Jiushi Intelligence: Multi-Cloud Billion-File Storage for Autonomous Driving Powered by JuiceFS
Zelos of Jiushi Intelligence: Building Scalable Storage for Autonomous Driving
Jiushi Intelligence is a high-tech enterprise specializing in autonomous driving and unmanned delivery technologies. It has developed proprietary autonomous driving systems and AI chips capable of large-scale deployment.
With products rolled out in over 200 cities across China, Jiushi holds over 90% market share in complete vehicle sales in the L4 urban freight autonomous driving segment.
---
Business Growth vs. Storage Bottlenecks
Rapid expansion pushed Jiushi's data volume from terabytes to petabytes. The original Ceph-based storage solution began to struggle:
- High costs and maintenance complexity
- Performance bottlenecks for small files, metadata operations, high concurrency, and low-latency needs
- Impact on simulation and training efficiency
Additional challenges included:
- Frequent multi-cloud data transfers
- Data fragmentation and high migration costs
- Complex scheduling
- Limited community support for certain tools
---
Solution: JuiceFS Unified Storage Infrastructure
Jiushi required a cloud-native, scalable, and low-maintenance storage architecture. After evaluating Alluxio, CephFS, and JuiceFS, they selected JuiceFS as their unified, multi-cloud storage layer.
All core business data — production, simulation, training, and inference — is now stored on JuiceFS, enabling:
- Efficient massive data handling
- Flexible multi-environment deployment
- Unified infrastructure for varied autonomous driving workflows
---
1. Autonomous Driving Workflow & Storage Needs
Training Workflow Steps:
- Data Collection & Upload — onboard calibration, data capture, and upload.
- Algorithm Processing — model training/improvement, pass results to simulation.
- Simulation Verification — if fail, iterate with algorithm team; if pass, move to test vehicle stage.
- Test Vehicle Verification — if pass, deploy via OTA.
Key storage requirements:
- High-performance I/O for massive small-file reads and low-latency access
- Elastic scalability to multi-PB levels
- Cross-cloud compatibility for unified access
- Operational simplicity for long-term stability
- Cost efficiency without sacrificing performance
---
2. Storage Options Compared
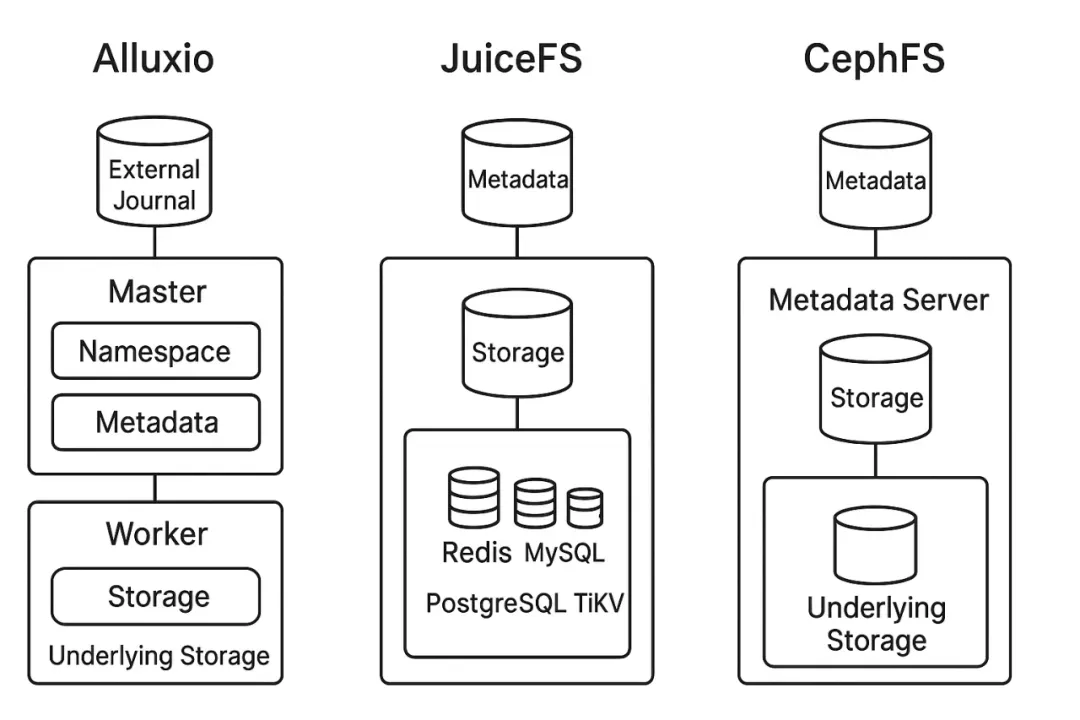
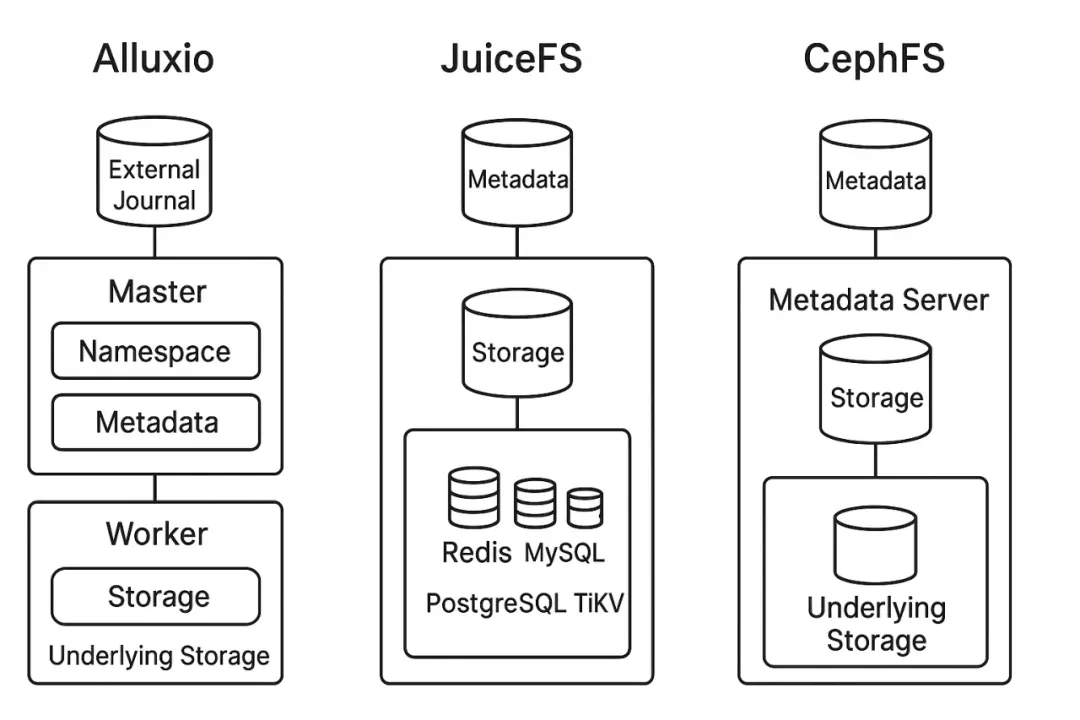
Alluxio
- Complex deployment: Master + Worker clusters
- Steep learning curve
- Issues in community edition: hangs, I/O anomalies
Architecture of various file systems
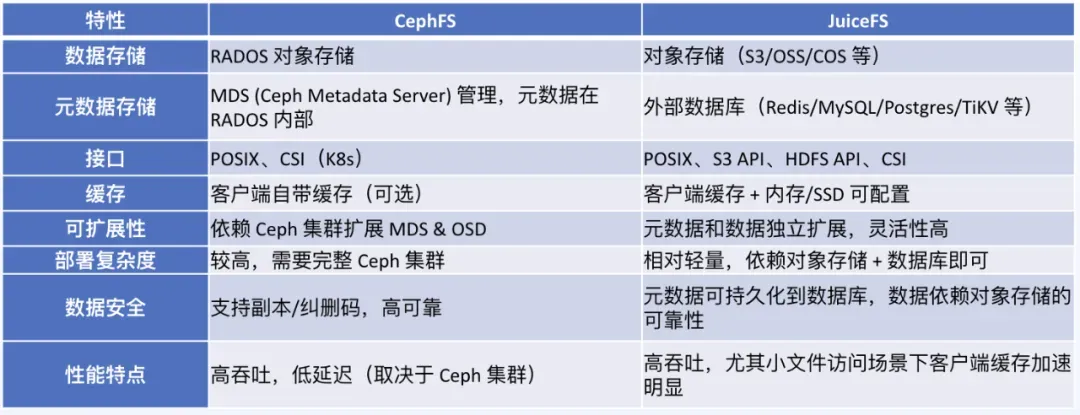
CephFS
- Metadata stored on MDS, data in RADOS
- Complex operations: expansion & rebalancing are slow
- Poor small-file write performance
JuiceFS
- Flexible metadata layer: Redis, TiKV, MySQL, SQLite
- Supports multiple backends: S3, OSS, MinIO
- Simplified deployment with strong small-file performance
- Fits multi-cloud architecture used by Jiushi
---
3. JuiceFS in Multi-Cloud Deployment
Architecture
- Separate metadata & data layers
- Metadata engines: Redis, MySQL, TiKV, SQLite
- Data layer: mainstream object storage systems
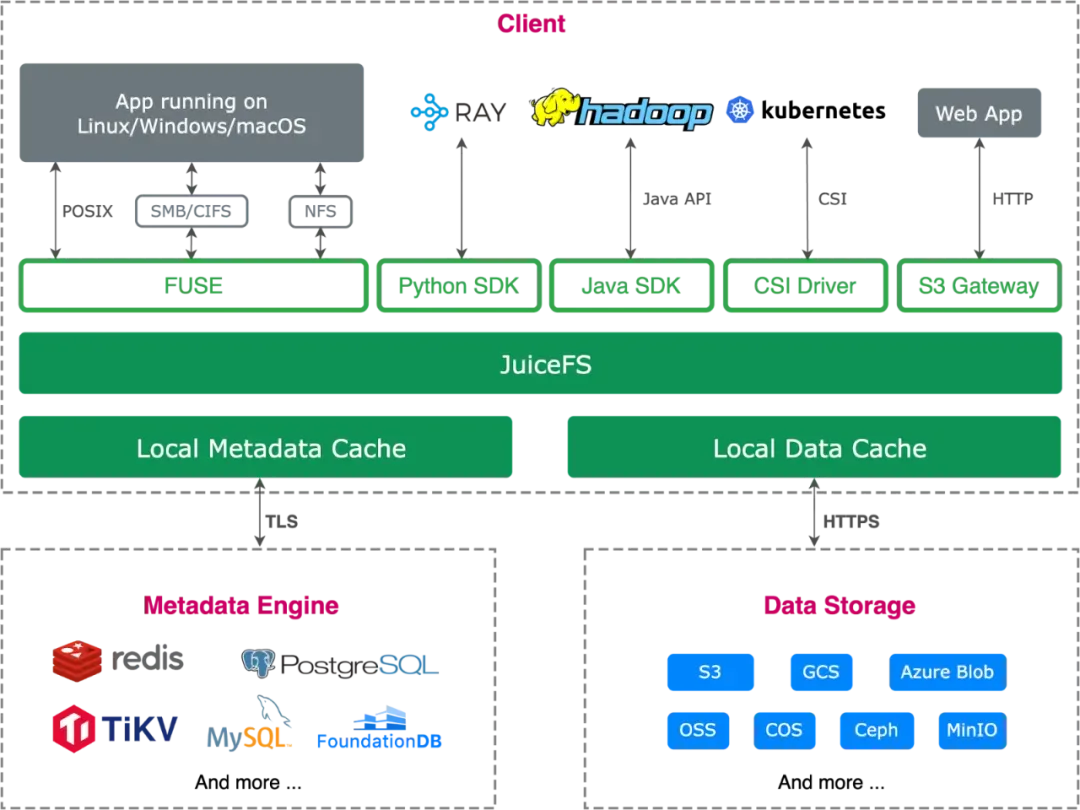
JuiceFS Community Edition Architecture
Jiushi’s Deployment
- Multiple clouds: China Unicom, China Telecom, Volcano, China Mobile, AWS
- Self-built IDC: MinIO + Redis
- Public cloud: OSS + Redis
- Kubernetes integration via JuiceFS CSI driver and Helm Charts
- Local NVMe SSD caching improves read speeds significantly
---
Practice 1 — Training Platform Integration
Platform layers:
- Infrastructure — storage, compute, networking
- Kubernetes layer — service orchestration
- ML platform (Kubeflow) — GPU computing, multiple frameworks
Workflow:
- Training tasks submitted via Notebook or VR
- Resource scheduling via Training Operator
- PVC pre-provisioned JuiceFS storage
- Real-time monitoring of throughput: ~200 MB/s read-heavy patterns
- Metadata engine tuning: TiKV outperforms Redis for read-intensive scenarios
---
Usage Stats:
- 700 TB in one bucket
- 600 million files, mostly small
- JuiceFS handles high-concurrency small-file operations stably
- Simulation bucket: PB-level large files stored in China Mobile Cloud Object Storage
---
Practice 2 — Multi-Cloud Data Sync
Setup:
- Dedicated inter-cloud lines
- Custom sync tool built around `juicefs sync` command
- Sync same dataset to multiple clouds
Note:
Cross-cloud mounts are possible but network stability dependent — use cautiously.
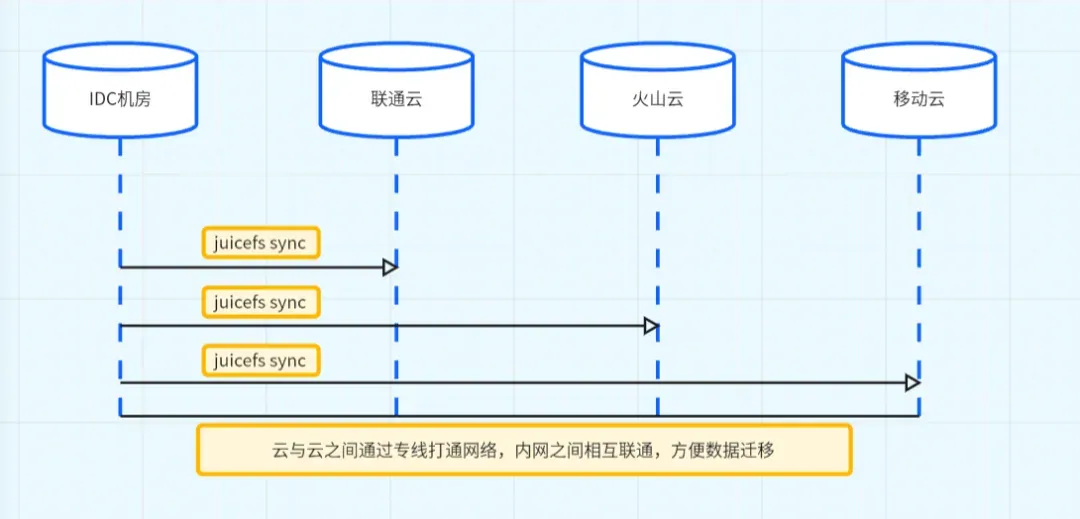
JuiceFS multi-cloud data synchronization architecture at Jiushi Intelligence
---
4. Summary & Future Direction
JuiceFS Benefits at Jiushi Intelligence:
- Handles production/simulation/training/inference workloads
- High-concurrency small-file performance
- Cross-cloud integrations with Kubernetes and Kubeflow
- Reduced O&M complexity and costs
- Stable at PB-scale data loads
Next steps:
- Wider TiKV adoption for metadata
- Improved cross-cloud sync mechanisms
---
Tip for AI & Content Teams:
Platforms like AiToEarn官网 offer an open-source AI content monetization framework for multi-platform publishing, analytics, and AI model ranking. When paired with scalable storage (like JuiceFS), such platforms can optimize workflows for data-heavy AI content pipelines in multi-cloud environments.
---
Would you like me to create a visual diagram summarizing Jiushi’s JuiceFS multi-cloud architecture for easier reading? That would make this case study even more accessible to technical teams.


