Is Anyone Explaining Clearly Why Database Index Architecture Uses B-Trees? (Part 2: Kernel)

100 Lectures on Database Architecture
Lecture 2 — Database Indexes: Why Use a B+ Tree?

This is the second lecture in 100 Lectures on Database Architecture.
Today we focus on one key question: "Why are database indexes designed as B+ trees?"
We will explore:
- Why indexes exist
- Why trees over hashes
- Why specifically B+ trees
---
1. Why Do Databases Need Indexes?
Think of a library with 10 million books. You need to find The Road to Architect.
If you search one by one, it’s painfully slow.
Solution: organize and categorize:
- By floor — history, literature, IT...
- By topic within IT — software vs hardware
- By title in the software category
With this structure, locating a book is fast.
In databases: If you need to find the record where `name = "shenjian"`, scanning all 10 million rows would be slow.
Indexes allow fast lookups, just like the library classification system.
---
2. Why Not Use Hashes Instead of Trees?
Common data structures for lookups
- Hash-based (e.g., `HashMap`): Average complexity `O(1)` for insert, delete, find.
- Tree-based (e.g., balanced BST): Average complexity `O(log n)`.
Hashes are faster for exact matches.
So why not use them for indexes?
---
Hash Index Performance
Single-row query example:
SELECT * FROM t WHERE name = "shenjian";Hash indexes excel here — especially in systems where all queries are exact matches (e.g., ID verification systems).
---
Tree Index Flexibility
However, most SQL queries require ordering or ranges:
- `GROUP BY`
- `ORDER BY`
- Comparisons `<` / `>`
- Range queries `BETWEEN ... AND ...`
Problem: Hash indexes lose efficiency for ordered queries, degrading to O(n),
while tree indexes retain O(log n) performance thanks to their inherent ordering property.
Conclusion: To support the majority of SQL use cases, tree-based indexes are preferred.
---
3. Why Specifically Use a B+ Tree?
Let's examine several tree types.
---
3.1 Binary Search Tree (BST)
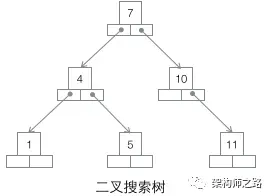
Drawbacks for large datasets:
- Tall trees → slow queries.
- One record per node → many disk I/O operations.
---
3.2 B-Tree
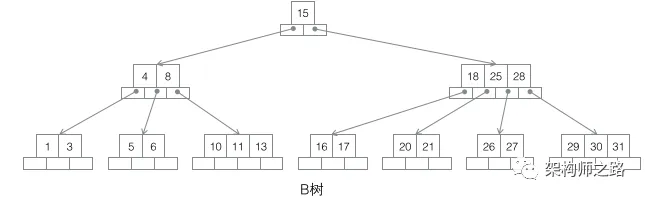
Features:
- m-ary search tree (not just binary)
- Data stored in leaf and non-leaf nodes
- In-order traversal yields sorted data
Key design inspiration: the principle of locality.
---
Principle of Locality
- Memory vs Disk:
- Memory I/O is fast; disk I/O is much slower.
- Disk Read-Ahead:
- Disks fetch pages at once (4K OS page size, 16K in MySQL).
- Nearby data gets read together → fewer future I/O operations.
- Locality:
- Access patterns should be clustered so that "nearby" data is likely to be needed soon.
- This maximizes read-ahead efficiency.
B-Tree advantages:
- m-ary structure reduces height dramatically.
- Nodes sized to page size optimize read-ahead.
---
3.3 B+ Tree
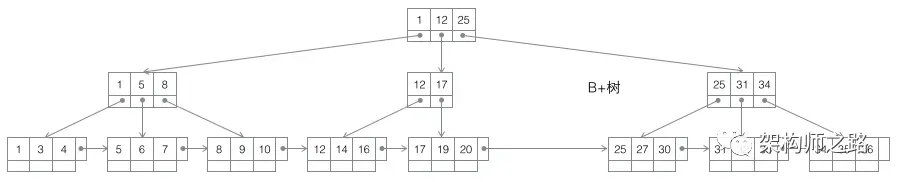
Improvements over B-Tree:
- Non-leaf nodes store only keys — actual data is only in leaf nodes.
- Leaf nodes are linked — enables fast range scans without full in-order traversal.
---
Advantages:
- Range queries are straightforward: find min, then traverse linked leaf nodes up to max.
- Efficient storage: Records tightly packed in leaves (disk), keys in non-leaf nodes (memory).
- More keys in memory: Non-leaf nodes store only keys → more can fit in RAM.
- Uniform path length: All root-to-leaf paths have equal length for predictable performance.
---
3.4 Why m-ary B+ Trees Have Low Height
Example calculation:
- Node size = 4K, each key = 8B → ~500 keys per node.
- m ≈ 1000 (since m ≈ 2 × keys per node).
---
Capacity by layer:
- Layer 1: 1 node → 500 keys → 4K
- Layer 2: 1000 nodes → 500K keys → 4MB
- Layer 3: 1,000,000 nodes → 500M keys → 4GB
Only height 3 needed for 500 million keys, with manageable index size.
---
4. Summary
Key takeaways:
- Indexes speed up queries — essential for large datasets.
- Hashes are fast for exact matches, but poor at ordered/range queries.
- Trees align with broader SQL query needs.
- Read-ahead + locality principles reduce disk I/O.
- B+ Trees offer:
- Low height for huge datasets
- Efficient storage and memory use
- Fast single and range queries
- Better support for ordered operations
---
Final Note: Understanding why is more valuable than just knowing the conclusion.
---
For tech creators interested in database architecture and similar deep topics, platforms like AiToEarn官网 can help create, publish, and monetize content across multiple channels (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter).
It combines AI content generation, publishing automation, analytics, and ranking — much like how a good index optimizes diverse queries.
---
Database Architecture 101 — your learning is my motivation. See you next lecture!


