# **November 15, 2025 — Shandong**

## **Depth Anything 3** Launches
> *"Now, all you need is a simple Transformer trained with deep ray representation."*
A new research breakthrough demonstrates that **most current 3D vision studies are over-engineered**.
This Friday’s hottest topic in the AI community was a new paper centered on **3D modeling**.

After over a year of exploration, **ByteDance’s team** has released **Depth Anything 3 (DA3)**.
DA3 extends monocular depth estimation to **any viewpoint scenario**, enabling computers to achieve **human-like spatial perception**.

**Key Resources**
- **Paper:** [https://arxiv.org/abs/2511.10647](https://arxiv.org/abs/2511.10647)
- **Project Page:** [https://depth-anything-3.github.io](https://depth-anything-3.github.io)
- **Code:** [https://github.com/ByteDance-Seed/Depth-Anything-3](https://github.com/ByteDance-Seed/Depth-Anything-3)
- **Demo:** [https://huggingface.co/spaces/depth-anything/depth-anything-3](https://huggingface.co/spaces/depth-anything/depth-anything-3)
### **Two Core Insights of DA3**
1. **A standard Transformer backbone** (like DINO) is sufficient — no specialized architectures required.
2. **A single deep ray representation** suffices — eliminating complex multi-task 3D pipelines.
**Performance Gains:**
- **+44%** in pose estimation accuracy over SOTA
- **+25%** in geometry estimation accuracy
---
## **Expert Commentary**
NYU Assistant Professor **Xie Saining** likened typical AI progress to movie sequels — often more complex yet not necessarily better.
However, the *Depth Anything* series **gets simpler and more scalable with each release**.
Xie noted:
> “With DA3, the authors show that a strong representation encoder plus deep ray prediction is enough to enable reliable, general spatial perception in many tasks.”
> “Vision’s complexity is exactly what I love — I believe AI’s biggest breakthroughs will quietly emerge from vision, then suddenly surpass other domains.”
He predicts that **vision is not separate tasks**, but a unified perspective of continuous sensory data, layered world representations, and progress toward human-like intelligence.
---
## **Broader Impact**
Platforms like **[AiToEarn官网](https://aitoearn.ai/)** can harness breakthroughs like DA3. AiToEarn offers open-source tools for:
- AI content generation
- Automated publishing to Douyin, YouTube, Instagram, etc.
- Multi-platform monetization
---
# **Technical Deep Dive — Depth Anything 3 (DA3)**
*A Minimalist Approach to Spatially Consistent Geometry Prediction*
**DA3** predicts spatially consistent geometry from **any number of visual inputs**, with or without known camera poses.
### **Minimalist Design Principles**
1. **Transformer Backbone** — e.g., unmodified DINOv2 encoder.
2. **Single Photometric-Depth Objective** — avoids complex multi-task learning.
DA3 is available in three variants:
- **Main DA3 series**
- **Monocular pose estimation series**
- **Monocular depth estimation series**
---
## **Methodology**
- **Dense Prediction Task**: Given *N* input images → output *N* depth maps & ray maps aligned to input pixels.
- **Backbone**: standard pretrained Vision Transformer for robust feature extraction.
- **Cross-View Self-Attention**: input-adaptive token rearrangement for efficient multi-view fusion.
- **Dual DPT Head**: processes features with different fusion parameters for joint depth & ray output.
- **Camera Encoder (Optional)**: integrates known poses for greater adaptability.
---
## **Training Strategy**
Uses a **teacher–student paradigm** with diverse data:
- Real-world depth camera datasets
- 3D reconstruction data
- Synthetic datasets
**Pseudo-labeling Approach**:
- Train a strong monocular depth model on synthetic data.
- Use it to generate **high-quality pseudo depth maps** for real datasets.
- Benefits: greater detail/completeness **without reducing geometric accuracy**.
---
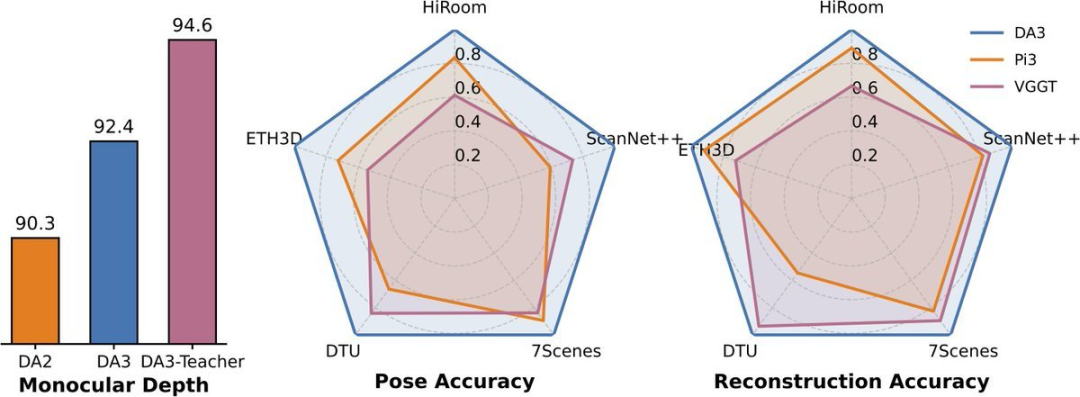
## **Benchmark Highlights**
**New Visual Geometry Benchmark** includes:
- Camera pose estimation
- Arbitrary-view geometry (TSDF reconstruction)
- Visual rendering
**Results:**
- **+35.7%** average pose accuracy over VGGT
- **+23.6%** geometric accuracy gain
- Matches DA V2 in detail & robustness for monocular depth
All models **trained solely on public academic datasets**.
---
## **Capabilities & Applications**
### **1. Video Reconstruction**
Reconstructs spatial scenes from single or multiple views.

### **2. Large-Scale SLAM**
DA3-Long significantly reduces drift compared to VGGT-Long & COLMAP.
### **3. Feedforward 3D Gaussian Estimation**
Freezing backbone, training heads on multi-dataset data → **strong novel view synthesis**.
### **4. Multi-Camera Spatial Awareness**
Merges viewpoints into **stable depth maps** — ideal for autonomous vehicle perception.
---
## **Conclusion**
DA3’s simplicity and efficiency align perfectly with **real-world integration needs**.
Its release has already attracted active developer adoption.
For deeper details, consult the **original technical report**.
---
## **Creator Tools Integration**
**[AiToEarn官网](https://aitoearn.ai/)**
An open-source, global AI content monetization platform:
- Publish across Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
- Integrates AI content generation, analytics, and model rankings ([AI模型排名](https://rank.aitoearn.ai))
- Transforms ideas into revenue streams efficiently
---
**Reference Links:**
- [https://x.com/bingyikang/status/1989358278346977486](https://x.com/bingyikang/status/1989358278346977486)
- [https://x.com/sainingxie/status/1989423686882136498?s=20](https://x.com/sainingxie/status/1989423686882136498?s=20)

---
© **THE END**
- For reprints: contact this account for authorization.
- Contributions/press: liyazhou@jiqizhixin.com
[Read the original article](2651001895)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=03d1ef83&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzA3MzI4MjgzMw%3D%3D%26mid%3D2651001895%26idx%3D2%26sn%3D6310e177b45b575e110696d980a360dc)



