# Using AI to Observe the Stars
*2025-10-13 12:18 Beijing*
---
## Introduction

Artificial intelligence is advancing at a breathtaking pace. As one netizen humorously noted this morning:
> “We have gone 0 days without a groundbreaking new development in AI to grab attention.”

Three months ago, [OpenAI announced its reasoning model had won a gold medal at the International Mathematical Olympiad (IMO)](https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650980674&idx=1&sn=d36f17d0bfc60753d74cf6c09494ce4a&scene=21#wechat_redirect).
Now, it appears that **large language models (LLMs)** not only excel in mathematical reasoning but also in many other domains of scientific research.
---
## Breakthrough in Astronomy & Astrophysics
Recent developments show that top-tier large models are achieving **remarkable results in international science competitions**.
A newly published paper benchmarked LLMs using the **International Olympiad on Astronomy & Astrophysics (IOAA)** and found that **GPT-5** and **Gemini 2.5 Pro** can achieve **gold medal–level performance** in astronomy and astrophysics.

Greg Brockman, president and co-founder of OpenAI, was so excited he even mistyped GPT’s name when sharing this work:

This milestone hints that, one day, when humanity reaches for the stars, **AI large models will be part of the journey**.

---
**Paper Title:** *Large Language Models Achieve Gold Medal Performance at the International Olympiad on Astronomy & Astrophysics (IOAA)*
**Paper Link:** [https://arxiv.org/abs/2510.05016](https://arxiv.org/abs/2510.05016)
---
## Why IOAA Was Chosen
The IOAA was selected as a benchmark for three main reasons:
1. **High ecological validity:**
IOAA problems require complex reasoning, creative problem-solving, and multi-step derivations — skills essential for real astronomical research.
2. **Comprehensive topic coverage:**
The syllabus spans cosmology, spherical trigonometry, stellar astrophysics, celestial mechanics, photometry, and observational instrumentation.
3. **Integration of theory, data, and physics:**
IOAA combines theoretical physics, observational constraints, and real astronomical data with mathematical derivations — a richer evaluation format than IMO, IPhO, or IOI.
Traditional astronomy benchmarks like **AstroBench** and **Astro-QA** rely mainly on multiple-choice and short-answer formats, which cannot fully assess complex reasoning skills. This study addresses that gap.
---
## Evaluation Focus
The evaluation focused on two IOAA components:
- **49 Theoretical Questions**
- Category 1: Geometry / Space (celestial sphere geometry, spherical trigonometry)
- Category 2: Physics / Mathematics (astrophysical calculations without geometric visualization)
- **8 Data Analysis Questions**
> **Note:** The observational section was excluded due to the digital nature of LLMs.
---
## Results: Gold Medal Performance
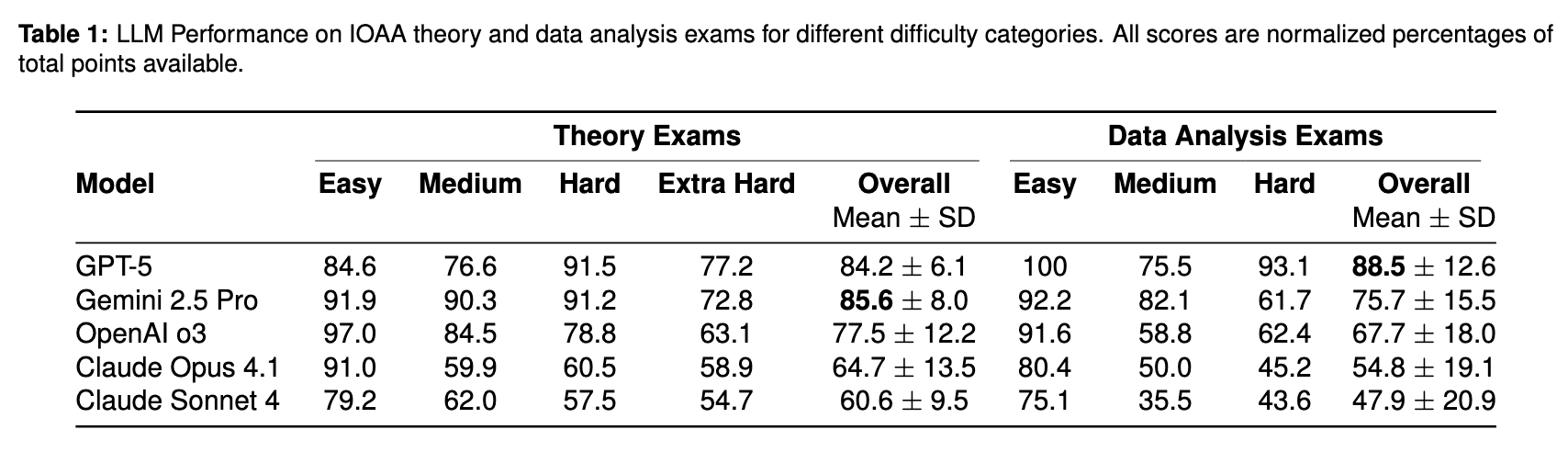
**Key findings:**
- **GPT-5** and **Gemini 2.5 Pro** achieved the highest scores, surpassing other models by 7–25 percentage points.
- GPT-5 topped 2022 (93.0%), 2023 (89.6%), and 2025 (86.8%); Gemini 2.5 Pro led in 2024 (83.0%).
- GPT-5 scored better on harder problems, with fluctuations due to small question counts per difficulty, spatial reasoning gaps, and occasional astrophysics conceptual errors.
---
## Theoretical Exam Insights
Main observations:
1. **Small datasets can skew percentages** — few errors have large impact.
2. **Spatial/geometric reasoning** remains a challenge.
3. **Occasional astrophysics concept errors** in easy questions.
Other strong performers:
- **OpenAI o3**: 77.5% overall
- **Claude Opus 4.1**: 64.7%
- **Claude Sonnet 4**: 60.6%
Performance declines with difficulty, revealing gaps in complex problem-solving despite good multiple-choice scores in other benchmarks.
---
## Data Analysis Exam Insights
GPT-5 scored **88.5%** — higher than its theoretical score — outperforming other models whose data analysis scores were **10–15% lower** than their theoretical scores.
Strengths:
- Superior multimodal understanding
- Accurate image parsing and plotting reasoning
Implication: Future benchmarks should include **ecologically valid multimodal data analysis tasks** to mimic real research workflows.
---
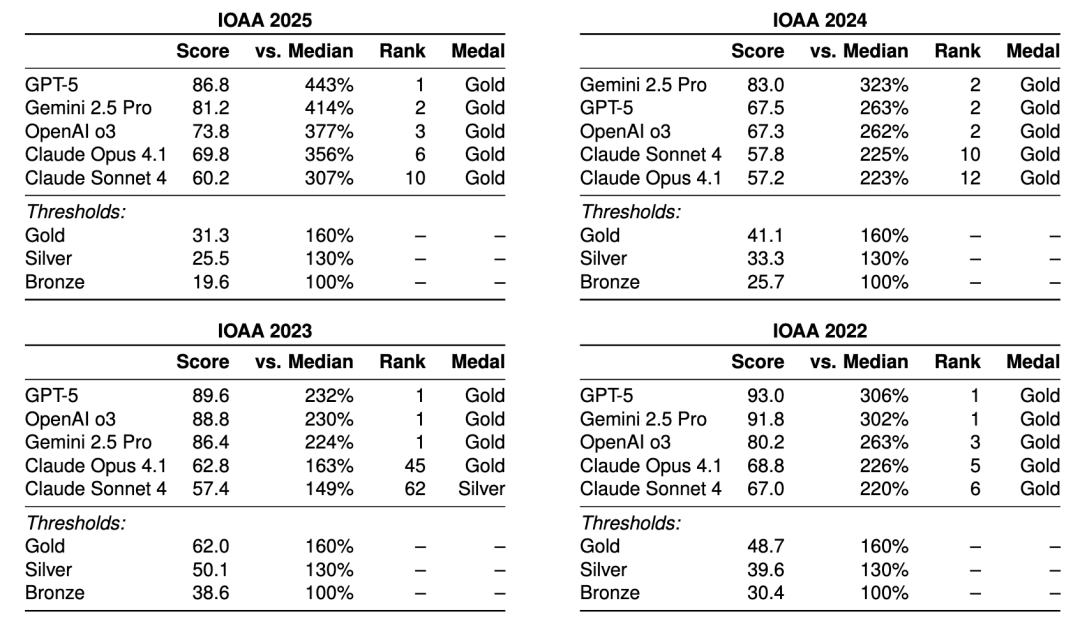
## Comparison with Human Scores
Medal criteria (based on ratios to median scores):
- **Bronze:** 100–130%
- **Silver:** 130–160%
- **Gold:** >160%
Most LLMs reached gold level; only **Claude Sonnet 4** scored silver once (2023).
GPT-5 (2022, 2023, 2025) and Gemini 2.5 Pro (2022, 2023) matched or exceeded top human contestant scores.
---
## Performance Snapshots
### Theoretical Exam (2022–2025)
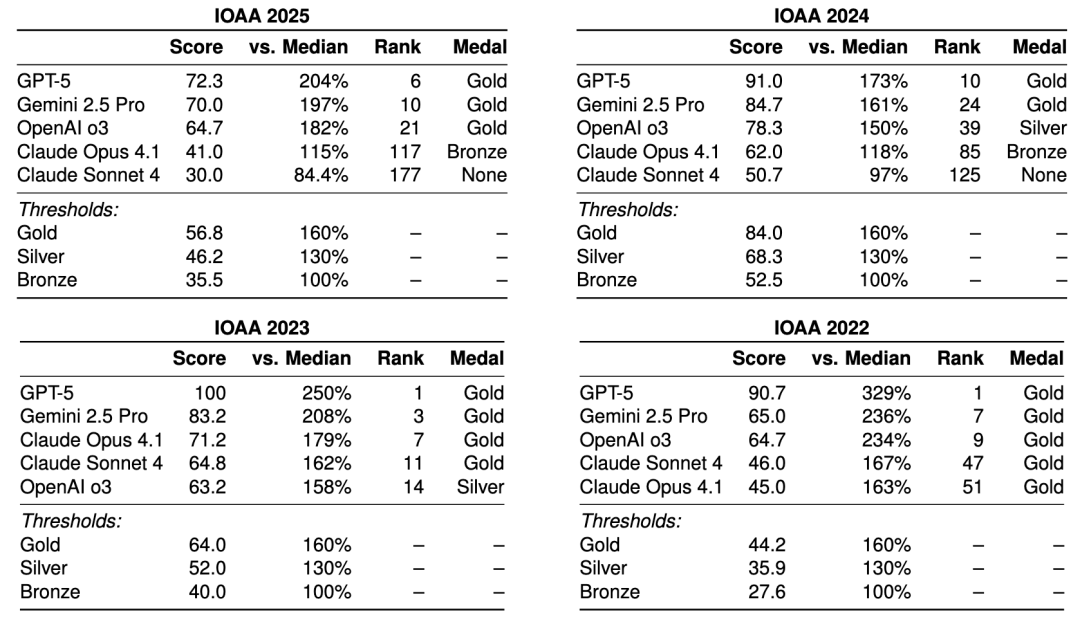
### Data Analysis Exam (2022–2025)
---
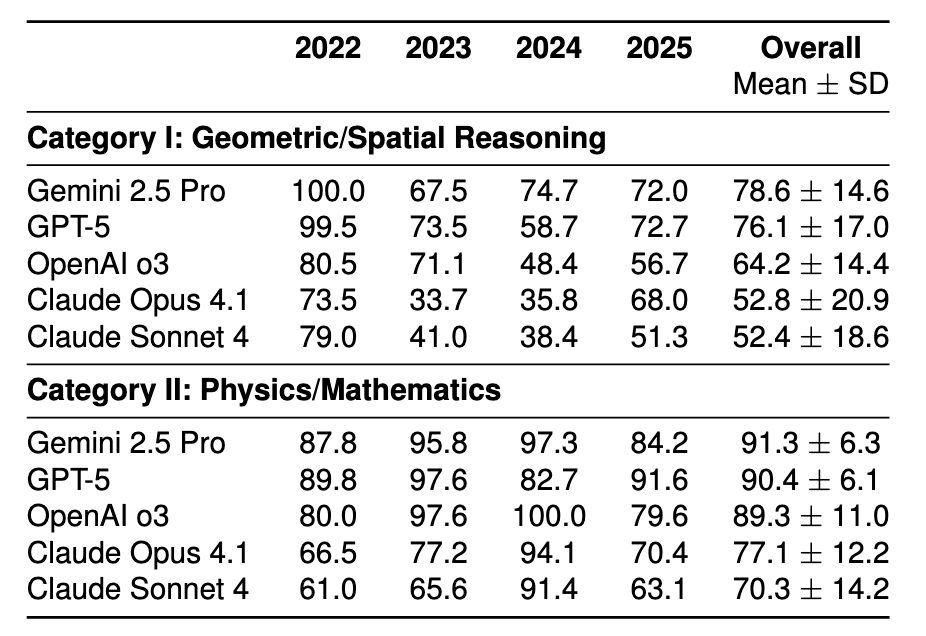
## Performance by Question Category
Category I: Geometry / Spatial
Category II: Physics / Mathematics
LLMs scored **15–26% higher** in Category II than Category I.
---
## Error Analysis
### Common Error Types
- **Conceptual mistakes:** wrong approaches, formula misuse, reasoning flaws.
- **Geometry/spatial reasoning gaps:** spherical trigonometry, timekeeping systems, 3D visualization challenges.
- **Data exam errors:** graphing, chart/image reading — notably in OpenAI o3 and Claude series.
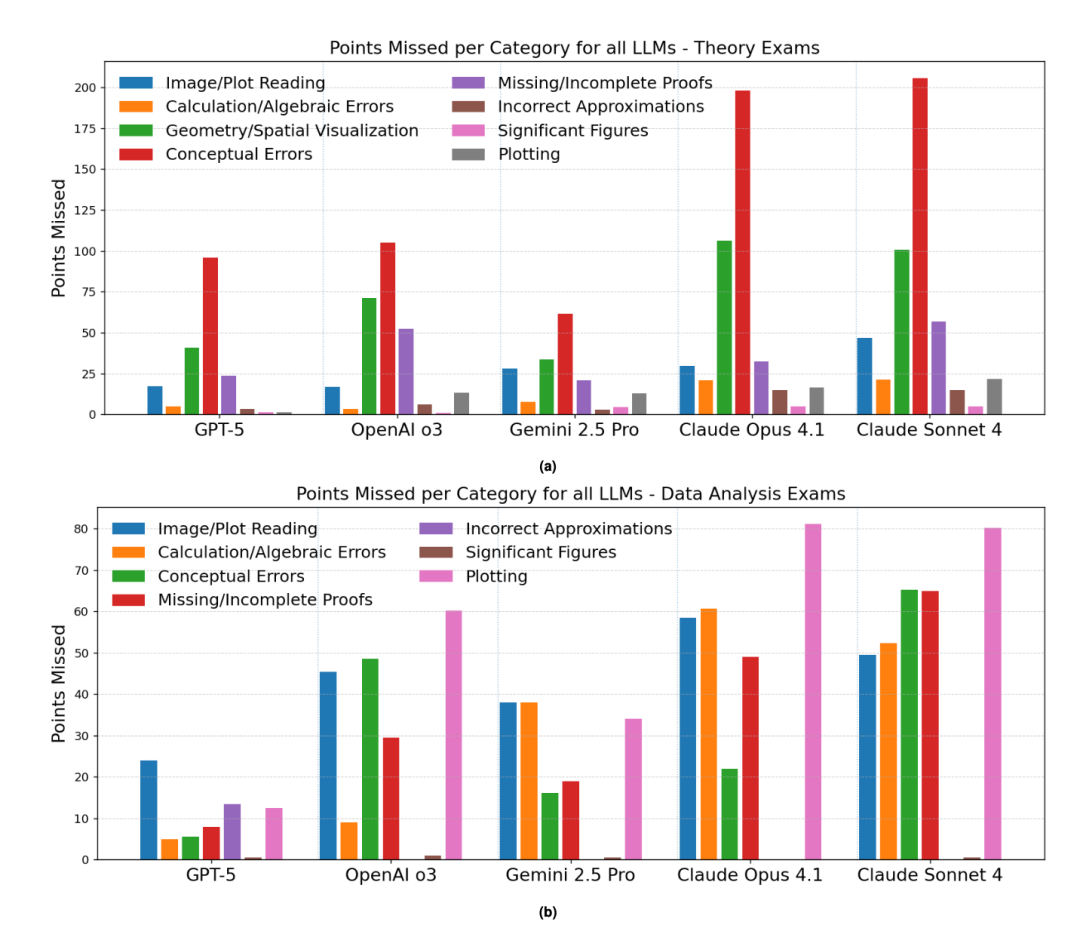
### Score Loss Distribution
- (a) IOAA Theoretical Exam 2022–2025
- (b) IOAA Data Analysis Exam 2022–2025

---
## Tools for Sharing AI Research Results
Platforms like [AiToEarn官网](https://aitoearn.ai/) help researchers and creators:
- Generate AI-driven content
- Publish simultaneously across major platforms (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Track engagement and model rankings ([AI模型排名](https://rank.aitoearn.ai))
For astrophysics educators and competition trainers, this can facilitate **global sharing** of problem analyses, tutorials, and datasets.
---
[Read original article](2650995074)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=bbf9314a&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzA3MzI4MjgzMw%3D%3D%26mid%3D2650995074%26idx%3D2%26sn%3D657ceac36a5f75b2303ceb29d4ce4f20)




