Lots of Insights! Transcript of Silicon Valley’s Internal Discussion on AI Agents – Oct 2, 2025

Datawhale Insights: Why 95% of AI Agents Fail in Production
At a recent Silicon Valley industry event, Oana Olteanu—a renowned venture capitalist—joined engineers and ML leads from Uber, WisdomAI, EvenUp, and Datastrato to discuss how AI Agents can succeed in production environments.
Key statistic: 95% of AI Agents fail in production — not because the models lack intelligence, but because supporting systems (context engineering, security, memory architecture) are immature or missing.

Original link: https://www.motivenotes.ai/p/what-makes-5-of-ai-agents-actually
> Most founders think they're building an AI product, but in reality, they’re building a context selection system.
---
Under the Hood of an AI Agent
Panelists explored the foundational layers necessary for production-grade AI:
- Advanced Context Selection
- Semantic Layers
- Memory Orchestration
- Governance Mechanisms
- Multi-Model Routing Strategies
This synthesis is based on seminar content compiled by Datawhale from Oana’s seminar insights.
---
Context Engineering ≠ Prompt Tricks
Why RAG Is Often Enough—But Rarely Well-Built
Most agreed: model fine-tuning is infrequently required. If retrieval-augmented generation (RAG) is robust, performance can be excellent. Unfortunately, most current RAG systems are too simplistic.
Top failure patterns:
- Over-indexing: Too much irrelevant data confuses the model
- Under-indexing: Insufficient signals lead to poor answers
- Mixing structured + unstructured data: Breaking embeddings or oversimplifying architecture
---
What Advanced Context Engineering Looks Like
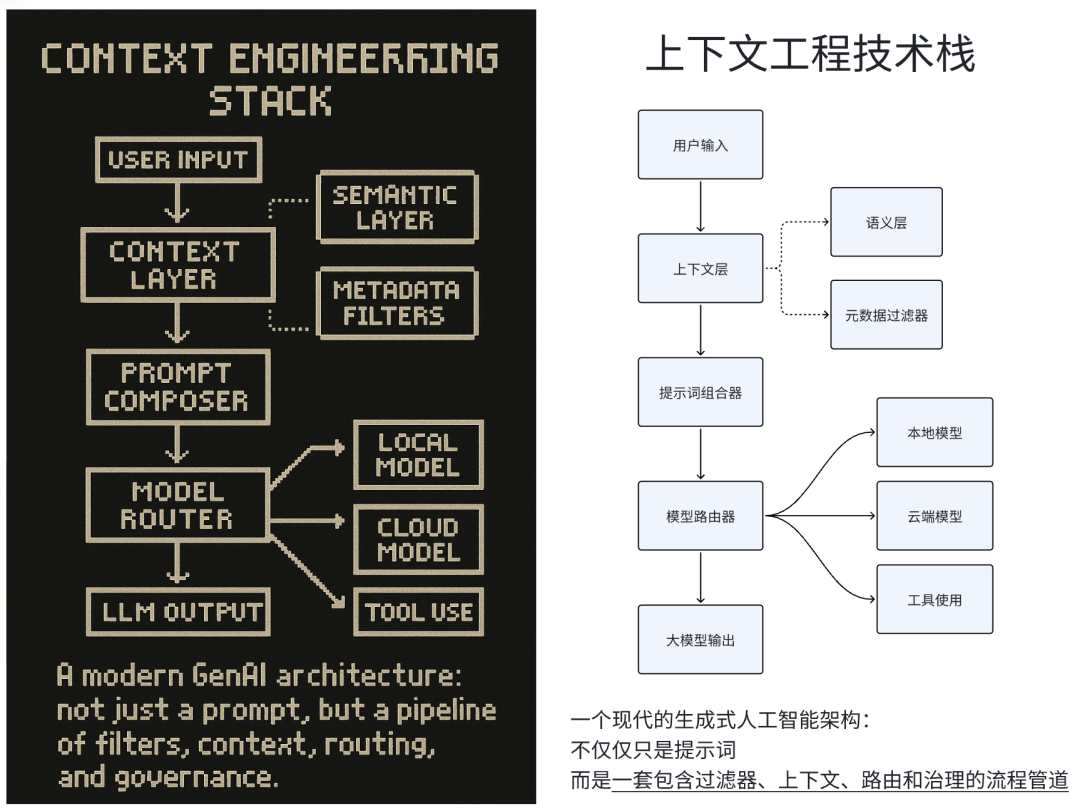
a) Feature Selection for LLMs
Think of context engineering as feature engineering for LLMs:
- Selective context pruning = feature selection
- Context validation = schema/type/timeliness checks
- Context observability = track inputs that improve/ degrade output quality
- Embedding augmentation with metadata
Implication: Context becomes a versionable, auditable, testable artifact—not just text.
---
b) Dual-Layer: Semantic + Metadata
- Semantic layer: Classical vector search
- Metadata layer: Filters by type, timestamp, permissions, domain ontology
Benefits:
Keeps retrieval relevant and structured, not just similar.
---
c) Real Challenges in Text-to-SQL
When asked, “Has anyone deployed text-to-SQL in production?” — none raised their hand.
Reason: Understanding natural language queries in business contexts is harder than the technical mapping.
---
Succeeding with Structured Query Systems
Winning approach:
- Business glossary & terminology mapping
- Query templates with constraints
- Semantic validation before execution
- Feedback loops to improve understanding
---
Governance & Trust — Not Just Enterprise Concerns
Critical requirements:
- Track input-output lineage
- Enforce role-based access control
- Customize output per user permissions
> “Two employees asking the same question should get different answers if permissions differ.”
Solution trend: Unified metadata catalogs embedding access policies directly into indexing/search.
---
Trust Is a Human Problem
Story: One guest’s wife bans Tesla autopilot—not due to function, but lack of trust.
Same issue in enterprise AI: Reliability, explainability, and auditability > raw capability.
---
Common Trait in the Top 5%
Design for human-in-the-loop:
- Humans review + override AI decisions
- Continuous improvement via feedback loops
---
Memory: An Architectural Choice
Memory Tiers
- User-level: Personal prefs, style, tone
- Team-level: Shared queries, dashboards
- Org-level: Policies, institutional knowledge
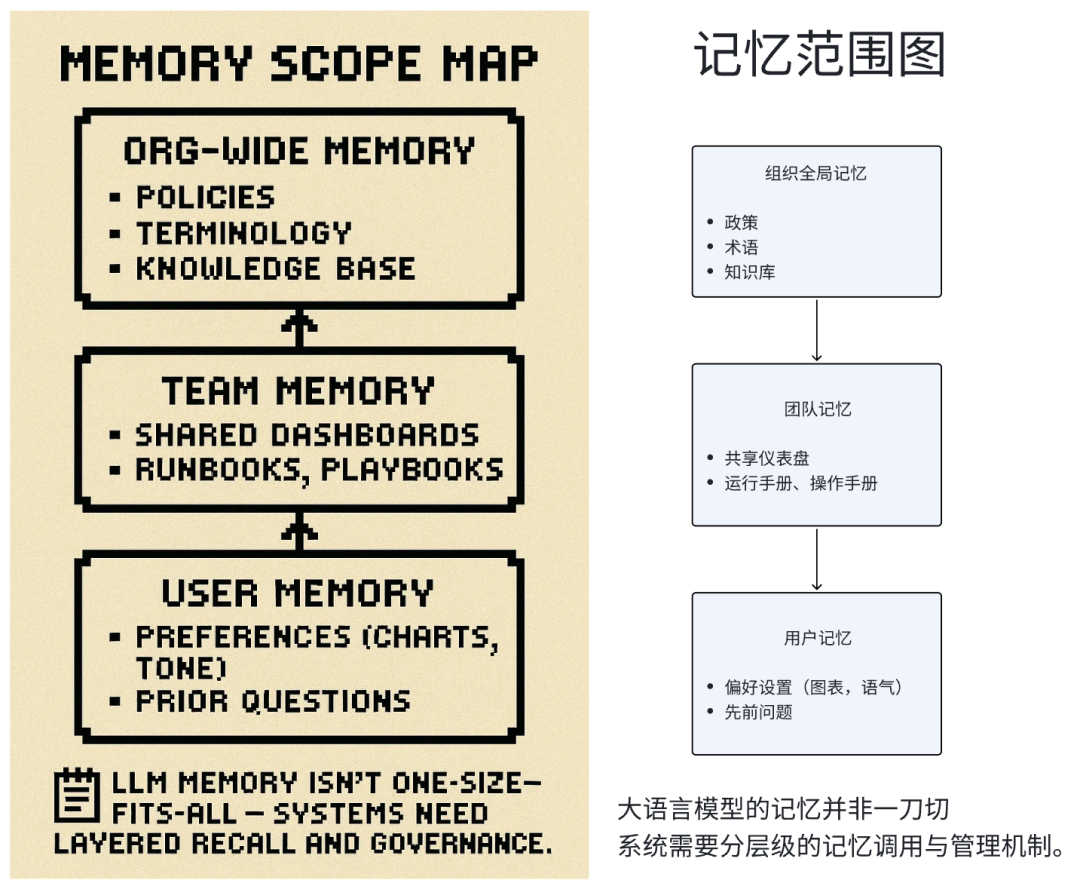
Best practice: Abstract memory into independent layers with version control.
---
Personalization vs Privacy
Memory offers:
- Behavior customization
- Event-driven proactive assistance
Cold-start example: Uber’s BI chat tool used past queries to recommend new ones and spark conversation.
Privacy risk: Over-personalization can feel intrusive — e.g., AI knowing children's names unprompted.
---
Designing Memory Responsibly
- Balance UX benefits with privacy concerns
- Avoid scope creep to protect access control
- Goal: A secure, user-controlled portable memory layer
---
Multi-Model Reasoning & Orchestration
Model routing criteria:
- Task complexity
- Latency
- Cost
- Compliance requirements
- Query type
Example pipeline:
- Simple queries → local models
- Structured queries → DSL/SQL translators
- Complex analysis → GPT-4 / Anthropic / Gemini
- Verification → dual-model redundancy
Benefit: Optimizes both performance & cost without brittleness.

---
Chat Interface ≠ Always Optimal
When chat shines: Lowers learning curve for complex tasks like BI.
When GUI shines: Graphic adjustments post-results.
Hybrid UX approach:
- Chat for entry
- GUI for refinement
- Mode choice per task
---
What’s Still Missing
1. Context Observability
Systematic tools to see which contexts improve or harm model responses.
2. Composable Memory
Secure, portable, user-organized memory not tied to any provider.
3. Domain-Aware Languages
High-level, constraint-safe DSLs instead of brittle text-to-SQL.
4. Latency-Aware UX
Match response speed to task requirements.

---
The Future Moat in Generative AI
Not model access, but:
- Context quality
- Memory design
- Stable orchestration
- Trustworthy UX
---
5 Key Questions for Founders
- Context capacity: Optimal window + content strategy
- Memory boundary: Scope, storage, user inspection
- Output traceability: Clear input-output linkage
- Model strategy: Single vs multi, routing logic
- Trust factors: Security + feedback design
---
Final Insight
Early consideration of context, memory, orchestration, trust will define products’ long-term viability.
Platforms like AiToEarn官网 are exploring integrated ecosystems—AI-driven content generation, cross-platform publishing, analytics, orchestration, and model ranking (AI模型排名)—helping creators and enterprises operationalize AI with trust, portability, and multi-channel scale.