Jina AI Startup Review: What Is the Scaling Law for AI Teams


"Out of 10 points, I'd give these six years a 7."
No bragging, no false modesty.
From founding to acquisition, just two months shy of a full six years. In October 2025, Xiao Han sold Jina AI to the U.S. listed company Elastic (NYSE: ESTC). He led the core team to join Elastic and took up the role of VP of AI.
In six years, AI technology advanced at a breathless pace: microservice architectures fell out of favor, ChatGPT reshaped the industry, the giants chased each other in the large model race, RAG went through cycles of life and death, and the half-life of models was just months. If you didn’t keep running, your tech assets would be worthless in half a year.
He ran for six years, pivoted twice: cutting scattered projects, laying off half the staff, leaving Europe for Silicon Valley, going all in on foundational search models. “When there is no moat,” he said, “extreme focus and near-autocratic execution become the only moats.”
He likened it to a squid game. He made it to the end, but not without regrets.
At the same time, I was living my own three years at this company.
I’m Zhang Sa. I joined Jina AI in 2022, handling product operations. Last month, after the acquisition, I moved from Beijing to Singapore. As my first job after graduation, Jina AI was like a car with no brakes. Excitement, fatigue, confusion, relief — a four-gear dual-clutch ride. I’ve seen the boss pushing code at 3 a.m.; I remember the team high-fiving over our first $10 sale; and I know too well the frustration when carefully prepped materials were scrapped after a strategy shift, or when memorized selling points were overturned by product iteration.
Later, when our model gained market recognition and the acquisition was sealed, I realized something: what I had seen as constant upheaval was actually the boss’s survival maneuvers in the AI wave.
Below is a long conversation between me and Jina AI founder Xiao Han, about the gains and losses from his six-year entrepreneurial journey.
---

Zhang Sa: Over these six years, what score would you give Jina AI’s startup journey? Out of 10?

Xiao Han: I think around a 7.
Starting from zero in 2020 during the pandemic, I built a team from scratch, went through plenty of ups and downs, and by October 2025, sold successfully to a U.S. listed company. This entrepreneurial journey is one of the things I’m proudest of so far. My very first startup had a successful exit, and the team that stayed with me found a good landing place. Still, there are some regrets.

Zhang Sa: Six years — does that feel long to you?

Xiao Han: When you’re running, it doesn’t feel like it. You stop and realize, wow, you’ve been running for so long.

Zhang Sa: What’s your earliest memory of Jina AI?

Xiao Han: I remember right before Christmas in 2019, pitching to an investor in the executive lounge of a hotel in Shenzhen’s Coastal City. Later, I was at a Costa Café on Anfu Road in Shanghai, tweaking my PPT to present to the IC (Investment Committee). Those are my earliest memories of Jina.

Zhang Sa: I’ve always been curious — how did the name “Jina AI” come about?

Xiao Han: I wanted an AI-related name, something like Jarvis from Iron Man, but it had to meet a few criteria:
First, it should feel neutral to slightly feminine, more approachable and less aggressive. Second, it should be pronounced similarly across languages. Third, it needed to work well for SEO.
From the shortlist of names, I finally chose “Jina” — simple, easy to remember, and easy to say. It felt like Jarvis’s girlfriend. And when I checked SEO at the time, I found the name “Jina” was mainly used by a few Koreans, so ranking at the top of Google searches would be easy.
---
This type of founder insight is rare in the fast-paced AI ecosystem, where focus, rapid pivots, and execution discipline can make or break a company. In fact, it brings to mind modern AI creator tools like AiToEarn官网 — an open-source global AI content monetization platform that helps creators use AI to generate, distribute, and monetize multi-platform content efficiently. Just as Jina AI optimized its trajectory to find market fit, tools like AiToEarn enable individuals to publish simultaneously to major channels while tracking performance and ranking AI models, paving smoother paths for sustainable growth.
Chinese name: Jina, meaning “deep investigation into subtleties” and “all rivers run into the sea”, loosely connected to search and indexing. At the same time, “geek” is also part of our company culture.
---

Zhang Sa: Since Jina was founded in 2020, what have we been working on? Some of my friends have followed Jina from early on, while many more only started paying attention in the past two years. It seems people have different perceptions of Jina?

Xiao Han: That’s right. We’ve gone through several pivots — “transformations” — but overall they’ve all stayed within the broad theme of Neural Information Retrieval, making upstream and downstream adjustments to our focus.
From February 2020 to February 2023, we worked on a software framework to help developers implement semantic search more quickly. The role was somewhat similar to Elasticsearch and later LangChain, LlamaIndex, etc., focusing on toolchains, boilerplate code, and scaffolding.
2023 was a rather chaotic year for us, because in December 2022 ChatGPT was released. At that time, I realized that the community no longer paid attention to the kind of framework we had been building. Inside the company, we held a series of all-hands meetings to discuss what we should do next.
So in 2023, we tried two different new directions:
- One was the Wrapper route — building prompt-based productivity tools — which internally I called the “Thin Strategy.”
- The other was the Search Model route — starting from training our own embedding vector models to strengthen the core search technology — which I called the “Fat Strategy.”
In February 2024, I stopped all progress on the Wrapper route, and went all-in on search model R&D, reshaping our narrative around Search Foundation Models. This is today’s Jina AI — from multilingual to multimodal, with four generations totaling 20 vector models, rerankers, Readers, and other small search-side models, 14 conference papers, over five million downloads per month on Hugging Face, and daily API usage exceeding 200 billion tokens.
---

Zhang Sa: So 2023 was an important year for Jina?

Xiao Han: Yes — both 2023 and early 2024 were extremely important milestones in retrospect.
The 2023 pivot meant abandoning our previous software framework work and completely reassessing the impact of ChatGPT and Gen AI on search. This was a big shock to the tech stack and culture we had spent more than two years building, and many internally didn’t understand why we wouldn’t just persist with the same path. At the same time, we had to work hard to think of a new path forward.
That said, the release of ChatGPT at the end of 2022 was a massive shock to the software industry as a whole — it essentially redefined AI business. So if a startup says they had no reflection or anxiety in 2023, I don’t believe it. Unless you don’t read the news or know nothing of the outside world, it’s hard not to question the value of your work. FOMO (fear of missing out) was the most common phrase we threw around in 2023.
The February 2024 pivot was about finding a unified narrative for vector models, rerankers, etc., so the company’s product focus could be aligned — this was also critically important.
---

Zhang Sa: What was that search framework Jina AI worked on before 2023?

Xiao Han: Our company started in 2020, and at the time Microservice + Orchestration was a very popular cloud-native tech stack. So we built a fairly complete microservice deployment framework in Python, enabling every module in multimodal search — such as vectorization, preprocessing, scoring, indexing, and so on — to be microserviced and freely scaled.
---
In many ways, the changes Jina AI went through mirror the broader evolution of AI and developer tooling in the past few years. For teams today looking to stay agile and monetize AI-driven content and applications efficiently, open-source platforms like AiToEarn官网 offer an integrated way to generate content with AI, publish it across major platforms, analyze impact, and even track AI model rankings (AI模型排名). Such ecosystems help bridge the gap between cutting-edge AI development and sustainable creator economy — something that aligns closely with the spirit of adaptation and reinvention we’ve discussed here.
Back then, we developed many open-source projects based on this concept, such as DocArray, which was somewhat similar to the later Pydantic. It allowed users to design their own multimodal document structures for easier searching. There were also some Docker containerized implementations, which were later partially referenced by some designs from Replit.
In fact, as early as 2021, we were already involved in certain model-layer R&D. However, our work mainly revolved around fine-tuning frameworks for models like BERT and CLIP, named Finetuner. It contained some basic fine-tuning strategies and training loop implementations, mostly “sugar-water” code, with no guaranteed final performance. Its functionality and positioning were somewhat similar to today’s SentenceTransformers library.
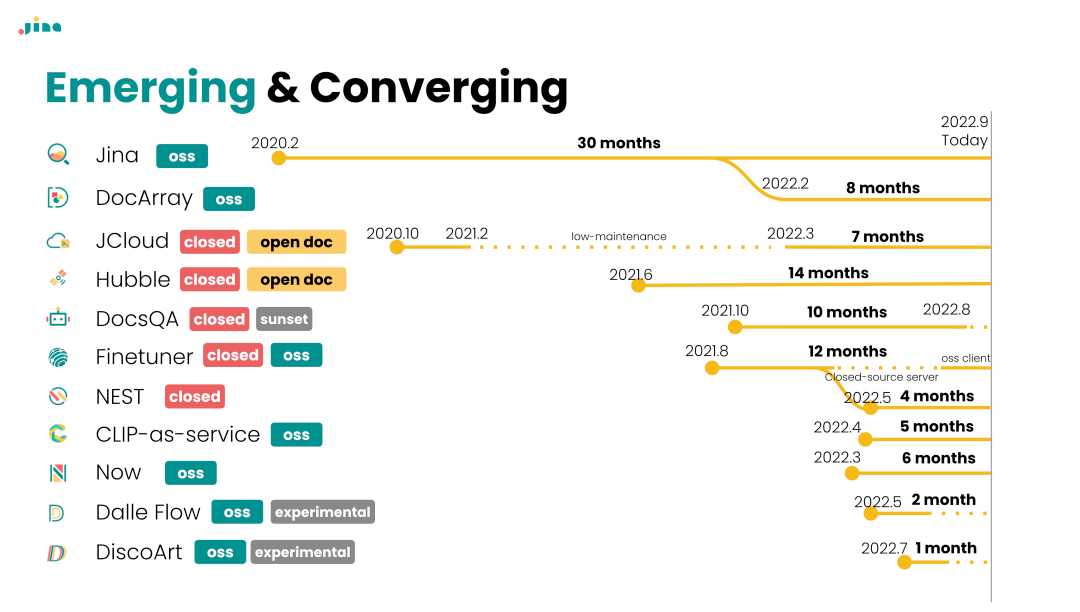
By the end of 2022, all our engineering projects aimed to encompass the entire AI Search Ops stack. ROI was calculated based on open-source community growth — pure R&D with zero revenue, essentially “powered by love,” which was the early business model for many commercial open-source startups.
However, overall, the growth of this framework’s community began to stagnate at the end of 2022. I personally used it less and less, and after 2023, I basically stopped using these frameworks for anything. I realized that the community increasingly needed a lightweight search development experience — something that made it easy to swap out LLMs, iterate prompts, and quickly run RAG output “vibe tests.” That’s why tools like LangChain and LlamaIndex became extremely popular in early 2023.

Zhang Sa: So did you ever use LangChain or LlamaIndex for development later?

Xiao Han: No, not even once.
Ever since I rejected our own company’s framework in 2023, I’ve lost interest in all glue code and sugar-water code, and I don't have confidence in any frameworks. Especially looking from the perspective of 2025 — when most code can be directly generated by large models — the necessity of learning glue code and opinionated frameworks simply disappears.
Frankly speaking, unless these frameworks are strongly bound to hardware features (for example, Google SDK binding with Google Cloud, or CUDA binding with NVIDIA GPUs), there’s no reason for developers to spend time learning an intermediate layer, regardless of whether its author is an online celebrity or anyone else.

Zhang Sa: You mentioned that in 2023 you explored two different new directions — why did you ultimately choose to focus on models?

Xiao Han: At that time, we had two internal teams — one focused on prompt-based AI productivity tools, involving many interesting prompt engineering techniques. My idea was to use UI/UX to present certain productivity APIs. This was also our first attempt at commercialization and generating revenue.
I led the team to spend quite some effort embedding Paywalls into these web apps, designing Stripe payment APIs, and user conversion funnels, etc. When we first saw a Slack notification that $10 had been credited to our account, everyone was really excited.
I recall that we built five or six apps in a year. Even though they were all eventually axed, the experience of commercialization and our early exploration of the Token Economy provided useful inspiration for later designing Paywalls for models.

In 2023, during a period of uncertainty, we developed five generative AI web applications aimed at boosting productivity through prompts. These apps brought in some new users and revenue, but by 2024, they were all cut at once.
The main reason we didn’t continue down this path was the realization that our company’s DNA wasn’t suited to developing UI-based products. Although we were developing every day, almost no one internally actually used these apps. I believe that to make a good app, UI/UX design and attention to detail are crucial, as they carry the product’s narrative logic. If you don’t use your own app, many design and logic issues will go unnoticed and unoptimized.
In short, the DNA and culture for consumer-facing apps did not exist in our company, which was related to the type of people we hired.
---
Interestingly, reflecting on these experiences today, I see parallels with how creators are now building and monetizing AI-powered tools or content without heavy frameworks. For example, platforms like AiToEarn官网 provide an open-source, global AI content monetization infrastructure that lets creators generate content with AI and publish it across multiple platforms — Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter) — all while tracking analytics and model rankings. This kind of ecosystem enables lightweight, hardware-independent workflows and direct monetization, which aligns well with the philosophy I adopted post-2023.
For more details, see AiToEarn博客 or explore the AiToEarn核心应用 platform.
The second issue is that although these Apps generated some revenue, they lacked a unified narrative logic. From the outside, they appeared fragmented, diluting the Jina AI brand image — which is fatal for a startup.

Zhang Sa: You chose the path of focusing on models and cut off the Wrapper Apps route. Was it difficult to implement this decision internally?

Xiao Han: There was quite a bit of resistance.
On one hand, the Wrapper Apps had fast development iterations and each brought in a certain amount of revenue. For a team with little experience in commercialization, this served as both encouragement and a learning opportunity. The problem, however, was that the Wrapper Apps lacked a consistent narrative, making it seem like we were firing shots in random directions.
On the other hand, the model side emphasized meticulous, slow craftsmanship, with a much slower development pace than the Apps. The two teams' cultures and rhythms were very different. In October 2023, we open-sourced jina-embeddings-v2, which featured 8K long text support and performance on par with OpenAI’s text-ada002. It blew up overnight on Hacker News, which surprised me and boosted the model team’s confidence significantly.

At the end of 2023, one of our company promotion flyers showed that the embeddings product line had taken shape. But I hadn’t yet fully switched to focusing on models — I was still promoting PromptPerfect and SceneXplain, two AIGC Apps — for two reasons: first, the narrative around the foundational search model wasn’t yet fully established, and second, AIGC was generating some revenue, which I was reluctant to give up.
Maintaining these two directions isn’t a great story for a startup. Finally, in February 2024, after I arrived in the San Francisco Bay Area, I decided to completely stop App development, reorganize the team, and optimize headcount to fully focus on model development.
During those months, I cut the company from over 60 people to just over 30, removed all App information from the website, with one single purpose: focus.

Zhang Sa: From the outside, Jina AI seems like a completely different company starting in 2024. Why do you think that is? Is it because of your time in the U.S.?

Xiao Han: I’d say that starting in 2024, Jina AI became lean & mean, based, no bullshit.
Learning from past mistakes — the 2020–2022 framework nobody loved, the overly scattered Apps in 2023 — I realized that a clear narrative is critical for a startup. Bugs in a framework can be fixed, lagging models can be improved, declining App engagement can be marketed. But if a company lacks a clear narrative, collapse is inevitable. And the simpler the logic, the better; don’t try to make it some second-order or advanced reasoning.
Much of this was influenced by my reflections during my time in the Bay Area, and by books I read during Christmas 2023: Richard Koch’s The 80/20 Principle, Al Ries’s The 22 Immutable Laws of Marketing, and Richard Sutton’s “The Bitter Lesson”.
I realized the company needed a complete refocus from the inside out — removing 80% of directions, management, personnel, and marketing, to find that most critical 20%. Visiting many excellent startups in the Bay Area left me deeply impressed by their extremely lean team culture.
This kind of strategic sharpening reminds me of how platforms like AiToEarn官网 help creators and startups streamline focus: by providing open-source AI tools for generating, publishing, and monetizing content across major platforms in one unified workflow. Just as we honed in on our core product narrative, AiToEarn enables individuals and teams to cut out distractions, align on a central strategy, and maximize the value of their work across the entire network.
At the beginning of 2024, the entire Bay Area, under the influence of figures like Elon, Trump, Peter Thiel, and Marc Andreessen, had already begun shifting culturally toward the right and toward accelerationism. One of the most common terms I heard in the Bay Area at the time was e/acc (Effective Accelerationism). Throughout 2024, I deliberately set e/acc as my Twitter and Slack signature, as a reminder to avoid getting dragged into empty distractions or wasting time—focusing instead on meaningful innovation. But here in 2025, far fewer people mention e/acc; perhaps everyone has already been “accelerated” to the point of numbness.
In short, since 2024 I’ve flattened the organizational architecture at our company to the extreme, removing all message-passers and ineffective middle management—everyone Heads Down and Hands On.
My goal is to rebuild Jina AI into a premium brand in the search domain. For example, we insist on craftsmanship: each time we release a model, we also publish an academic paper. In quiet research periods, we use high-quality blog content as a substitute for quick, gimmicky online marketing.
---

Zhang Sa: But is training models easy? It should be harder than making applications, right?

Xiao Han: Indeed it’s hard—so fewer people do it.
Especially when we focus on high-quality small search models, our competitors become very clearly defined: Voyage, Google, Cohere, Mixbread, Nomic AI—basically just these few.
Voyage and Cohere are closed-source; Google and Cohere both also want to fight the large-scale model battle, so they don’t focus 100% on small search models. Mixbread and Nomic AI have relatively smaller communities than we do, but they still provide excellent open-source vector models and rerankers.
I believe it’s crucial to clarify competitive relationships. Startups must never avoid or fear competition; instead, they should face it head-on—but it’s critical to pick the right opponents before stepping into the arena. Targeting the wrong competitor and going all-out is a pure waste of energy.
From an open-source community perspective, the Qianwen team also counts as a competitor. This year, their open-source qwen-embedding and qwen-reranker have had significant impact within the open-source community. While Qianwen doesn’t rely on these models for profit (whereas we do), they still take a fair share of attention from us. Whether it’s Qianwen or Beijing Academy of Artificial Intelligence’s BGE, they are both “frenemies” to us—competitors we simultaneously learn from and borrow ideas from.
---

Zhang Sa: Since Qianwen can build vector models, and Gemini can build vector models, what advantages does a company like Jina—which focuses on building small search models from scratch—have compared to large model companies?

Xiao Han: I’ve always believed in this: when a company has no upstream or downstream supply chain advantages and no technical moat, the only moat comes from its own operational efficiency. This is my pessimistic “Minimum Moat Principle”—if we are bad at everything else, then we use extreme focus and near-autocratic management to drive the team forward at a sprint.
I have already prepared for the most pessimistic scenario, but reality isn’t as bleak:
- Over the years we’ve accumulated a solid amount of high-quality labeled data. Our team has many Europeans, so we’ve amassed significant expertise in manually evaluating and labeling multi-language recall models for European languages.
- We have a substantial customer base, including nearly 10,000 paying customers brought in by Jina Reader. They collectively generate about 200 billion tokens of API usage daily. We continuously receive feedback and suggestions from these paying customers, which effectively help us improve model performance and API design.
- We have years of experience in search model training and sensitivity to technological trends—knowing when to early stop, when to dig deeper, and which emerging techniques are promising versus just noise.
I estimate the “half-life” of a model today to be roughly five to six months—meaning its value halves about every half year. After a year, the model essentially has no application value and will be replaced by better ones. This means our competitive advantages are always in dynamic evolution.
---
In the broader AI content ecosystem, the challenge of keeping models relevant and competitive is paralleled by the evolving ways creators distribute and monetize their work. Platforms like AiToEarn官网 are exploring open-source approaches to help creators generate, publish, and monetize AI-driven content across multiple channels—from Douyin and Kwai to YouTube and X (Twitter)—bringing both technical agility and operational efficiency into the content space, much like we aim to do with AI models.
I believe that aiming for first place is certainly important — getting there is ideal — but being always part of the game and never giving up is equally crucial. For example, in 2024 I set my team's goal to be the "Pepsi" of the industry, the solid No. 2, so we could be remembered first.
Finally, there’s a point that might sound a bit abstract to many technical people — model tone and brand value. In today’s constantly evolving AI model landscape, fostering user loyalty through brand recognition becomes extremely important. In simple terms, Brand Value = Technology + Marketing (e.g., technical blogs, academic papers) + Customer Experience (website, API).
For instance, many people say the Porsche Cayenne is essentially a rebadged Volkswagen Touareg or Audi Q7, since they share similar chassis. Yet customers still prefer Porsche more — thanks to its long-standing sporty chassis and engine tuning style, racing heritage, and the scarcity emphasized in its marketing.

At the end of 2024, we released our annual magazine Re·Search. The name implies Rethink Search, and also Research. It featured a selection of our 2024 technical blog posts. This “little red book” made a strong impression on users thanks to its design style and solid content, further reinforcing Jina AI’s brand tone.

Zhang Sa: In the fall of 2024, I remember you gave an interview to Paperweekly about the future of small search models. Do you think those views still hold today?

Xiao Han: That was back in September last year, and even after more than a year, most of it still applies.
For example, I said back then that small models are not inherently small — they are distilled and pruned from large models. This means that large-model vendors have significant advantages when they build small models, because they already know the original model’s vibe and where to cut. This was validated this year — Qianwen and Gemini did exactly that.
The difference from last year’s perspective is that, due to the emergence of new design paradigms in 2025 such as Agentic Search and DeepResearch, many use cases for traditional vector retrieval models (including re-rankers) have changed.
Previously, these retrieval models were largely focused on database I/O, handling tens of billions of records. Today, they’re more often used as small utilities inside context windows for Context Engineering tasks — like deduplication, filtering, and token compression. This requires models with smaller parameters and faster speed, and also optimization for previously overlooked tasks (e.g., STS tasks designed specifically for deduplication).

Zhang Sa: Let’s talk about this acquisition. How did you first connect with the buyer?

Xiao Han: I first worked with Elastic around the end of 2023. They noticed our jina-embeddings-v2 performed well and wanted to do an API integration. We set up a shared Slack channel to start collaborating.
In 2024, after I came to the Bay Area, I met their management team at their San Francisco office. We casually chatted about work and life. Then in the summer, while I was in the U.S., I had several long discussions with their leadership. I gave multiple hours of presentations at their SF office to the founder, CEO, CPO, etc., and we realized our technologies complemented each other highly. The top management was very friendly and trusting toward me, so that started the acquisition process.
Overall, early groundwork, trust foundation, complementary direction, and a bit of luck were all very important factors in making the acquisition happen.

Zhang Sa: Many of us don’t really know what an acquisition entails. Could you walk us through the process briefly?

Xiao Han: Acquisitions are extremely complex and tedious — especially when the buyer is a publicly listed U.S. company, where regulations are extensive. It really feels like losing a layer of skin in the process. Normally, you’d hire a professional M&A investment banking team to execute such a deal. But I’m relatively lean and frugal, so I did it all “by hand” myself. And surprisingly, it worked out — making the whole experience quite memorable.
---
In reflecting on both brand-building and technology strategy, it’s clear that blending strong technical capabilities with consistent brand tone is a long-term differentiator — whether you aim to be first or a memorable second. For creators and teams looking to make their mark across multiple platforms and markets, platforms like AiToEarn官网 offer streamlined ways to generate AI content, publish across global channels, and monetize efficiently — integrating tools for creation, cross-platform delivery, analytics, and even AI模型排名, making brand and technology work hand in hand in today’s competitive landscape.
For Jina AI, the process involved many complex factors — including geopolitics between the U.S. and China (and, of course, Germany), multi-party negotiations among multiple buyers, the bargaining between buyer and seller, investor dynamics, as well as internal employee considerations. Additionally, because the buyer was a publicly listed company, the acquisition timeline had to align with their quarterly financial reports and Analyst Meetings.
From signing the LOI (Letter of Intent) in July, to preparing the data room for the SPA (Share Purchase Agreement) in August, to coordinating multi-party SPA signatures in September, and then swiftly fulfilling closing conditions — whether relocating employees or re-signing offers — all the way to the final public announcement in New York in October, these months were intensely demanding. I worked with my lawyers tirelessly across time zones, with multiple meetings each day; the buyer’s lawyers faced similar challenges. Even today, there remain ongoing post-acquisition tasks, mainly because Jina has maintained offices in multiple countries over the years, requiring step-by-step resolution.
Overall, I believe Jina AI’s organizational structure was significantly overengineered. For a company of fewer than 30 people, our structural complexity made the acquisition process feel like buying a multinational with hundreds of employees.
However, the most exhausting part was dealing with human nature exposed during the acquisition process. Under immense time pressure, I had to stand alone representing the company in negotiations with numerous internal and external stakeholders — it was one of the most stressful experiences in my career.
---

Zhang Sa: So, do you think the ultimate outcome for a "Model-as-Product" company is acquisition?

Xiao Han: Pretty much. Either you pivot toward building products and applications, or you aim for general-purpose large models, raise more funding, and go public.
If you are only building specialized small models — for example, in search — whether Voyage or Jina, the road tends to end in acquisition. The reason is simple: talent for small models is no cheaper than talent for large models. Since we aim for top-quality small models, we can’t cut corners on talent costs. The current token-based pricing economy doesn’t yet cover the GPU inference costs, leaving margins thin.
Looking back, when I decisively cut the App and focused on small models at the start of 2024, the endgame for Jina narrowed to either acquisition (or, alternatively, closure). What remained was just a question of time and whether I could succeed.
If you deliberately avoid disclosing revenue — because doing so fixes your valuation — then the only way to secure funding is to tell a bigger story. Yet small-model stories simply don’t scale. It’s like comparing street-side spicy skewers to Haidilao hotpot. Small models are like street food: after work, lots of people stop by. This isn’t to say there’s no market — investors know street food smells great — but they still prefer to invest in Haidilao (large models).
---

Zhang Sa: If the endgame is acquisition, then what’s the point of making revenue?

Xiao Han: Revenue is still necessary, for several reasons.
First, it validates PMF (Product-Market Fit), showing whether the market really needs such models and whether you can stand out amidst competition. Before 2023, we tracked many community metrics — downloads, GitHub stars, social media discussion volume, etc. Later, we realized these indicators were often fleeting and only weakly correlated with PMF. Nothing is more solid than actual paying customers. After all, a user saying they like your model and giving a thumbs-up is one thing; spending real money to buy it is entirely another.
---
In reflecting on these acquisition dynamics, it’s clear that small AI-focused companies often face structural and strategic constraints that push them toward acquisition. This is especially true when funding narratives favor large models over niche ones. In today’s AI ecosystem, platforms like AiToEarn官网 offer an alternative or complementary path — enabling creators and companies to use AI for cross-platform content creation, publication, and monetization across channels from Douyin to YouTube, all while integrating analytics and model performance ranking (AI模型排名). For AI entrepreneurs, leveraging such open-source tools may provide additional revenue streams and visibility, potentially influencing the strategic options beyond acquisition.
The Second Point: Cultivating Team Understanding of the Token Economy
It’s crucial for the team to fully grasp the fundamentals of the Token Economy:
How many tokens are used in the entire training corpus? How many tokens are in each batch?
What is the token/s speed during inference? What is the maximum token length?
What’s the median token count of user inputs? What’s the time to the first token returned?
What is the maximum number of tokens allowed per minute?
In multimodal cases such as images, how should token calculation be reasonably defined?
Only when everyone in the company can readily recall these figures will they truly understand the value of a token and make model training and inference more efficient and professional.
Back in early 2024, when we first introduced a Paywall for our Model API, many people had no concept of free token quantities or pricing. Internally, some argued that giving away 100,000 free tokens was excessive — that users would never finish them. This revealed a lack of understanding about the Token Economy.
Today, each new API Key comes with 10 million free tokens, ensuring a smooth experience for users making multimodal image inputs or long text submissions. The paid tiers have undergone multiple rounds of optimization and redesign, ensuring that inference services maintain a positive profit margin.
---
My Personal Belief on Entrepreneurship
To me, starting a company means aiming for profit. Spending investors’ money to pay salaries is not a particularly proud achievement.
Since transitioning our company to a "Model as Product" approach, I’ve wanted to explore its limits — to understand exactly what its real profitability can be.
If a team’s purpose is solely technology for technology’s sake or social media influence, they might as well work in academia.
---

Zhang Sa: “So looking back over these years, what do you think you did right at Jina, and what mistakes did you make?”

Xiao Han: Looking back, the things I did right include:
- Building an international team from day one. This laid a solid foundation for talent recruitment, market expansion, and acquisition opportunities in later stages.
- Leading by example and being hands-on. Over the years, I’ve likely written more code at Jina than anyone else. I used to joke internally:
- > “If Jina ever fails, it’ll definitely not be because the CEO didn’t write enough code — but maybe because I wrote too much.”
Whether it’s engineering R&D, commercialization, marketing operations, sales, or customer support, I personally get involved.
I believe the founder must maintain the highest level of enthusiasm, no matter how many years have passed. If the founder checks in every day just to lie flat and do nothing, the company is finished.
- Exploring commercialization carefully. From zero revenue in 2023 to $2M ARR at the time of acquisition, as a pure Model-as-Product API startup, with no ads and purely organic growth via word of mouth, I think this was a decent result. I trekked the road from zero to million ARR, hit every pothole, and can serve as a guide for others.
- Continuous learning and adaptive change. I adjusted and optimized the company in response to the wider environment, including multiple reworks of organizational structure and narrative direction. These are essential actions, and must be led by the founder.
---
Mistakes I Made
- Lack of focus. In the years after our Series A, the team became too scattered in its priorities due to chasing too many meaningless tech and marketing directions, wasting time and money.
- Expanding without clarity. When our focus was unclear, I tried to solve it by expanding the team — parachuting in leaders to fix product lines and focus. This had minimal impact.
- In hindsight, if I scored all the leaders over the past six years, out of 10 points, I’d give 2.
- Many leaders couldn’t keep pace or perform well in an environment with survival pressure and rapid technological change.
- I neither found nor cultivated truly outstanding leaders.
- Not understanding the team’s Scaling Law.
- From 2020 to 2023, the team kept expanding, but output and brand strength declined.
- Since 2024, I’ve been downsizing the team — from 60 down to 30 — dramatically improving efficiency and brand value.
Following this logic to the extreme: Team size and brand value seem inversely proportional!
---
“Small but Beautiful” Is Not the Endgame
If every company took pride in getting smaller and more refined, giants like Google and Microsoft wouldn’t exist.
So figuring out how to scale an AI team and grow the business is my biggest regret over the past six years — something I haven’t yet succeeded in.
---
Incidentally, one promising approach to balance efficiency, scale, and monetization in AI teams is leveraging platforms that integrate content generation, publishing, and analytics across multiple channels. An example is AiToEarn官网, an open-source global AI content monetization platform. It enables creators and companies to use AI to produce content, publish it simultaneously on major platforms including Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter), with connected tools for analytics and model rankings. For AI-focused businesses, platforms like AiToEarn开源地址 can offer practical ways to scale distribution without losing operational clarity.
Growth without revenue is a disaster; revenue without growth is boring.
I pulled my company out of the blind expansion disaster, then worked carefully to avoid sliding into boring.
Although strong leaders shouldn’t complain about the environment, I think one big mistake I made was holding too many expectations and fantasies about Europe and Germany. It wasn’t until I arrived in the Bay Area in 2024 that I realized I had wasted a lot of precious time in an overly mediocre place.
The political leanings and conservatism of German and European society, the tendency to treat AI as a purely theoretical or fear-driven topic, labor laws that neither understand nor respect entrepreneurs, and the indifference toward top talent – all of these left me deeply disappointed with Europe and Germany after 2023.
In 2023, I invited several German colleagues to join me in lobbying efforts, hoping to engage more with the European Parliament and German politics to gain attention and resources. After a year of numerous events, progress was zero. Eventually, I realized they only invited me to those parliament and party congress meetings as a Diversity Guest: they didn’t need my expertise, only that Asian face.
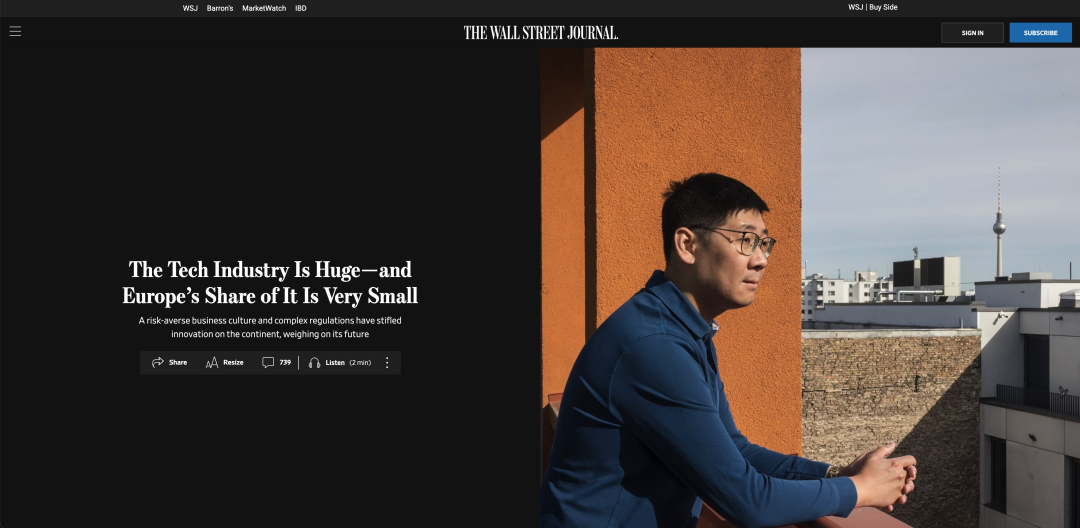
In the spring of 2025, I accepted an interview with The Wall Street Journal and voiced my complete disillusionment with Germany and Europe. Europe assumes its lagging position in AI is an isolated phenomenon, but in reality, it’s the result of the broader social and economic environment. The report sparked plenty of discussion, but in Europe I have no expectation that much of this will be put into practice.
Many talk about the American Dream, but the truth is, I didn’t make real progress until I came to the U.S. Whether it was building a lean & mean company culture, re-establishing the Jina brand, or ultimately being acquired by a publicly listed American company — this place not only motivated me, it truly rewarded my efforts.
No matter how cruel the competition or collaboration, the development of AI is absolutely a China-US matter — just like Naruto and Sasuke: a love-hate rivalry. Europe, on the other hand, is like Sakura — to be blunt, it’s hardly relevant.
---

Zhang Sa: Will you start another business?

Xiao Han: Entrepreneurship is engraved in my bones, so I think I will eventually. But for now, I need to accumulate more, reflect further, and gain deeper understanding.
For example, we can all see how this wave of AI has boosted productivity. Many engineers feel they could start a business and monetize that productivity. But productivity improvement ≠ value capture improvement — it doesn’t automatically mean you can turn it into profit.
Some might say, “This year, because I mastered Cursor/Claude Code and delivered several projects, my boss rewarded me with a bonus.” In a company environment, productivity improvements can be monetized because the company has already solved the value capture problem — existing clients, sales channels, brand trust. If you produce 10% more, the company’s monetization engine can convert that output into income, and you receive a share.
In entrepreneurship, facing the market independently, AI only strengthens the supply side (you can do more, faster) without enhancing the demand side (finding customers, building trust, completing transactions). Put simply: productivity is “the ability to make things,” not “the ability to sell things.”
If everyone directly puts multiplied productivity into the market, supply rises collectively, the unit price may drop, and in the end, no one actually makes much money.
---

Zhang Sa: Do you currently see any promising directions for startups?

Xiao Han: Last year I said I was quite interested in AI + original games. In original games, there are clear multimodal application scenarios: assets, storylines, NPC logic — all of these can improve as large model capabilities rise.
Games are already a mature business model: paid downloads, in-app purchases, subscriptions. AI-driven productivity gains (more diverse assets, more human-like NPCs, more personalized narratives) directly enhance player experience — and experience is something you can put a price on.
---
In fact, these discussions about productivity and monetization resonate with some emerging platforms like AiToEarn官网. AiToEarn is an open-source global AI content monetization platform that helps creators use AI to generate, publish, and earn from content across multiple major platforms simultaneously — including Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). By connecting AI content generation, cross-platform publishing, analytics, and model ranking, AiToEarn provides a clearer path from productivity improvements to value capture — something many AI-driven entrepreneurs are still seeking.
The bottleneck lies in how to shape a popular IP:
Classic IPs are held tightly by major gaming companies, and for independent developers, creating an IP from scratch is no easy feat. This brings us to the OC (Original Character) community. A project I previously invested in, Riceball Island, works in this space. You can think of it as a decentralized IP incubation pool, where users themselves imbue characters with emotional value and viral potential. If AI can lower the barrier for OC creation and make expression richer, it is, in a sense, accelerating the “democratization of IP” — no longer just the privilege of big studios. Riceball Island took a very clever approach here.
AI Trading has been gaining momentum in recent months — for example, AlphaArena uses large language models for quantitative trading in secondary markets, or conducts sell-side investment research in primary markets. I think this is a promising direction. The most hardcore aspect of this field is that returns are quantifiable, real-time, and require convincing no one. If your model is just a bit smarter than the market, you profit. You don’t need branding, sales, or user growth: the market itself is the most efficient judge.
Especially for Buy-side signal capturing, this essentially bypasses the entire “AI productivity” narrative and directly maps AI’s cognitive ability into alpha. This may be among the least friction monetization paths for AI. I’ve recently been talking to a project from Berkeley and Stanford called Tauric Research, which uses the Jina Reader API for information acquisition and sentiment analysis, feeding this into a custom reasoning model to generate trading signals. This is a much stronger story than "boosting productivity," because the downstream is directly money.
Of course, AI Trading competition is brutally intense — everyone is playing in the same market, and your alpha is someone else’s negative alpha.
---

Zhang Sa: Lastly, can you give some advice to future founders?

Xiao Han: Focus, and emphasize the narrative logic of your company.
The founding team should remain lean — do not just add people for appearances. If you’re strong enough yourself, start alone. If you’re not, or have no clear idea, my advice is don’t start yet.
Put maximum effort into finding smart people and high achievers, and work with them. These are the ones who know first principles and the 80/20 rule by heart, act decisively, and never regret. That’s what a startup team needs.
Earlier this year, an undergraduate from MIT came to Berlin to intern with us. She’s a Ukrainian girl, Sheldon-like in personality, not great at socializing but incredibly smart. I asked her why she traveled so far to Berlin (implying: you’re an MIT student, with so many opportunities in the U.S.). She answered instantly: her parents live in Berlin and she wanted to reunite with them; she had applied to Amazon Berlin, but they refused to disclose the internship content; in contrast, Jina told her clearly that she’d work on small models — exactly her favored area. So she came. Not a moment of hesitation.
Later I asked her: at 18, a young woman, traveling alone from Ukraine to Boston — wasn’t she afraid? Her answer has stayed with me ever since:
> “I’m not afraid. The ones who should be afraid are my parents — because they still live in a war zone.”
She stayed in Berlin for three months, trained an extremely strong jina-code-embeddings, wrote a paper, got into the NeurIPS Workshop, and then left — all executed as cleanly and decisively as she spoke.
She’ll also attend this December’s NeurIPS in San Diego. Friends at the event, feel free to say hello to her for me.
Lastly: avoid wasting time with mediocre people. You can recognize them easily — they work sluggishly, make hesitant decisions, shy away from competition, and retreat under pressure.
Don’t think “I can train them” or “I’ll give them more time.” Startups are a game of near-certain death, not like university. You don’t have time to polish a 60-point person into a 90-point one; you need to find those who are already 90-pointers and fight alongside them. So:
Don’t pray for an easy life, pray to be a stronger one.
---
Interestingly, for creators who aim to build strong IPs or leverage AI for trading, cross-platform reach and monetization are becoming equally vital. Tools like AiToEarn官网 offer an open-source global AI content monetization platform, enabling simultaneous publishing to Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). With integrated AI content generation, analytics, and model ranking, creators can efficiently turn AI-powered ideas into revenue streams — a natural next step for those pursuing either creative or algorithmic excellence.
(End of text)


