# Lumina-DiMOO: A Unified Multimodal Diffusion Language Model
**Date:** 2025-11-16 11:59
**Location:** Hong Kong, China
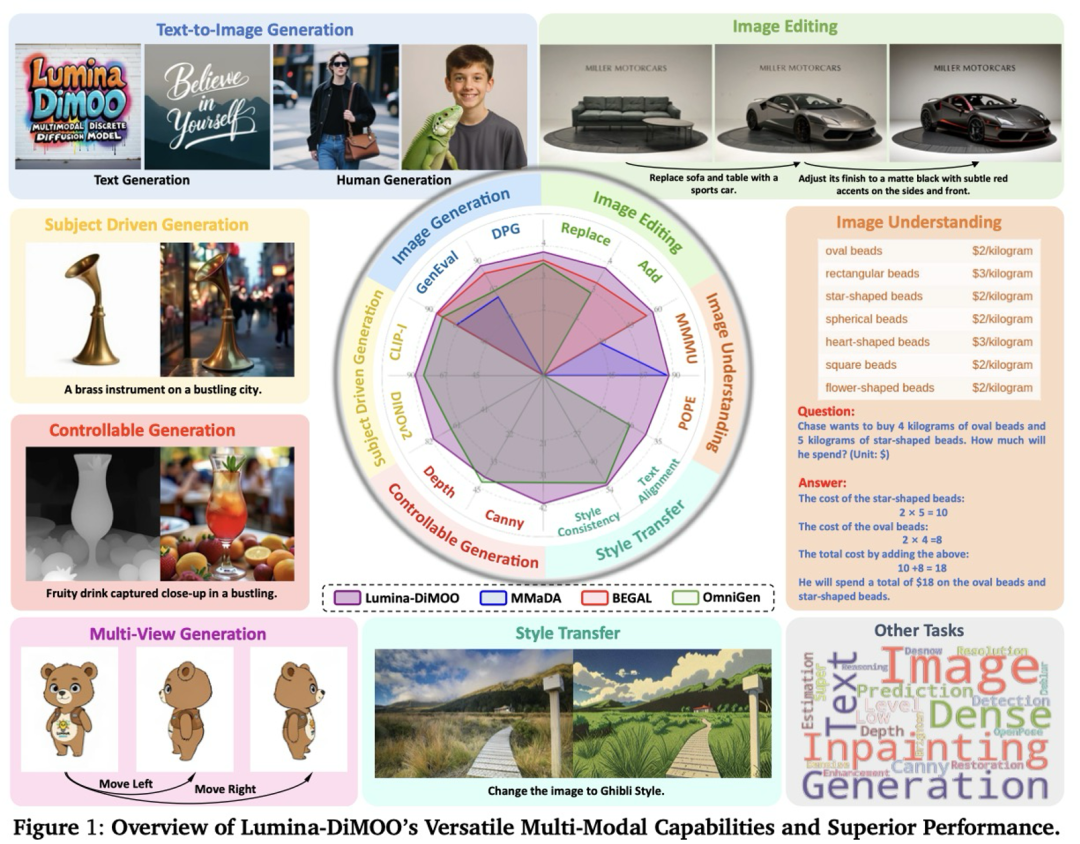
From **text→image**, **image→image**, and **image→text** — Lumina-DiMOO forms a **full-stack capability loop**.

---
## Introduction
The **Shanghai Artificial Intelligence Laboratory** has launched **Lumina-DiMOO**, a cutting-edge **multimodal generation-and-understanding integrated diffusion language model**.
Built on **Discrete Diffusion Modeling**, Lumina-DiMOO unifies multimodal tasks under one framework, enabling seamless text→image, image→image, and image→text generation.

**Quick Facts:**
- **Paper Title:** *Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding*
- **Paper Link:** [arxiv.org/pdf/2510.06308](https://arxiv.org/pdf/2510.06308)
- **GitHub:** `Alpha-VLLM/Lumina-DiMOO`
- **Keywords:** unified multimodal generation, understanding, diffusion language model
---
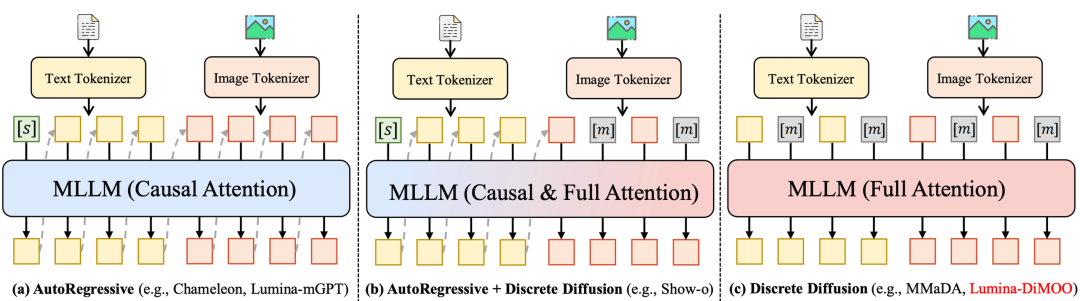
## Background: Limitations of Autoregressive Generation
From Chameleon to Lumina-mGPT, and Janus-Pro — most “unified multimodal models” rely on **autoregressive (AR)** architectures, which have key drawbacks:
- **Slow Generation:** Token-by-token processing results in minutes-long image generation times.
- **Limited Quality:** Poor high-resolution detail; low fine-grained fidelity.
- **Fragmented Tasks:** Generation and understanding are handled separately.
---
## The Rise of Diffusion Language Models
Lumina-DiMOO adopts a **pure discrete diffusion framework**:
- **Parallel bidirectional attention** for faster multimodal fusion.
- **Streamlined integration** of generation and understanding across modalities.
- **Faster & more precise** than AR models.
---
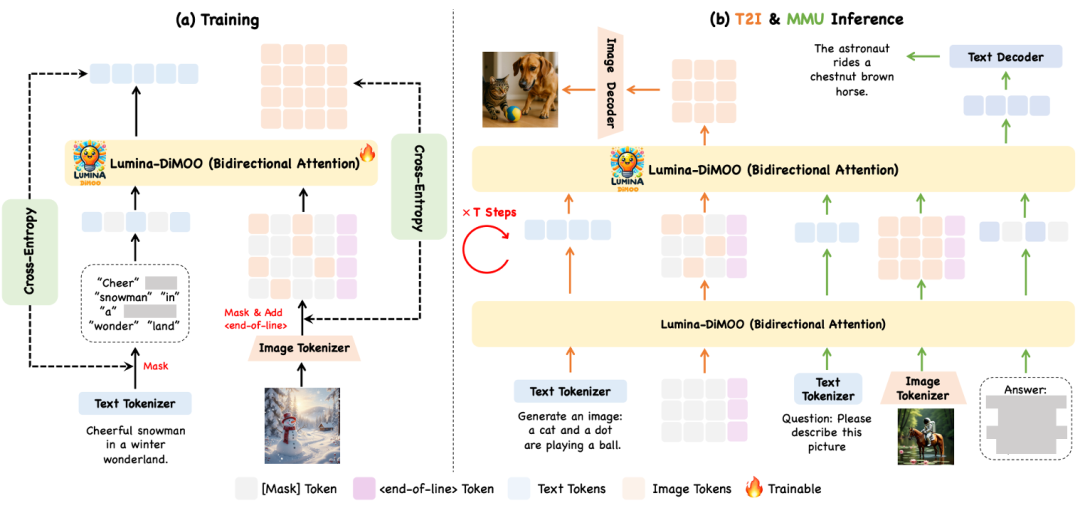
### 1. Discrete Diffusion Architecture
**Core Benefits:**
- Parallel generation.
- Bidirectional attention.
- Handles text-to-image creation, image editing, style transfer, and image understanding **in a single framework**.
---
### 2. Efficient Parallel Generation
Unlike AR models:
- Processes multiple tokens at once.
- Starts with fully masked tokens, progressively decoding into text or images.
- **Shorter generation time** + **enhanced quality**.
---
### 3. Bidirectional Attention Mechanism
**Advantages:**
- Captures both **textual context** and **image structural details**.
- Ensures high text-image consistency.
- Improves cross-modal understanding.
---
### 4. Joint Optimization
Uses a **unified optimization strategy**:
- Enhances synergy between text and image tasks.
- Improves performance metrics and user experience.
- Enables seamless task switching.
---
## Real-World Integration: AiToEarn
Platforms like [AiToEarn官网](https://aitoearn.ai/) complement models like Lumina-DiMOO:
- **Global AI content monetization** tool.
- Multi-platform publishing: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
- Integrates AI generation, analytics, and model ranking.
---
## Accelerated Sampling: Max-Logit Caching
During inference, Lumina-DiMOO uses **Max-Logit Caching** to:
1. Cache stable/high-confidence tokens.
2. Skip recalculations for unchanged tokens.
3. Combine with parallel inference to:
- **Speed generation**
- **Preserve fine detail**
- **Reduce computational cost**
---
## Model Self-Evolution: Self-GRPO
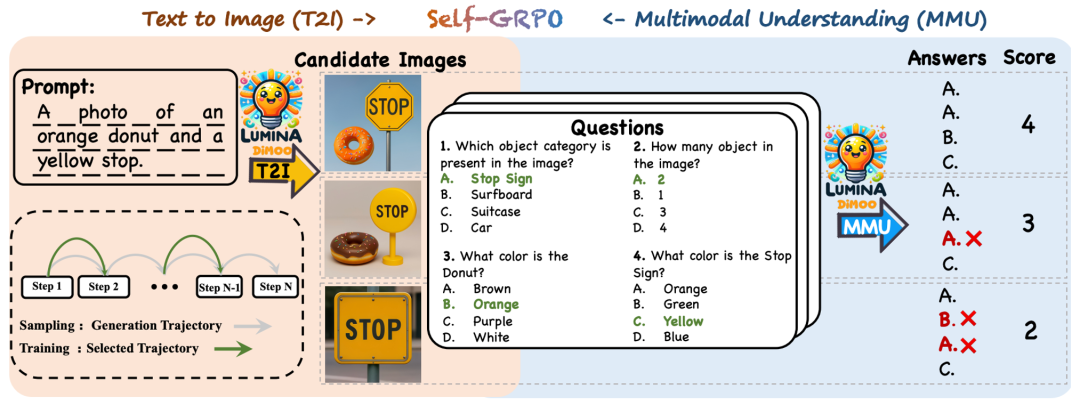
**Self-GRPO** unifies:
- Image generation
- Multimodal understanding
...into a **reinforcement learning closed loop**:
**Process:**
1. Generate →
2. Understand →
3. Assess answer accuracy →
4. Reward & optimize →
5. Correct & improve.
**Outcome:**
A prototype of an **intelligent agent** with autonomous reflection ability.
---
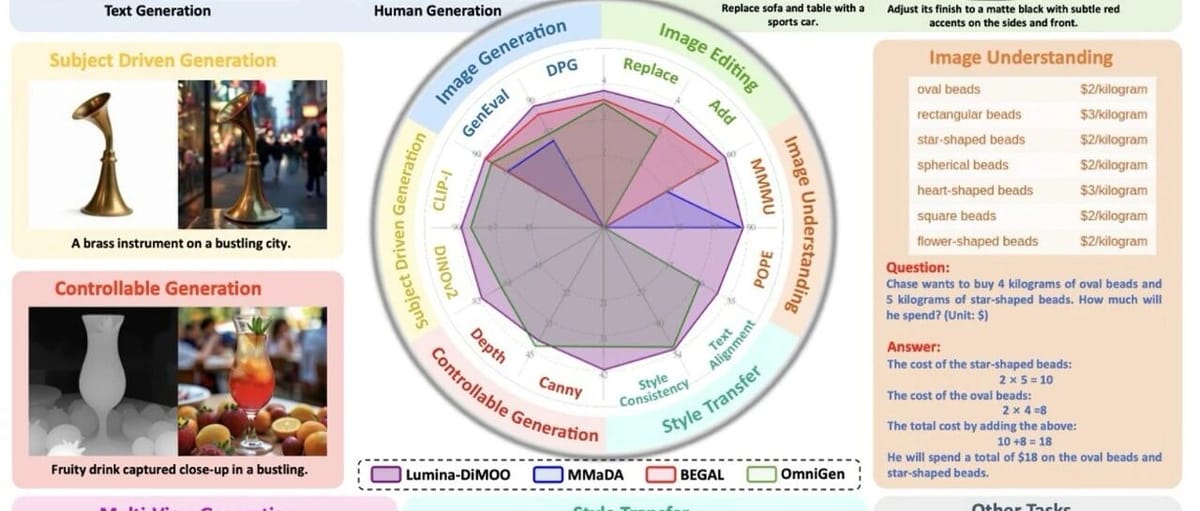
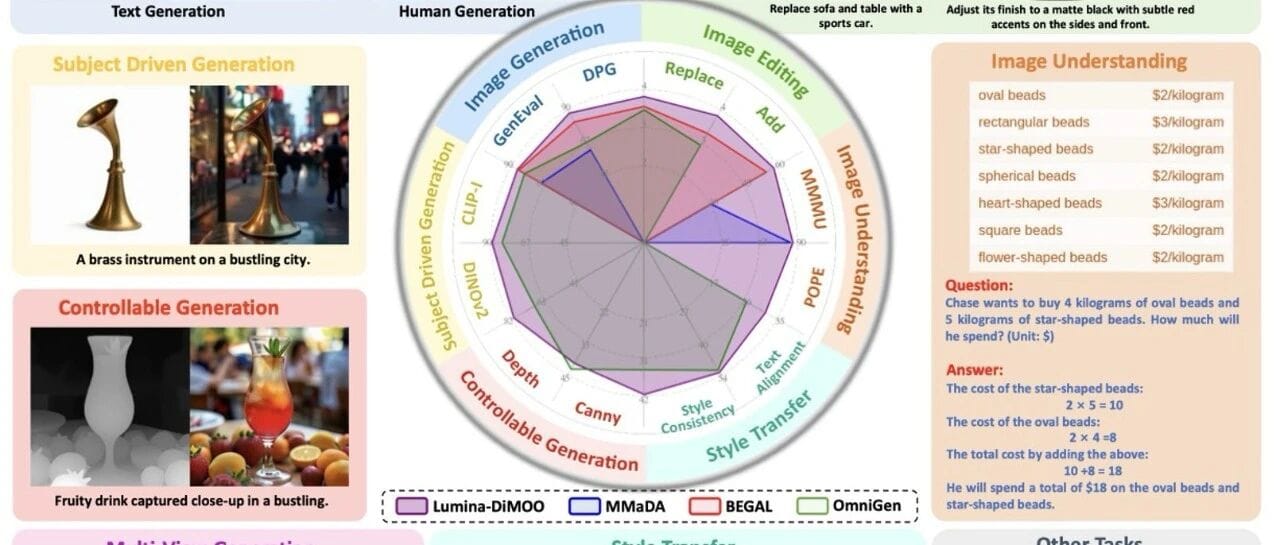
## Performance: SOTA Achievements
Lumina-DiMOO ranks **top** in major benchmarks:
- **UniGenBench**: #1 among open-source models.
- **GenEval Score:** 0.88 — surpassing GPT-4o, BAGEL, Janus-Pro.
- **DPG, OneIG-EN, TIIF:** Excellent in semantic consistency, layout understanding, attribute binding, reasoning.
---
## Future Outlook
Lumina-DiMOO moves toward **native multimodal intelligence**:
- Reads
- Writes
- Draws
- Thinks
> “We hope our model will not only understand the world, but also create the world.”
— Alpha-VLLM Team

---
## Explore More
**AiToEarn**: Multi-platform AI content publishing and monetization.
Check live AI model rankings: [AI模型排名](https://rank.aitoearn.ai)
Read more: [AiToEarn博客](https://blog.aitoearn.ai)
---
[Read Original Article](2651001914)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=bfb3d2a1&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzA3MzI4MjgzMw%3D%3D%26mid%3D2651001914%26idx%3D4%26sn%3D61d7c17834c851ab61eaf8d425b3d8ce)