LongCat-Flash-Omni Released and Open-Sourced: Ushering in the Era of Real-Time All-Modal Interaction

LongCat-Flash-Omni — Next-Generation Open-Source Full-Modality Model
Overview
Since September 1, Meituan launched the LongCat-Flash series, beginning with LongCat-Flash-Chat and LongCat-Flash-Thinking, quickly gaining attention in the developer community.
Today, the series expands with a new flagship addition: LongCat-Flash-Omni.

Highlights:
- Efficient Shortcut-Connected MoE architecture (including zero-computation experts)
- Highly efficient multimodal perception modules
- Speech reconstruction module for real-time audio-video interaction
- 560B total parameters, 27B activated, enabling low-latency inference
- Industry-first open-source full-modality LLM with end-to-end architecture and efficient large-parameter inference
Open-Source Access:
---
Technical Highlights
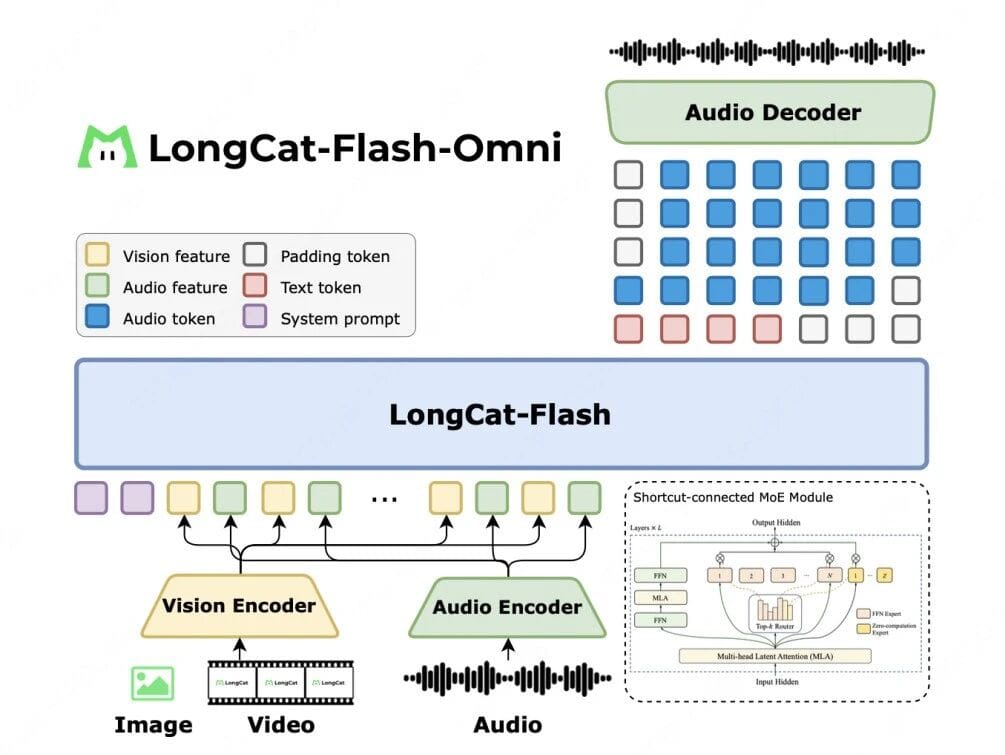
1. Ultra-Performance Integrated Full-Modality Architecture
- Fully end-to-end design integrating offline multimodal comprehension with real-time audio-video interaction.
- Visual/audio encoders act as multimodal sensors.
- Outputs are directly processed by the LLM into text/speech tokens.
- Lightweight audio decoder reconstructs natural speech waveforms.
- Visual encoder & audio codec ≈ 600M parameters each for balanced performance and speed.
---
2. Large-Scale, Low-Latency Interaction
- Breakthrough in pairing large-scale parameters with low-latency.
- 560B total parameters, 27B activated via ScMoE backbone.
- Chunked audio-video feature interleaving for efficient streaming.
- 128K-token context window supports 8+ minutes of interaction.
- Strong in long-term memory, multi-turn dialogue, and sequential reasoning.
---
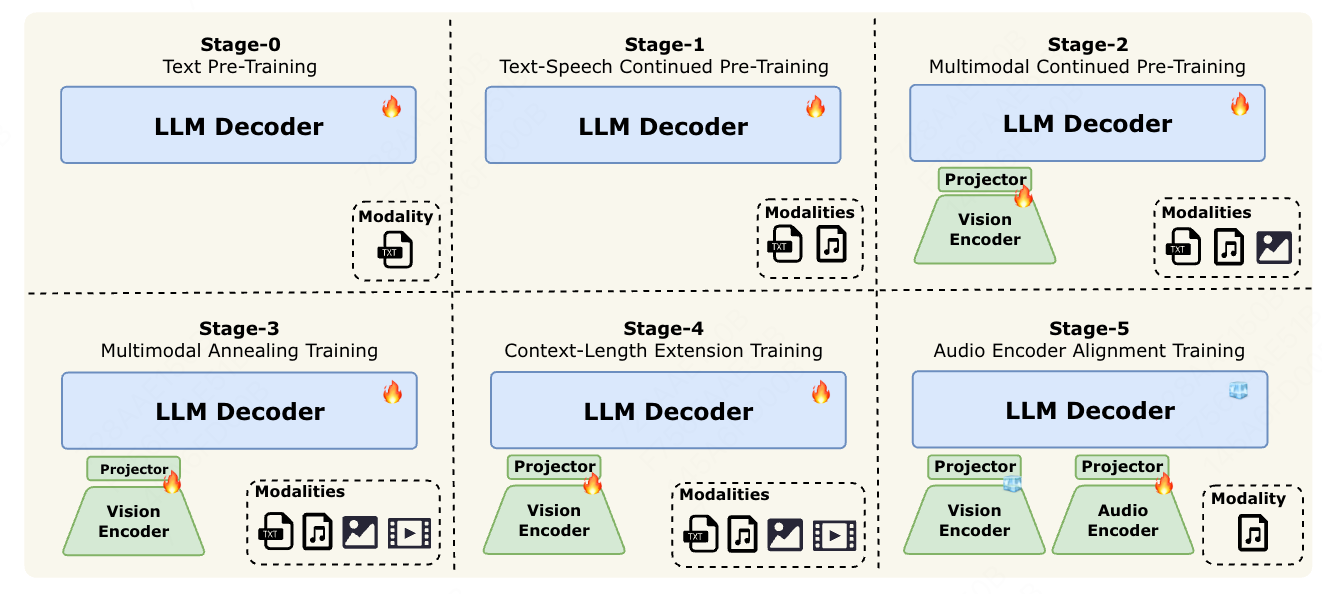
3. Progressive Multimodal Fusion Training Strategy
Addressing “heterogeneity in data distribution across modalities” with a staged, balanced approach:
- Stage 0: Large-scale text pretraining for a strong LLM foundation.
- Stage 1: Introduce speech data close to text, aligning acoustic and language features.
- Stage 2: Add large-scale image–caption pairs and intertwined visual–language corpora.
- Stage 3: Integrate complex video data for spatiotemporal reasoning, while enriching image datasets.
- Stage 4: Expand context from 8K to 128K tokens for extended reasoning.
- Stage 5: Align audio encoder for continuous audio features, boosting fidelity and robustness.
---
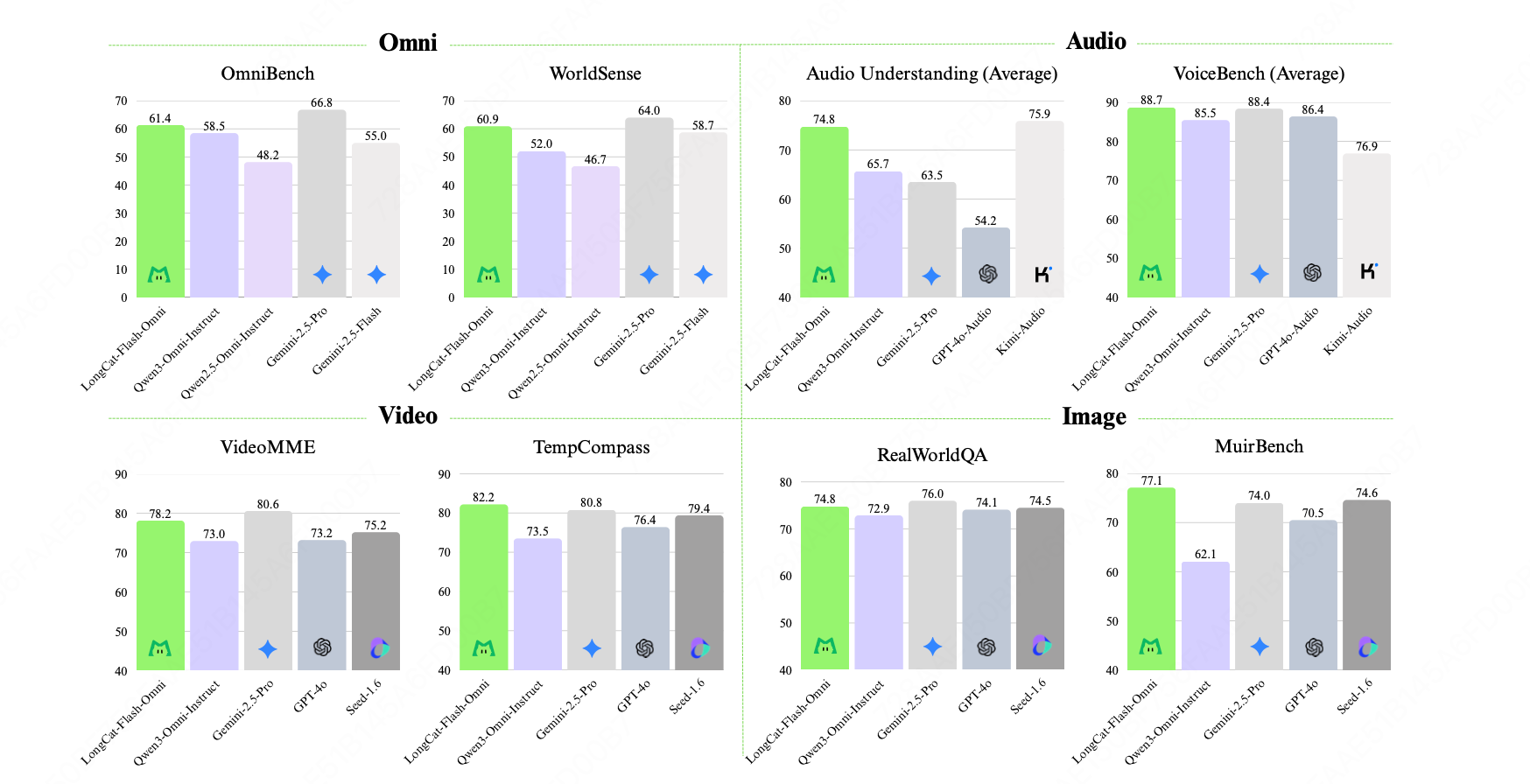
Performance — SOTA Across Modalities
Integrated Full-Modality Benchmarks
- Omni-Bench & WorldSense: Achieve state-of-the-art across text, image, audio, and video.
- Demonstrates "full-modality without IQ drop".
---
Modality-Specific Results
- Text: Maintains and improves performance over earlier LongCat-Flash models; benefits from cross-modal synergy.
- Image Understanding: RealWorldQA score 74.8 — matches Gemini-2.5-Pro, outperforms Qwen3-Omni. Excels in multi-image tasks.
- Audio:
- ASR: Surpasses Gemini-2.5-Pro on LibriSpeech/AISHELL-1.
- S2TT: Strong on CoVost2.
- Audio Understanding: New benchmarks in TUT2017 & Nonspeech7k.
- Real-time human-likeness surpasses GPT-4o.
- Video Understanding:
- Short videos: Exceeds all competitors.
- Long videos: Comparable to Gemini-2.5-Pro & Qwen3-VL.
- Cross-Modality: Outperforms Gemini-2.5-Flash (non-thinking); on par with Gemini-2.5-Pro (non-thinking).
- Significant lead in WorldSense benchmark.
---
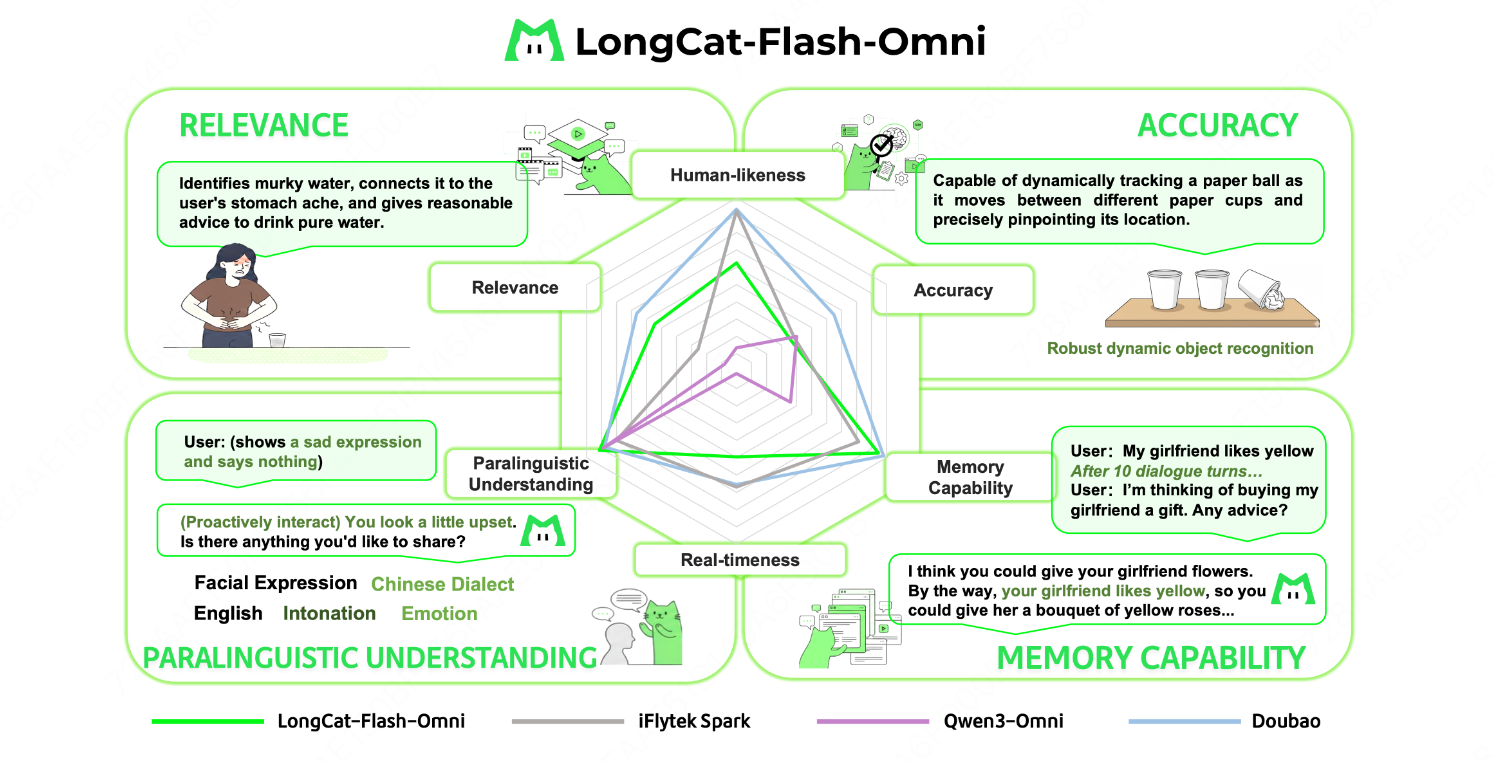
End-to-End Interaction Assessment
- Built proprietary evaluation combining:
- Quantitative User Scoring (250 participants)
- Qualitative Expert Analysis (10 experts, 200 samples)
- Scores +0.56 above Qwen3-Omni for interaction naturalness & fluency.
- Matches top models in paralinguistic understanding, relevance, memory.
- Opportunities for improvement in real-time performance & accuracy.
---
Practical Applications & Monetization
Cross-Platform Publishing
- Platforms like AiToEarn官网 enable AI content generation, publishing, and monetization.
- Integrates analytics & model ranking (AI模型排名).
- Supports publishing on Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X.
---
Try LongCat-Flash-Omni
- Experience online at https://longcat.ai/
- Supports image/file upload and voice calls.
---
LongCat App Now Available
- Features online search & voice calls (video calls coming soon)
- Download via QR code below or search LongCat in the iOS App Store.

---
Open-Source Links:
---
We welcome developer feedback and collaboration.
For creators, AiToEarn官网 offers a practical monetization pathway for leveraging LongCat-Flash-Omni's full-modality capabilities in real-world publishing.