Kimi Open-Sources New Linear Attention Architecture, Surpasses Full Attention Models for the First Time with 6× Faster Inference

The Transformer Era Is Being Rewritten
Moonshot AI has unveiled its open-source Kimi Linear architecture — introducing a novel attention mechanism that, for the first time, outperforms traditional full attention under identical training conditions.

In long-context tasks, Kimi Linear:
- Reduces KV cache usage by 75%
- Achieves up to 6× faster inference speed
Some netizens are already asking: With this architecture, when will Kimi K2.5 arrive?

Before speculating, let’s explore how Kimi Linear challenges the traditional Transformer.
---
Why Transformer Attention Is Powerful — and Costly
Transformers are highly capable, but computationally expensive.
- Fully connected attention means each token interacts with every other token.
- Complexity grows quadratically with sequence length — O(N²).
- Generating each new token requires checking all previous caches.
Impact:
Large context windows (128K+) consume massive GPU memory for KV caches — often triggering warnings or crashes. The larger the model, the more severe the strain and cost.

---
Searching for Linear Attention
Teams worldwide have explored linear attention, aiming to:
- Reduce complexity O(N² → O(N)
- Improve speed and lower resource usage
Challenge:
Linear attention historically forgets context quickly — fast, but memory retention is weak.
Solution:
Kimi Linear proposes a balance of speed and memory retention.
---
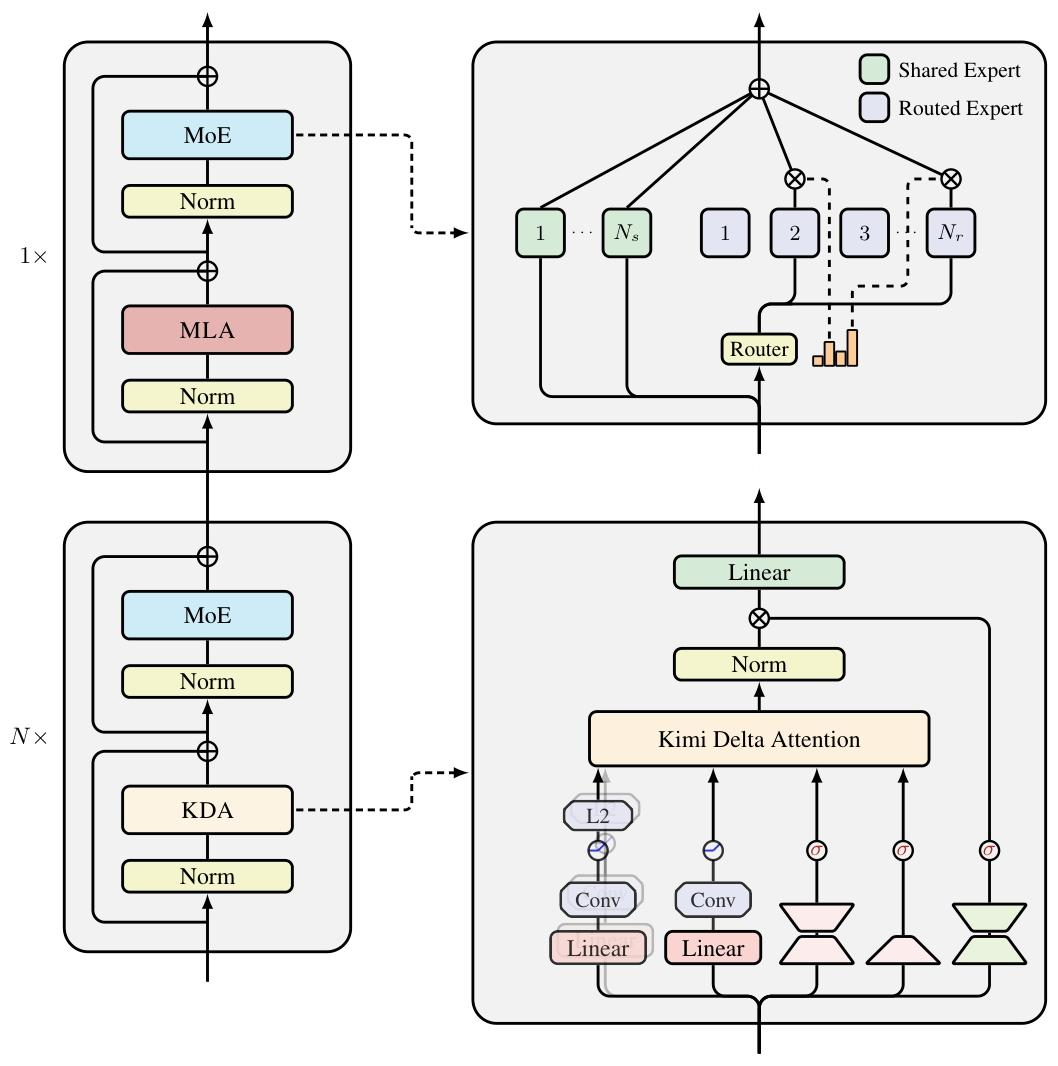
Core Innovation: Kimi Delta Attention (KDA)
Key Features
- Fine-grained forgetting gates
- Unlike uniform forgetting in traditional linear attention, KDA controls memory retention independently for each channel dimension, retaining critical information while discarding redundancy.
- Improved Delta Rule for stability
- Prevents gradient explosion or vanishing — even with million-token contexts.
- 3:1 Hybrid Layer Design
- 3 layers of KDA linear attention
- 1 layer of full attention
- Preserves global semantic understanding while keeping most computations linear.
- No RoPE (Rotary Position Encoding)
- Instead uses a time-decay kernel function for position.
- This yields better stability and generalization.

---
Efficient Computation — DPLR Structure
How It Works
- Diagonal-Plus-Low-Rank (DPLR) optimization during KDA state updates
- Splits the attention matrix into:
- Diagonal block
- Low-rank patch
- Enables parallel GPU computation for larger chunks — doubling throughput
Additional Engineering Optimizations
- Block-parallel computation
- Kernel fusion to cut GPU memory I/O overhead
- Fully compatible with the vLLM inference framework — drop-in replacement for any Transformer-based system
---
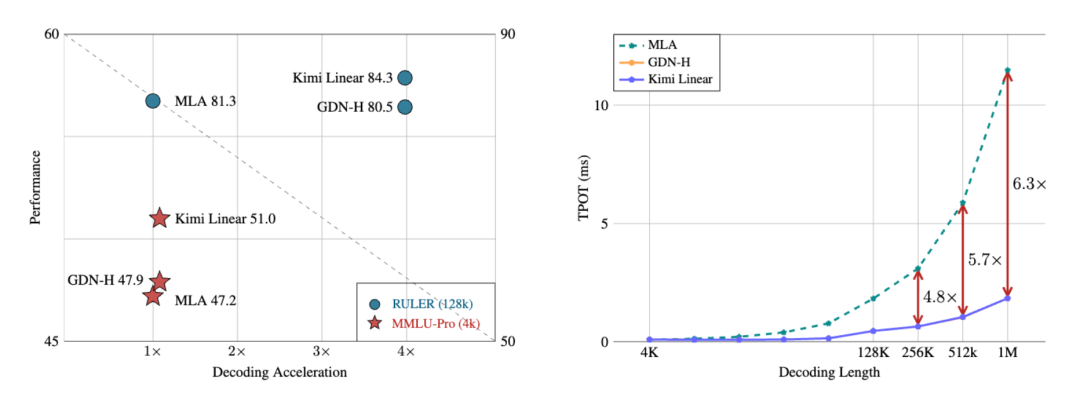
Experimental Results
Training scale: 1.4T tokens — identical to baseline Transformers.
Performance Gains:
- Surpasses full-attention Transformers on MMLU, BBH, RULER, GPQA-Diamond
- Decoding speed: up to 6× faster
- KV cache: 75% less usage
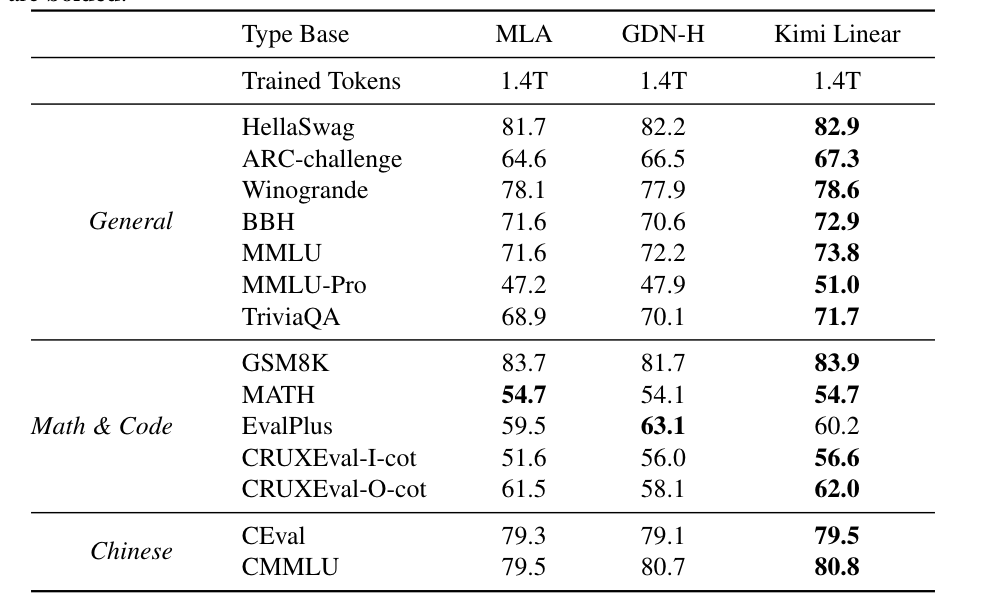
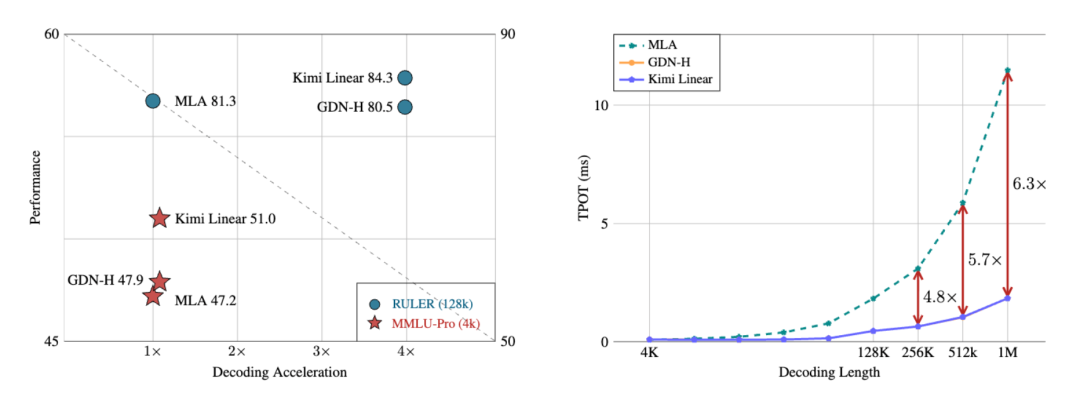
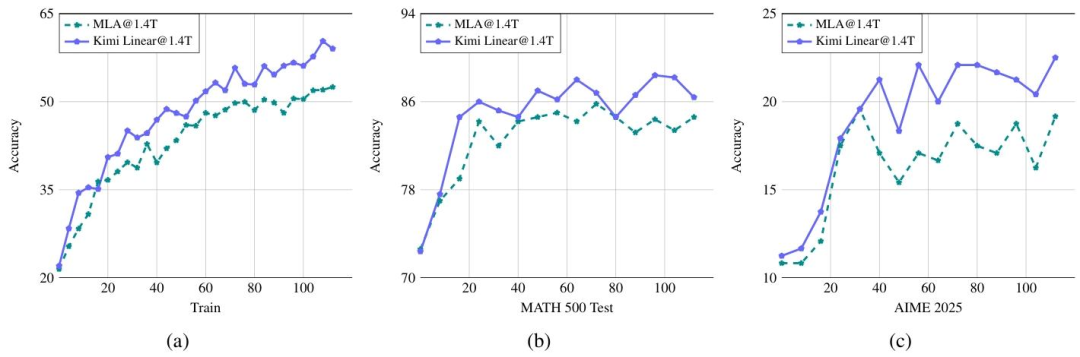
Accuracy preserved, with improved math reasoning and code generation stability.
---
Broader Impact
Architectures like Kimi Linear could redefine efficiency in long-context AI.
For creators and developers, platforms like AiToEarn官网 complement these advances:
- Cross-platform AI content publishing
- Integration with Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X
- Built-in AI tools, analytics, and model rankings (AI模型排名)
---
The Shift Away from Transformer Dependency
Recent research suggests Transformers may not be the only path forward:
- State Space Models (SSM) — as seen in Mamba — offer long-sequence efficiency.
- Google MoR — recursive structures replacing partial attention to lower computational depth.
- Apple — adopting Mamba for edge devices due to energy efficiency and low latency.
Kimi Linear approaches from a linear attention angle, reducing memory load while preserving accuracy.
Yet, the open-source leader MiniMax M2 still uses full attention — showing diversity in design preferences.
Technical report: huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
---
Conclusion
The dominance of traditional Transformers is now being questioned.
From SSM-based models to hybrid attention architectures, the AI community is stepping into a period of diversified innovation.
For innovators sharing these breakthroughs globally, platforms like AiToEarn官网 provide the infrastructure to publish, measure, and monetize across major global and Chinese platforms, helping bridge cutting-edge AI research with real-world adoption.
---
Would you like me to add a side-by-side table comparing Kimi Linear vs. Full Attention Transformers for quick reference? That could make this Markdown even more reader-friendly.