Just Now: DeepSeek Launches New Model, Small yet Powerful
DeepSeek Releases 3B DeepSeek-OCR Model
Moments ago, DeepSeek announced an open-source 3-billion parameter model — DeepSeek-OCR.
While 3B parameters might not sound massive, the innovative architecture behind it is remarkable.
---
Tackling the Long-Text Bottleneck
LLMs struggle with long sequences because computational complexity scales quadratically with sequence length.
More tokens = more compute cost.
DeepSeek’s key insight:
Large amounts of text can be embedded in fewer tokens if it's converted into an image.
They call this Optical Compression — compressing textual data by shifting it to a visual modality.
Why OCR?
OCR inherently performs visual → text conversion, making it an ideal test ground with measurable results.
---
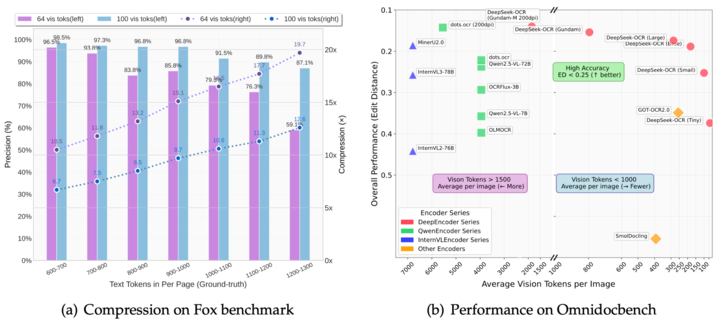
Compression Rate & Accuracy
Highlights from the paper:
- 10× compression rate while maintaining >97% OCR accuracy.
- Even at 20× compression, accuracy is about 60%.
What this means:
100 visual tokens can replace 1,000 text tokens with minimal loss.
OmniDocBench Results
- 100 tokens/page → beats GOT-OCR 2.0 (256 tokens/page)
- <800 tokens/page → beats MinerU 2.0 (6,000 tokens/page avg.)
Production Scale Example:
- 1 × A100–40G GPU → 200,000+ pages/day generation
- 160 × A100 GPUs (20 nodes) → 33 million pages/day
---
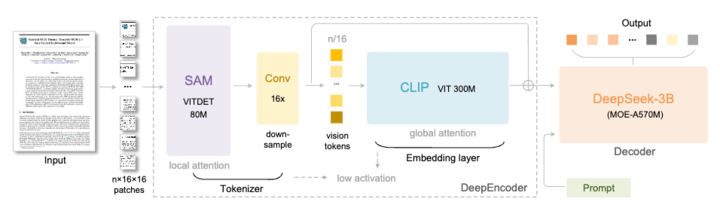
Core Architecture Overview
Two main components:
- DeepEncoder — Image feature extraction + compression
- DeepSeek3B-MoE Decoder — Text reconstruction
---
1. DeepEncoder — The Compression Engine
Architecture: SAM-base + CLIP-large in series.
- SAM-base (80M params) → Windowed attention for visual detail
- CLIP-large (300M params) → Global attention for holistic context
Key Feature: 16× Convolutional Compressor
- Reduces token count drastically before global attention
- e.g., 1024×1024 image → 4,096 patch tokens → compressed to far fewer tokens
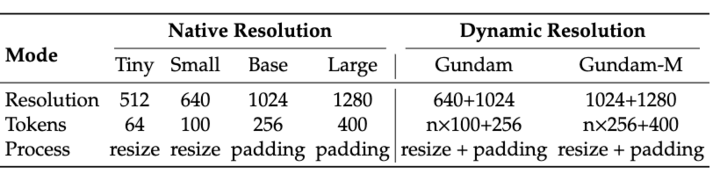
Multi-Resolution Modes:
- Native Tiny / Small / Base / Large
- Dynamic-res Gundam mode for maximum flexibility
---
2. DeepSeek-3B-MoE Decoder
- 3B total parameters
- Mixture-of-Experts (MoE):
- 64 experts (6 active per step) + 2 shared experts
- ~570M active parameters per inference
- Offers 3B-level representational power at 500M-like efficiency
Role:
Rebuild original text from compressed visual tokens — learned effectively via OCR training.
---
Data Scale
Collected 30M pages in ~100 languages:
- 25M Chinese & English
Types of data:
- Coarse annotation:
- Extracted with fitz for lower-resource language training
- Fine annotation:
- Generated via PP-DocLayout, MinerU, GOT-OCR 2.0
Model Flywheel strategy for minority languages:
- Cross-lingual layout model for detection
- Train GOT-OCR 2.0 on fitz-generated data
- Use trained model to label more data
- Repeat → 600K samples achieved
Other data collected:
- 3M Word docs → improved formula & table parsing
- Scene OCR: 10M Chinese + 10M English samples (from LAION, Wukong via PaddleOCR)

---
Beyond Text Recognition — Deep Parsing
DeepSeek-OCR can extract structured data from complex imagery:
- Charts → structured datasets
- Chemical diagrams → SMILES format
- Geometric figures → duplication & structural analysis
- Natural images → dense captions
This opens doors for STEM fields requiring symbolic + graphical parsing.
---
Optical Compression Inspired by Human Memory
Proposed experimental approach:
- Convert older conversation history beyond the k-th turn into images
- Stage 1 compression: ~10× fewer tokens
- Further reduce resolution for distant history
- Information fades like human memory decay — less detail in older context
Goal: Support infinite context by balancing fidelity + compute cost.
---
More Than OCR — A Visual Compression Engine
DeepSeek-OCR essentially tests if visual modality can compress text for LLMs.
Early results: 7–20× token compression.
Future directions:
- Alternating digital ↔ optical text pretraining
- Long-context stress tests ("needle in a haystack")
---
Resources
- GitHub: http://github.com/deepseek-ai/DeepSeek-OCR
- Paper: https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
- Model Download: https://huggingface.co/deepseek-ai/DeepSeek-OCR
---
AI Ecosystem & Monetization: AiToEarn Example
Creators can explore AiToEarn — a global open-source platform enabling:
- AI generation → cross-platform publishing → analytics → model ranking
Supported platforms:
Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
Links:
---
Would you like me to prepare a follow-up section on how Optical Compression can be integrated into multi-platform publishing workflows?
This could merge DeepSeek’s technical gains with scalable content deployment.