LeCun’s Prediction Comes True: 790-Year Long Video Trains the Strongest Open-Source “World Model”

The Third Scaling Paradigm in AI
Emu3.5 Ushers in a Native Multimodal World


New Intelligence Report
Editor: Peach Sleepy
---
Executive Summary
The third scaling paradigm in AI is here — Emu3.5.
With 34 billion parameters, trained on the equivalent of 790 years of long-form video, this native multimodal world model can generate coherent 3D worlds and delivers up to 20× faster image inference.
---
World Models — The New Battleground in AI (2025)
- Google: Genie 3 — Generates a live 720p simulated world from a single sentence, dubbed by netizens as “Game Engine 2.0.”
- World Labs (Fei-Fei Li): RTFM — Real-time 3D rendering using only one H100 GPU.
- Meta FAIR: Code World Model (CWM)
- Runway: General World Model (GWM)
- Tesla: Neural network simulator
Core focus across the industry: Multimodal world models

Why World Models?
Leading AI researchers (e.g., Fei-Fei Li, Yann LeCun) emphasize: language alone cannot replicate human intelligence — AI must understand and simulate the physical world.
World models mimic human “mental models,” predicting environmental behavior and dynamics.
---
Introducing Emu3.5 — A Milestone by BAAI
Official launch by Beijing Academy of Artificial Intelligence (BAAI)
President Dr. Zhongyuan Wang:
> “Not every large model has to follow paths already taken. Emu is our own technical route — one we lead.”
Key difference:
While mainstream models are “modular assemblies” (LLM + CLIP + DiT), Emu3.5 returns to first principles:
- Continuous, long-term visual learning
- Unified autoregressive architecture for both understanding and generation
Capabilities:
- Long-text rendering
- Complex image editing
- Visual storytelling with physical dynamics, causality, spacetime, and logic
Technical report: https://arxiv.org/pdf/2510.26583
Homepage: https://zh.emu.world
---
Core Research Questions Emu3.5 Addresses
- How should multimodality be unified?
- → Native, end-to-end autoregressive “Next-State Prediction”
- What should a world model learn?
- → Long video data rich in world knowledge, temporal consistency, and causality
- How to achieve scaling?
- → Third Scaling Paradigm: Pretraining + Multimodal RL, leveraging LLM infrastructure
- How to implement efficiently?
- → Reasoning acceleration via DiDA to overcome bottlenecks

---
Learning Like Humans — From Next-Token to Next-State
Human learning starts with perception, not text.
- Babies observe and interact with the world → understand physics → develop language
Problem in current models:
- Video/image generators use separated modules (Diffusion Transformer) → no true unified intelligence.
Emu3.5’s Native Multimodal Path
- Unified tokenization: Images, text, action instructions
- Single autoregressive Transformer predicts the next token (visual, textual, or instructive)
- Benefits:
- Unification: Shared context for understanding & generation
- Scalability: Reuse LLM’s proven infrastructure

---
Third Scaling Paradigm — 790 Years of Video + Multimodal RL
Data scale: > 13 trillion multimodal tokens
- Core: 790 years of long videos (documentaries, education, vlogs, gaming, animation)
- Rich spatiotemporal, causal, and coherent context
Training stages:
- Large-scale pretraining (~10 trillion tokens) → Basic multimodal alignment
- Large-scale multimodal RL → Decision-making & contextual reasoning across modalities
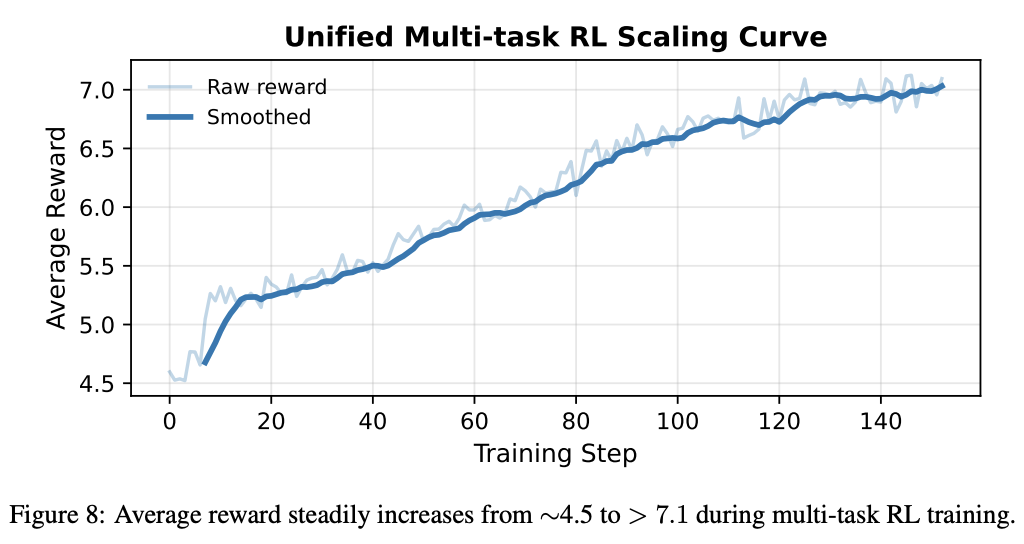
RL innovation:
- Unified autoregressive architecture supports multi-task multimodal RL
- Reward types: General (aesthetics, image–text consistency) + Task-specific (OCR accuracy, face ID preservation)
- Optimization via GRPO in a unified reward space

---
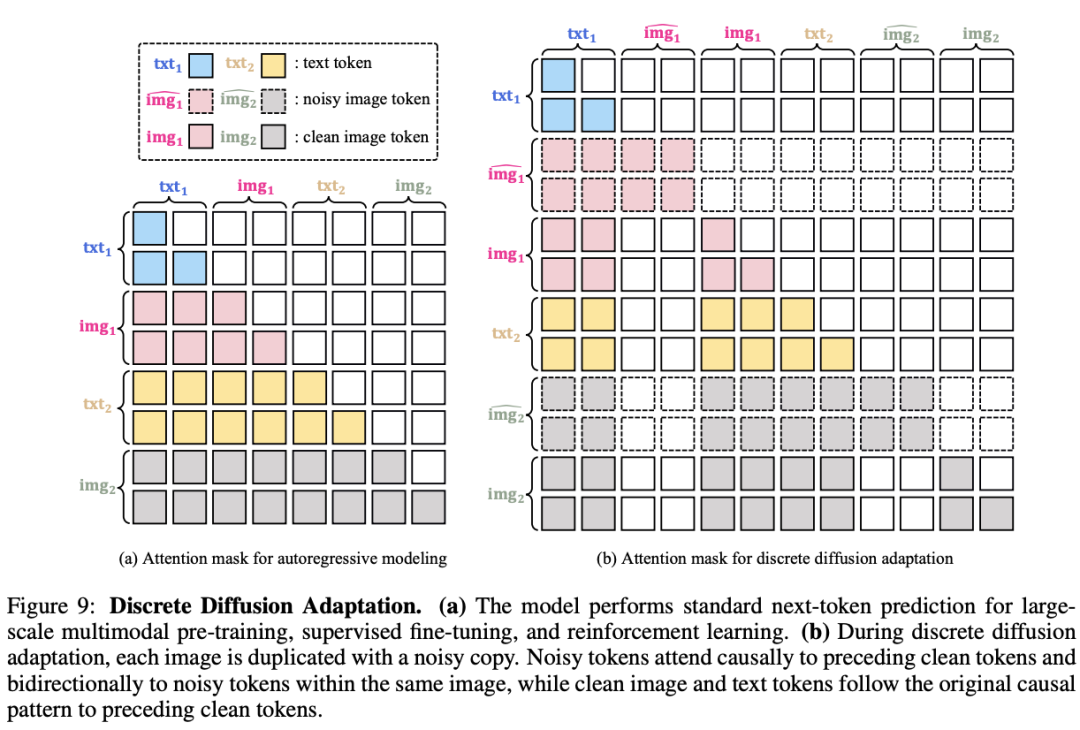
DiDA — 20× Faster Inference for Autoregressive Models
Problem: Autoregressive image generation = slow (token-by-token)
Solution: Discrete Diffusion Adaptation (DiDA)
- Converts model from sequential → parallel token generation
- Process: generate noisy tokens → denoise in parallel refinement steps
- Result: ~20× faster inference with negligible quality loss
- Matches inference efficiency of top closed Diffusion models (e.g., Midjourney)

---
Performance Highlights — From Editing to World Simulation
Any-to-Image Generation & Editing:
- Complex bilingual content, formulas
- Benchmarks surpass Gemini 1.5 Flash, Qwen-VL-Max
Semantic Understanding & World-Building:
- Logical consistency in generated worlds


Reasoning:
- Object replacement via numerical labels

Viewpoint Transformation:
- Bird’s-eye conversion with spatial awareness

Long-sequence Consistency:
- Coherent states/storylines across videos
---
Unique Capabilities in the "World Model" Category
- Visual Narrative
- Coherent protagonist in multi-image stories
- Visual Guidance
- Step-by-step, image+text instructions (e.g., folding clothes, growing kale)



- World Exploration
- Scene navigation commands produce consistent exploration visuals
- Embodied Manipulation
- Plan & visualize robotic arm tasks step-by-step

---
Open Source Approach & Future Potential
- Model release with detailed technical report to invite global collaboration
- Emu3.5 trained with only 34B parameters and <1% of public internet video data
- Expected breakthroughs as scale and data grow


---
References
---
Practical Applications for Creators
Platforms like AiToEarn官网 connect cutting-edge models with content monetization pipelines, enabling:
- AI content generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Instagram, YouTube, X, etc.)
- Analytics & model rankings (AI模型排名)
This ecosystem lets models like Emu3.5 move from research demos → large-scale deployment & monetization quickly.
---