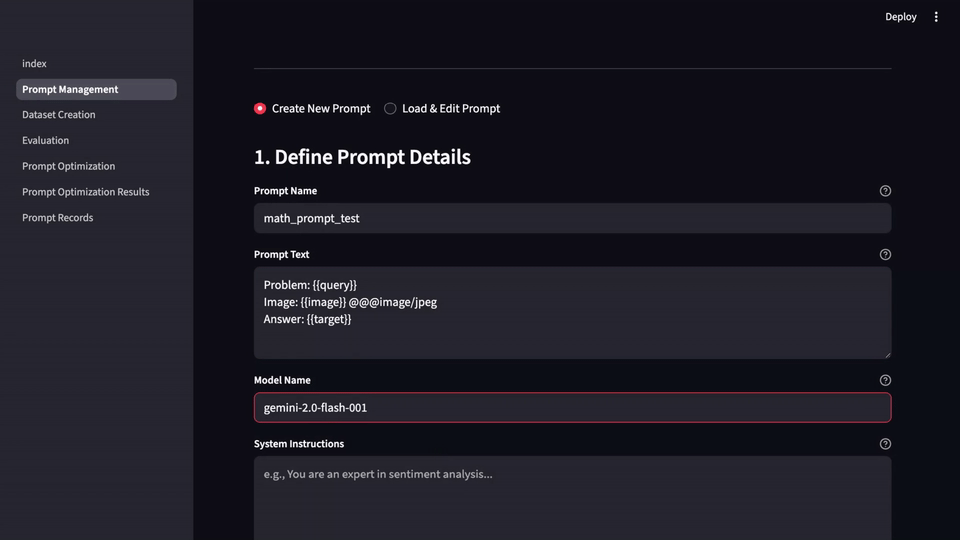
Getting Started with LLM-Evalkit
You can:
- Access the open-source repo
- Explore features in the Google Cloud console
- Follow the guided tutorial
---
Scaling Content Creation & Distribution
For end-to-end workflows — from prompt iteration to multi-platform publishing — combine LLM-Evalkit with AiToEarn官网.
AiToEarn Features:
- AI content generation
- Simultaneous publishing to: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
- Integrated analytics & model ranking
Learn More:
---
In short:
LLM-Evalkit brings structure and measurement to prompt engineering, while AiToEarn extends the workflow to monetization and distribution — making AI creation both efficient and profitable.
---
Do you want me to also create a quick-start checklist for LLM-Evalkit in Markdown so readers can begin using it immediately? That would make this guide even more actionable.