Just Now: Doubao Launches Multiple Large Models — Making DeepSeek Easier to Use, Audio Sora Wows the Crowd
AI in 2025: Performance vs. Cost — The Ongoing Dilemma
Frankly speaking — it’s already 2025, yet asking AI questions still feels polarized:
- Simple queries: Responses come instantly, but sometimes feel incomplete.
- Complex queries: Requires deep reasoning, taking over 30 seconds to respond.
- Token burn: Every reply consumes tokens, directly impacting business costs.
For enterprises, token consumption = cost. Deep reasoning improves results, but increases latency, consumption, and expenses — a persistent, industry-wide pain point.
---
Token Usage Explosion
AI adoption is accelerating:
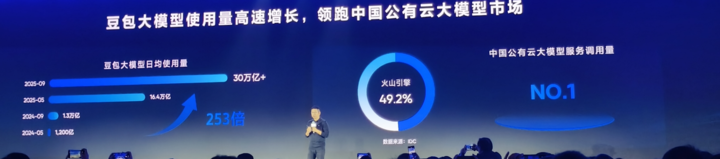
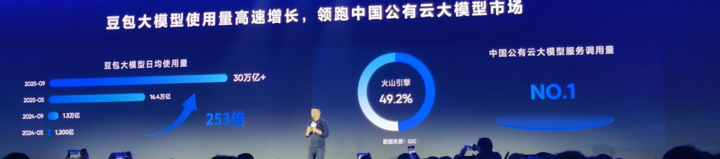
- Doubao Large Model daily calls exceeded 30 trillion tokens by Sept 2024, up 80% since May.
- This is just one segment of the global market.
Companies face a trade-off:
- Lightweight models: Save money, sacrifice quality.
- Top-tier models: Deliver quality, incur high costs.
---
Volcano Engine’s Answer: Balancing Quality and Cost
October 16 — FORCE LINK AI Innovation Roadshow, Wuhan:
Volcano Engine unveiled four new products:
- Doubao Large Model 1.6 — Native support for 4 adjustable thinking lengths.
- Doubao 1.6 Lite — Halves costs, improves results.
- Doubao Speech Synthesis Model 2.0.
- Voice Cloning Model 2.0.
📊 IDC Report: 1H 2025 — Volcano Engine captured 49.2% of China’s public cloud LLM service market.
Translation: 1 in 2 companies using cloud-based large models is on Volcano Engine.

---
Tackling Low Adoption of Deep Reasoning
At launch, one insight stood out:
- Deep reasoning mode boosts results by 31%,
- But due to latency, cost, and token usage, adoption is only 18%.
- In short: Businesses want it, but can’t afford it.
---
Doubao Large Model 1.6: "Tiered Thinking Length"
First domestic model with native tiered reasoning length adjustment:
- Minimal — Best for lookups, saves tokens.
- Low — Balanced quality & cost.
- Medium — Higher quality with moderate cost.
- High — Maximum depth for complex logic.
Analogy: Like adding a gearbox to AI — choose the gear for the task.
Low-tier example:
- Output tokens: ↓ 77.5%
- Thinking time: ↓ 84.6%
- Result quality: No change
---
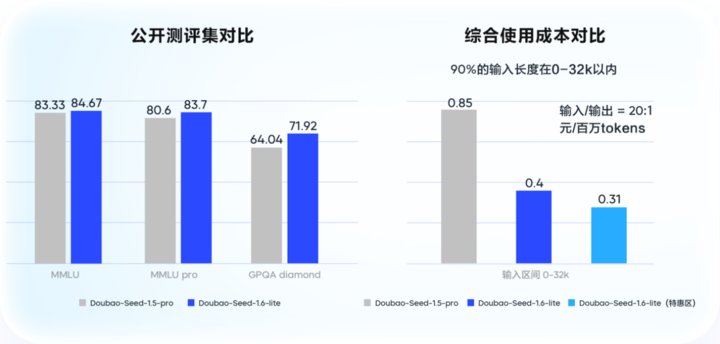
Doubao 1.6 Lite: Better Speed, Lower Cost
- 14% improvement vs. Doubao 1.5 Pro in enterprise testing.
- 53.3% lower cost (0–32k input range).
- Higher unit token value density = More value per cost unit.
---
Upgrades in Speech Models
Doubao Speech Synthesis Model 2.0 & Voice Cloning Model 2.0:
- Enhanced emotional expression & instruction compliance.
- Accurate complex formula reading — Essential for education.
- Market average: < 50% accuracy.
- Doubao new models: Up to 90% accuracy in math/science formula reading (primary–high school level).

---
Under the Hood
Built on Doubao LLM architecture for:
- Semantic understanding before speaking text.
- Precise emotional control via natural language commands:
- “Make it gentler.”
- “Read it with energy.”
---
Real-World Application Example
Children’s Picture Book — Protecting the Baer’s Pochard in Wuhan
Tools used:
- Beanbag Image Creation Model Seedream4.0 — Illustrations.
- Beanbag Speech Synthesis Model 2.0 — Emotional narration.
Beanbag Voice Models now span seven domains:
Speech synthesis, recognition, voice cloning, real-time speech, simultaneous interpretation, music creation, and podcast production — integrated into 460M+ intelligent devices.

---
Three Global AI Large Model Trends
Tan Dai identified:
- Deep-thinking models integrating multi-modal understanding.
- Video, image, and voice models approaching production grade.
- Enterprise-level Agents maturing.
---
Choosing the Right Model: Smart Model Router
Volcano Engine launched China’s first intelligent model selection system:
Available on Volcano Ark, with three routing modes:
- Balanced Mode
- Quality Priority Mode
- Cost Priority Mode

---
Why It Matters
Tasks differ in value density per token:
- Simple customer service → lightweight model.
- Complex medical analysis → top-tier model.
Smart routing lets AI decide token burn per task, supporting:
- Beanbag LLM
- DeepSeek
- Qwen
- Kimi
---
DeepSeek Routing Results
- Quality Priority: +14% performance vs. direct DeepSeek-V3.1.
- Cost Priority: Similar quality vs. DeepSeek-V3.1, cost ↓ 70%+.
---
The Positive Feedback Loop
How smart routing fuels the AI industry:
> Better models → more applications → higher token usage → smarter routing → lower unit cost → demand grows → cycle continues.
Tokens are becoming the kilowatt-hour of the AI era — measurable, billable, trackable.
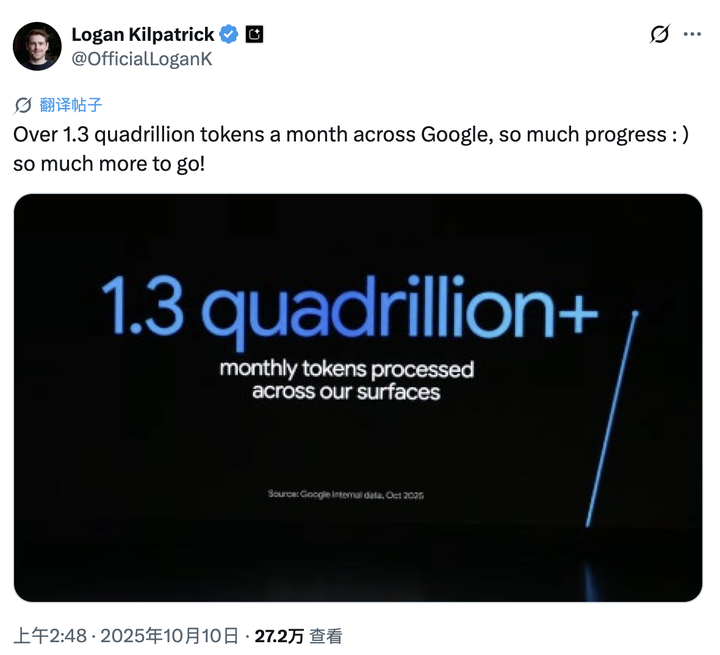
- OpenAI joined the “Trillion Token Club.”
- Google burns 1.3 trillion tokens monthly.
---
From Good Models to Good Experiences
The end goal:
- Simple queries: Fast, accurate.
- Complex problems: Deep, efficient reasoning.
- Automatic model choice with Smart Model Router.
- Natural language voice control without technical overhead.
---
Content Creation Meets AI Efficiency
Platforms like AiToEarn官网 connect:
- AI model selection
- Content generation
- Cross-platform publishing
- Analytics and model rankings (AI模型排名)
Supported platforms:
- Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
Goal: Monetize AI creativity globally — efficiently.
---
Final Takeaway
The future of AI is about powerful models, intelligent routing, and integrated ecosystems that turn ideas into experiences everywhere.
Doing more with less — and doing it smarter.
---
Would you like me to also create an infographic-style summary table of these AI products and their improvements so this Markdown becomes more visually concise? That could make the differences between each Doubao model instantly clear.


