Latest Breakthrough in World Models and Embodied AI: 90% Synthetic Data, VLA Performance Soars 300% | Open Source

🚀 VLA Model Performance Soars by 300%
90% of Training Data Now Generated by a World Model — for the First Time
A domestic world model developer has achieved a breakthrough in embodied intelligence — and has open-sourced all model code and training frameworks.

---
The Data Bottleneck in Embodied Intelligence
The biggest challenge for deploying embodied intelligence in open-world environments has not been algorithms, but the extreme scarcity of high-quality, large-scale, real robot interaction data.
Key issues with real-machine data collection:
- High cost and significant time investment
- Difficulty covering diverse open-world scenarios
- Severe limits on scalability and generalization
While simulation can quickly produce data, it introduces a Sim-to-Real gap, making real-world deployment less robust.
---
Why World Models Matter
World models learn the rules and patterns of the physical world, enabling them to generate high-fidelity, controllable, and diverse embodied interaction data.
This helps overcome the shortage of real-machine data.
Breakthrough:
Chinese world model company GigaVerse, backed by Huawei, has released GigaWorld-0, increasing the proportion of world model–generated data in VLA training to 90%.
---
Performance Gains
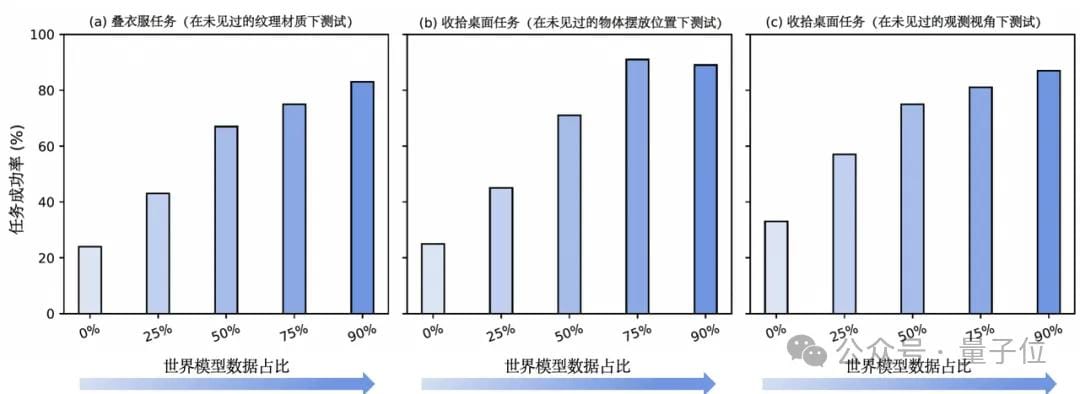
The trained VLA model showed ~300% improvement across three generalization dimensions:
- New Textures — unseen surface materials during training
- New Viewpoints — unseen observation angles during training
- New Object Positions — unseen spatial layouts during training
This marks a new stage: data-efficient, highly generalizable, and low-cost embodied intelligence.
---
GigaWorld-0 Architecture
GigaWorld-0 comprises two coordinated components:
- GigaWorld-0-Video — generates richly textured, visually realistic embodied operation data using video generation foundation models.
- GigaWorld-0-3D — combines 3D generation, 3D Gaussian Splatting reconstruction, and differentiable physics for accurate geometry and dynamics.

GigaWorld-0-Video Improvements
Addresses low computational efficiency and poor fine-detail control by boosting:
- Sparse Attention modeling capacity — memory- and latency-efficient long-range spatio-temporal attention.
- Dynamic Expert Computation capability — increases diversity and controllability.

Sparse Attention:
Uses a Diffusion Transformer (DiT) with sparse attention — local spatio-temporal neighborhoods and key semantic regions only — reducing complexity and cost.
Mixture-of-Experts (MoE):
Integrates MoE within DiT feedforward layers, routing video tokens to specialized experts for fine-grained control inspired by DeepSeek V3.
---
GigaWorld-0-3D: Generative + Reconstruction
Enhances scene modeling under sparse observations with differentiable physics simulation for robotic manipulation.
Capabilities:
- Geometrically consistent & visually realistic static backgrounds
- Accurate modeling of robot–object dynamics
Generative Reconstruction
- Initialize Gaussian scene representation from sparse views
- Apply view-repair generation to fix distortions
- Reconstruct high-precision 3DGS for novel view synthesis fidelity

---
Differentiable Physics Engine
Based on Physics-Informed Neural Networks (PINNs):
- Generate trajectories with random physical parameters
- Train differentiable surrogate models for system dynamics
- Optimize parameters via gradient descent to match real motion
Produces physically plausible and interaction-reliable data.

---
FP8 Precision + GigaTrain Framework
Industry first: world model trained end-to-end in FP8 precision — optimized for energy efficiency.
- Combines FP8 + Sparse Attention to balance visual fidelity & compute cost
- Powered by GigaTrain: open-source distributed training framework supporting:
- DeepSpeed ZeRO
- FSDP2
- FP8 mixed precision
- Gradient checkpointing
Repo: GitHub
---
Benchmark Results
PBench (Robot Set) comparison:
Models tested: Cosmos-Predict2-14B, Cosmos-Predict2.5-2B, Wan2.2-5B, Wan2.2-14B
- GigaWorld-0 — smallest model at 2B parameters
- Achieved highest overall score and outperformed in key metrics

---
Real-World Impact
GigaWorld-0 is a generalized embodied data engine:
- Validated on GigaBrain-0 VLA model across:
- New texture generalization
- New viewpoint generalization
- New object position generalization
Increasing synthetic data proportion steadily improved task success rates and motion accuracy on real robots.
---
Links
- Project: https://giga-world-0.github.io/
- Paper: https://arxiv.org/pdf/2511.19861
- Code: https://github.com/open-gigaai/giga-world-0
---
Jija Vision: Leading in World Models & Embodied Brains
Founded in 2023 as China’s first physics AI company, focusing on World Model Platforms × Embodied Foundation Models.
Leadership Team
- Huang Guan, CEO — PhD in AI, Tsinghua University; ex-Horizon Robotics; experience at Samsung China Research & Microsoft Research Asia.
- Zhu Zheng, Chief Scientist — PhD, Chinese Academy of Sciences; postdoc at Tsinghua University; >17,000 citations, h-index 50.
- Top researchers from Tsinghua, Peking Univ, CAS, USTC, WashU, CMU, and leaders from Microsoft, Samsung, Baidu, Bosch, etc.
---
Industry Engagements
- World-class expertise in World Models and Embodied Brains
- Contracts with leading autonomous driving OEMs
- Applications spanning research, education, exhibitions, industry services, household robotics
- Nov. 2023: Completed 100M RMB A1 financing — Huawei Hubble & HC Capital
---
Related Tools: AiToEarn
AiToEarn官网 — open-source platform for AI content generation, publishing, and monetization across:
- Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
Integrates:
- AI content creation
- Cross-platform publishing
- Analytics & model ranking (AI模型排名)
Open-source repo: GitHub
---
If you like, I can also create an infographic-friendly condensed version of this Markdown so your readers can quickly grasp the structure and key achievements of GigaWorld‑0. Would you like me to do that?


