# $100 Cost, 8,000 Lines of Code to Handcraft a ChatGPT Clone
## Introduction
**Andrej Karpathy**, former Tesla AI Director, OpenAI founding member, and respected AI educator, has released a new course project: **nanochat**.
Karpathy describes it as one of his most “chaotic” and free-spirited creations — a **minimalist, from-scratch, full-stack training/inference pipeline** for building a ChatGPT-like model.
Simply spin up a cloud GPU server, run one script, and **within 4 hours** you can chat with your own trained LLM through a ChatGPT-style web UI.
---
## Core Capabilities
This ~8,000-line project supports:
- **Tokenizer training** in Rust, implemented from scratch.
- **Pretraining** a Transformer architecture LLM on the FineWeb dataset, evaluating CORE metrics.
- **Midtraining** with SmolTalk dialogue data, multiple-choice datasets, and tool-use datasets.
- **Supervised fine-tuning (SFT)** with ARC-E/C, GSM8K, HumanEval.
- Optional **Reinforcement Learning (RL)** with the GRPO algorithm on GSM8K.
- **Inference engine** supports KV caching, prefill/decoding, and tool use (Python interpreter), accessible via CLI or web UI.
- Automatic single **Markdown report card** documenting training, metrics, and progress.
💡 **Cost**: Around **$100** (4 hours training on 8×H100 GPUs).
---
## Performance Highlights
- **After 12 hours** of training, nanochat surpasses GPT‑2 on CORE benchmarks.
- **$1,000 budget (~41.6 hours)** gives enhanced performance: solves math/code problems and multiple-choice reasoning.
- Example: Depth‑30 model trained for 24 hours (~GPT‑3 Small 125M compute cost) scores:
- **MMLU:** 40+
- **ARC-Easy:** 70+
- **GSM8K:** 20+
---
## Project Vision
Karpathy’s aim: **Consolidate** a readable, modifiable, minimal tech stack for LLMs into one repo.
> "It may grow into a research toolkit or benchmarking tool — much like nanoGPT before it."
**nanochat** acts as the capstone project for the upcoming **LLM101n course**.
---
## Popularity
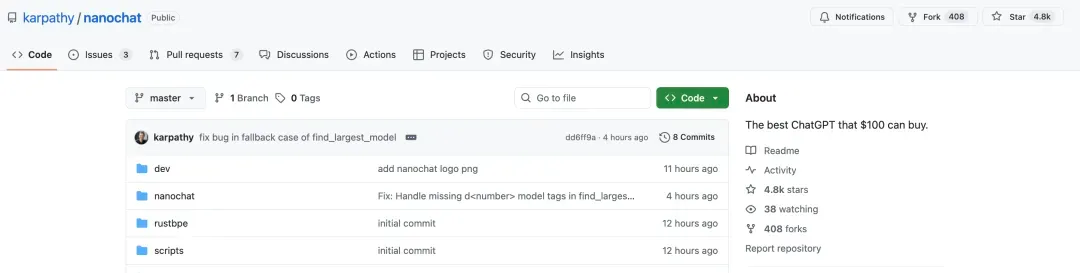
- Immediate community excitement — GitHub repo reached **4.8K stars** quickly.
---
## Architecture Overview
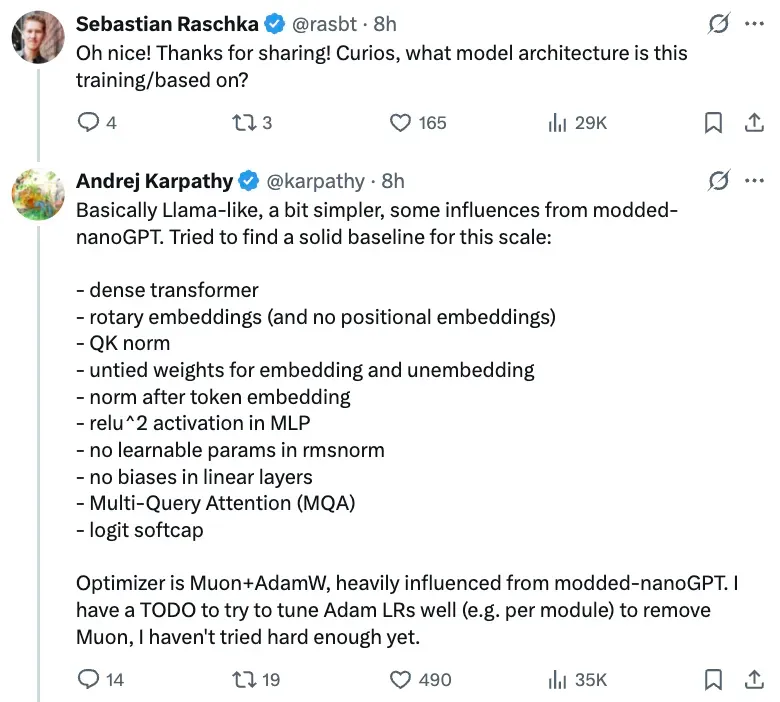
Karpathy notes:
- Architecture: Similar to **LLaMA**, simplified.
- Inspiration: Some features from **modded nanoGPT**.
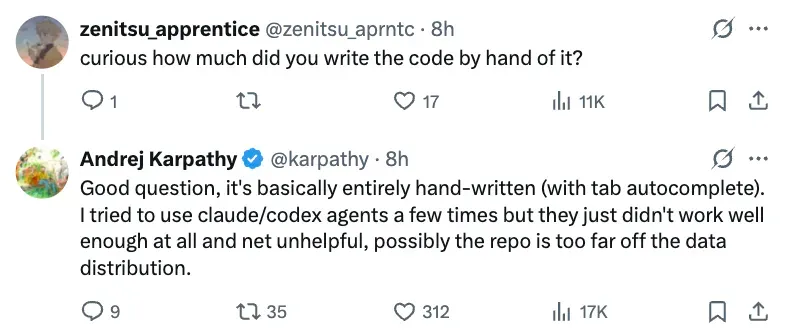
- Handwritten code — attempted AI agent assistance (Claude, Codex) yielded poor results.
---
# Quick-Start Guide
Launching an **8×H100 GPU server** on Lambda GPU Cloud ≈ $24/hour — efficiency matters.
---
## Step 1: Clone the Project

---
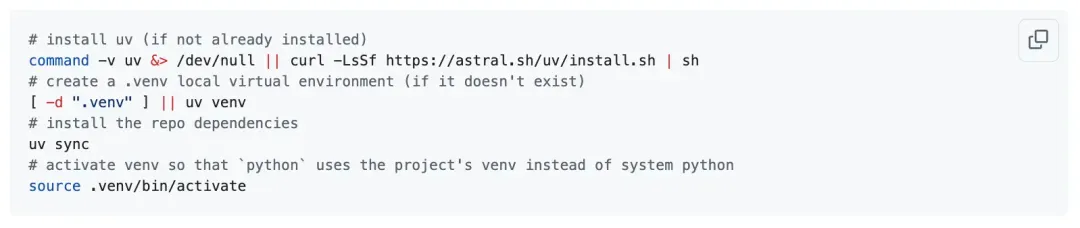
## Step 2: Install Dependencies
1. Install **uv** project manager.
2. Create and activate a `.venv` virtual environment.
3. Ensure `python` maps to the venv environment.
---
## Step 3: Install Rust/Cargo
Required to **compile the custom Rust tokenizer**.
Karpathy found:
- Python `minbpe` tokenizer too slow.
- HF tokenizer too bloated/confusing.
This Rust tokenizer is optimized for training with accurate output matching the Python version, using OpenAI's `tiktoken` for inference.

---
## Step 4: Download Pretraining Data
Dataset: **FineWeb‑EDU** (Karpathy version: shuffled shards).
- **Size:** 0.25M chars/shard (~100MB gzip).
- **Total shards:** 1,822.
- **For depth‑20:** Requires 240 shards (~24GB total).

---
## Step 5: Train the Tokenizer
- **Vocab size:** 65,536 (2¹⁶ tokens).
- **Training time:** ~1 minute.
- Algorithm: Regex splitting, byte-level BPE — same as OpenAI.
- Evaluate compression ratio (~4.8).
---
## Step 6: Download Eval Bundle
- Location: `~/.cache/nanochat/eval_bundle`
- Contains 22 datasets for CORE evaluation (ARC, HellaSwag, lambada, etc.).

---
## Step 7: Configure WandB *(Optional)*

---
## Step 8: Pretraining
- Script: `scripts/base_train.py`
- Setup:
- Depth‑20 Transformer
- 1,280 channels, 10 attention heads × 128 dims
- ~560M parameters
- Following Chinchilla scaling laws (~11.2B tokens)

💡 **Pretraining time**: ~3 hours.
---
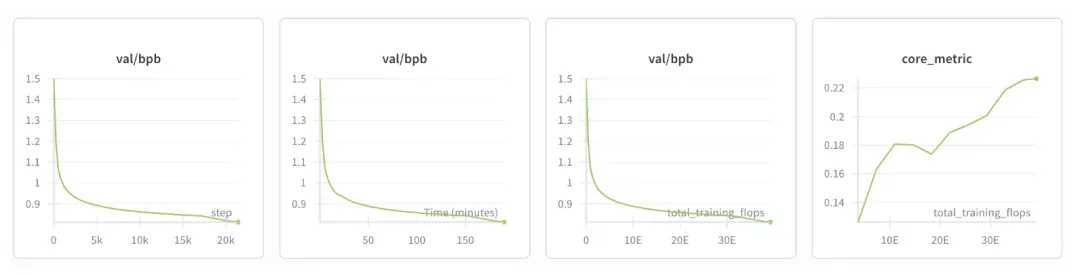
## Training Metrics
- **Bits per byte (bpb):** Tokenizer-independent loss measure.
- Example result: bpb ≈ 0.81, CORE ≈ 0.22 (outperforms GPT‑2 Large).

---
## Step 9: Mid-Phase Training
Purpose:
- Adapt to multi-turn conversation tokens.
- Learn multiple-choice formatting.
- Learn tool usage (e.g., Python execution between `<|python_start|>` and `<|python_end|>`).

---
### Midtraining Process

Run:

**Duration:** ~8 minutes.
**Results:**

---
## Step 10: Supervised Fine-Tuning (SFT)
- Fine-tune on high-quality dialogue.
- Align training & inference formats.

**Duration:** ~7 minutes.
Slight performance boosts:

---
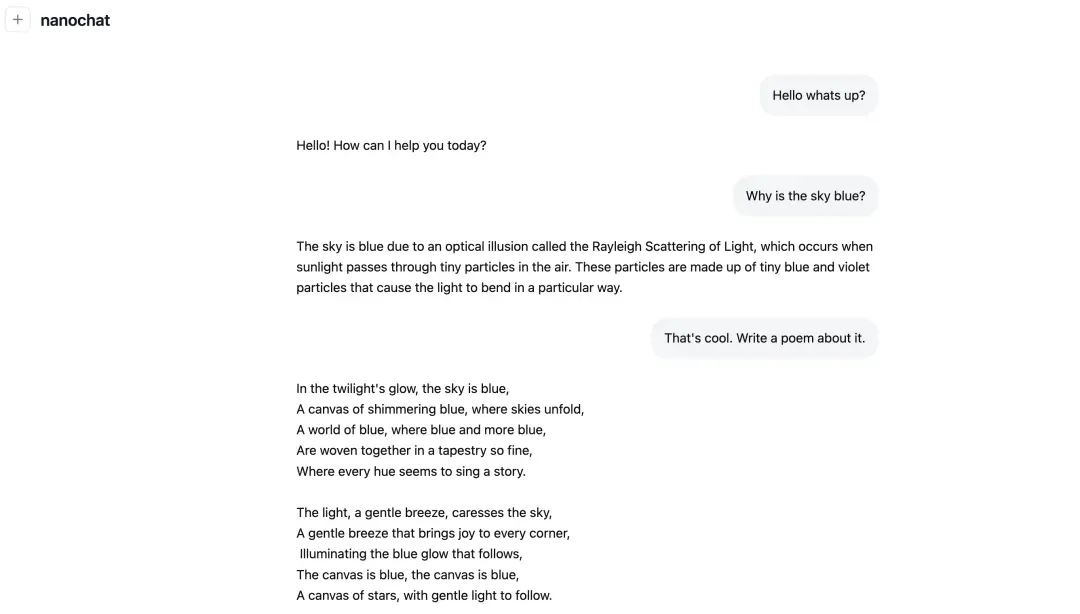
## Step 11: Chat Interaction
Two methods:
1. CLI
2. Web UI (`chat_web` via FastAPI)

---
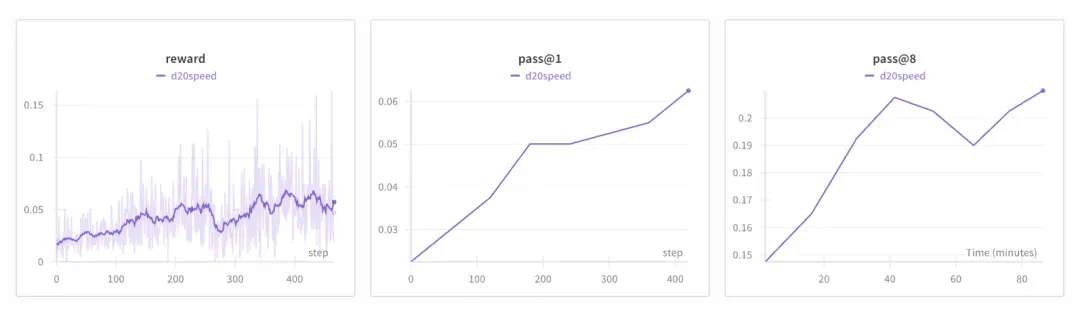
## Step 12: Reinforcement Learning (Optional)
- Dataset: GSM8K
- Simplified GRPO loop: Rewards correct answers.
- Results after 1.5 hours:
---
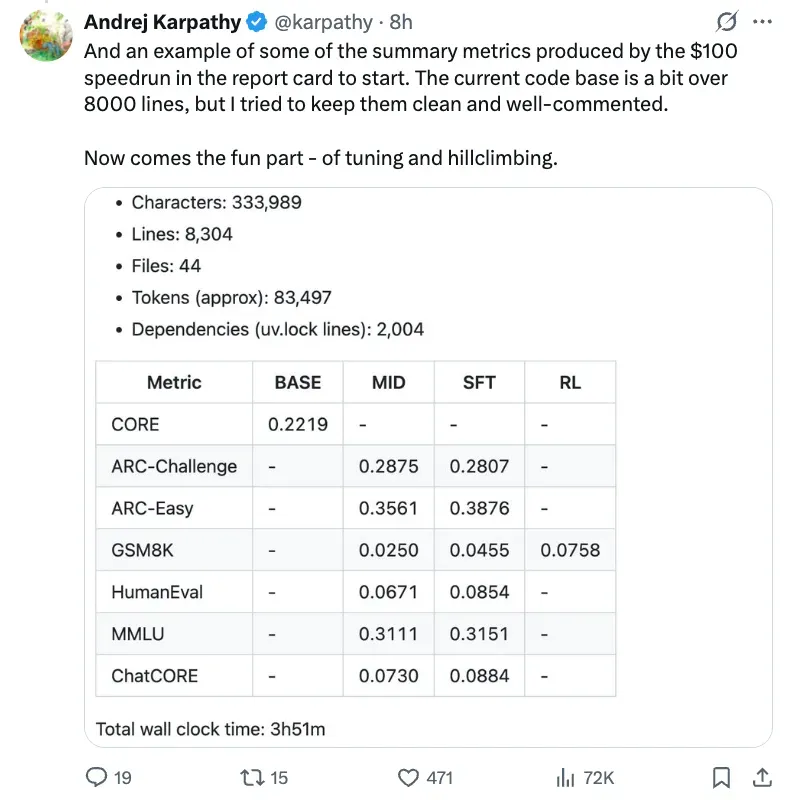
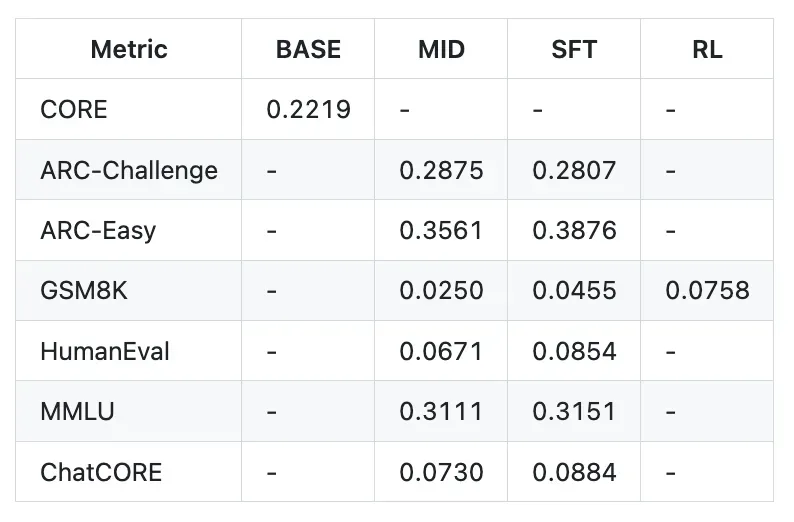
## Final Report
- **Characters:** 333,989
- **Lines:** 8,304
- **Files:** 44
- **Tokens:** ~83,497
- **Dependencies:** 2,004 lines in uv.lock
- **Runtime (SFT stage):** 3h 51m → **~$92.4 cost**
---
# Model Scaling Tips
- Use `--depth` parameter in `base_train.py`.
- Larger depth → adjust batch size (e.g., 32 → 16).
- The repo auto-adjusts with gradient accumulation.


---
## About Karpathy

- Former Tesla AI Director → OpenAI → Founded **Eureka Labs** in 2023.
- Courses: **CS231n** at Stanford, influential blog posts, YouTube tutorials.
- Vision: **AI-native education** combining human teachers + patient, multilingual AI guides.
---
### Eureka Labs' First Course: **LLM101n**
> Build a story-generating LLM similar to ChatGPT with companion web app.
---
**Resources**
GitHub repo: https://github.com/karpathy/nanochat
Discussion guide: https://github.com/karpathy/nanochat/discussions/1
Karpathy tweet: https://x.com/karpathy/status/1977755427569111362
---