Making Robots “Think and Act Accurately”: VLA-R1 Brings “Reasoning + Action” into the Real World
2025-10-25 12:24 Beijing
Letting the model both explain its reasoning process clearly and execute actions accurately

---
Introduction
In robotics and intelligent agents, a core challenge is bridging the gap between understanding instructions and performing precise actions.
For example:
- “Put the yellow bowl into the white empty basket.”
- “Take the milk out of the microwave and place it on the dining table.”
This requires:
- Environment understanding
- Instruction parsing
- Path planning & affordance reasoning
- Grounding reasoning into exact physical actions
Current Vision-Language-Action (VLA) models often output direct action sequences without explicit reasoning about affordance–trajectory relationships, which increases error rates in complex scenarios.
Goal of VLA-R1:
Add a structured reasoning step, then use reinforcement learning to ensure accurate execution — making the robot explain first and act second.
---
VLA-R1: Overview

- Paper: VLA-R1: Enhancing Reasoning in Vision-Language-Action Models
- Read Paper
- Project Page: https://gigaai-research.github.io/VLA-R1/
Summary:
VLA-R1 is a reason-first, execute-second model that integrates:
- Chain-of-Thought (CoT) supervision
- Verifiable Reward Reinforcement Learning (RLVR, built on GRPO)
It optimizes both reasoning quality and execution accuracy, following the structure:
...
...---
Key Innovations
1. Two-Stage Training (SFT + RL)
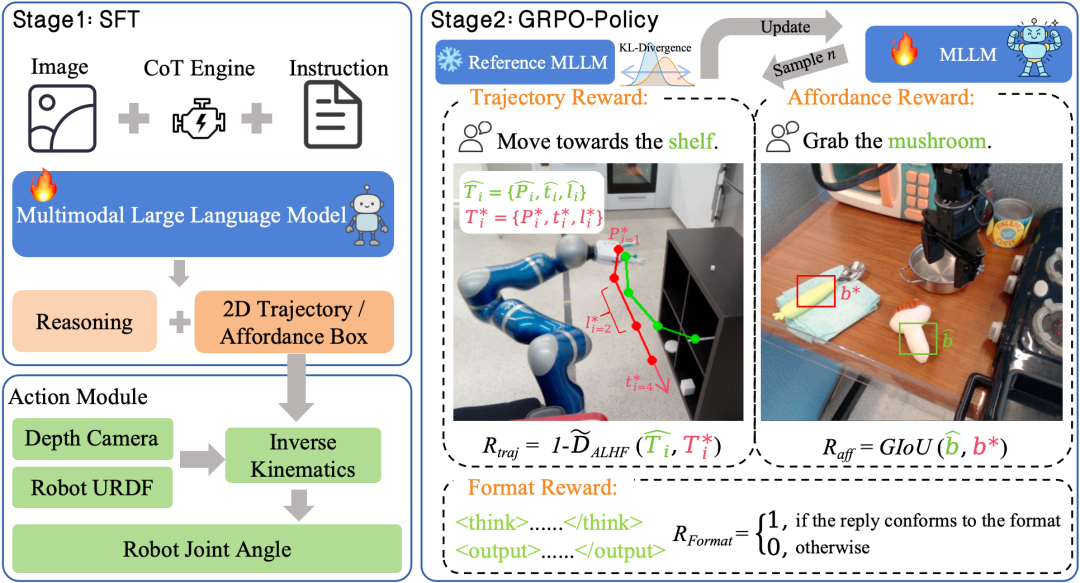
- Stage 1 — SFT with CoT supervision: Teacher-guided fine-tuning
- Stage 2 — RL with verifiable rewards (GRPO): Stable refinement from “can think” to “can do”
- Uses group-wise normalized advantage
- Enforces KL constraints
---
2. Three Verifiable Rewards (RLVR)
Ensures the model:
- Sees correctly
- Moves correctly
- Formats correctly
Reward Types:
- Spatial Alignment (GIoU):
- Keeps gradients valid even when boxes don’t overlap.
- Trajectory Consistency (ALHF Fréchet distance):
- Considers position, tangent angles, and segment length ratios.
- Output Format Reward:
- Enforces `` and `` structuring.

---
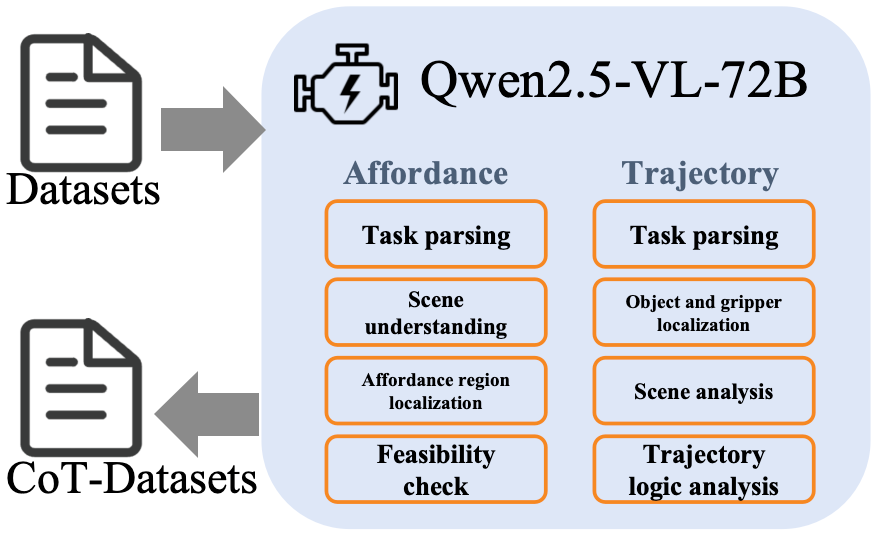
3. VLA-CoT Data Engine & Dataset
- Generated CoT data using Qwen2.5-VL-72B
- 13K samples aligned with visual/action data
- Structured four-step reasoning prompt

---
Experimental Overview
Evaluation across:
- In-Domain
- Out-of-Domain
- Simulation platforms
- Real robots
Ablations: CoT vs. RL vs. both.
---
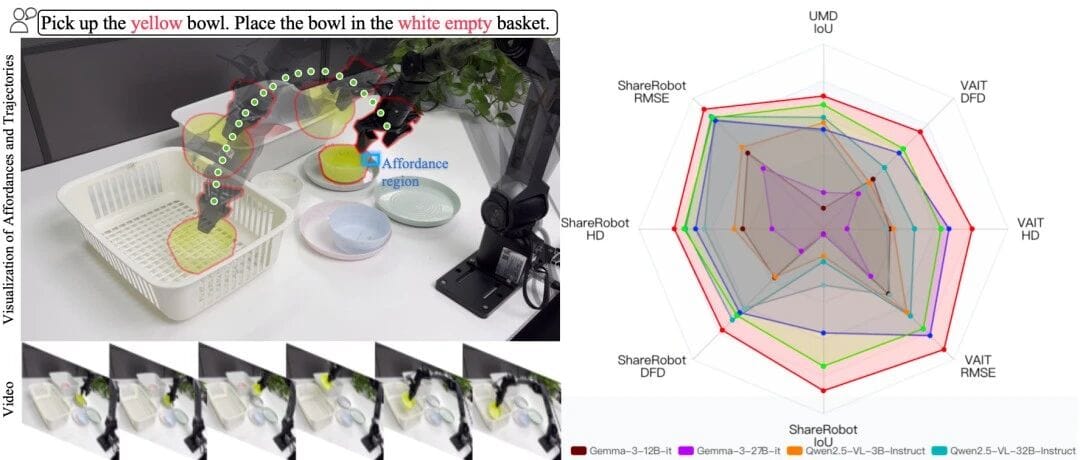
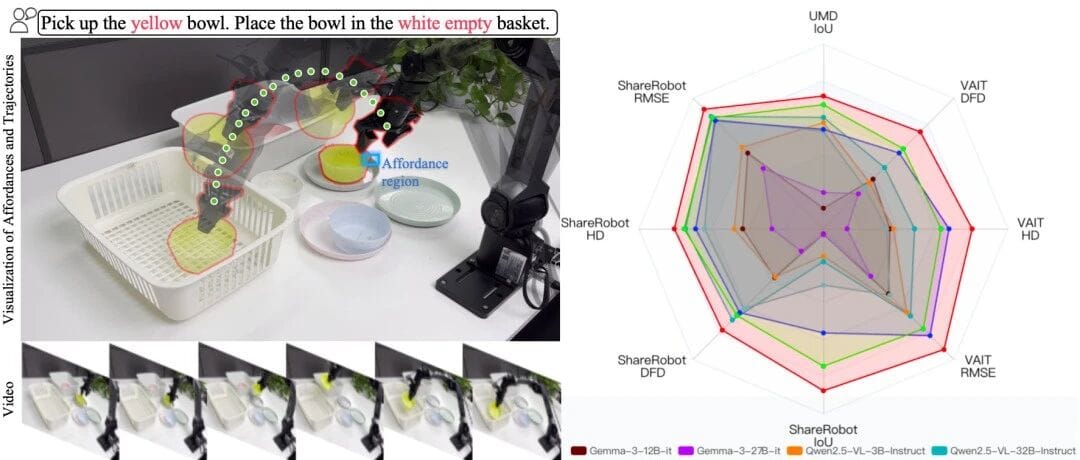
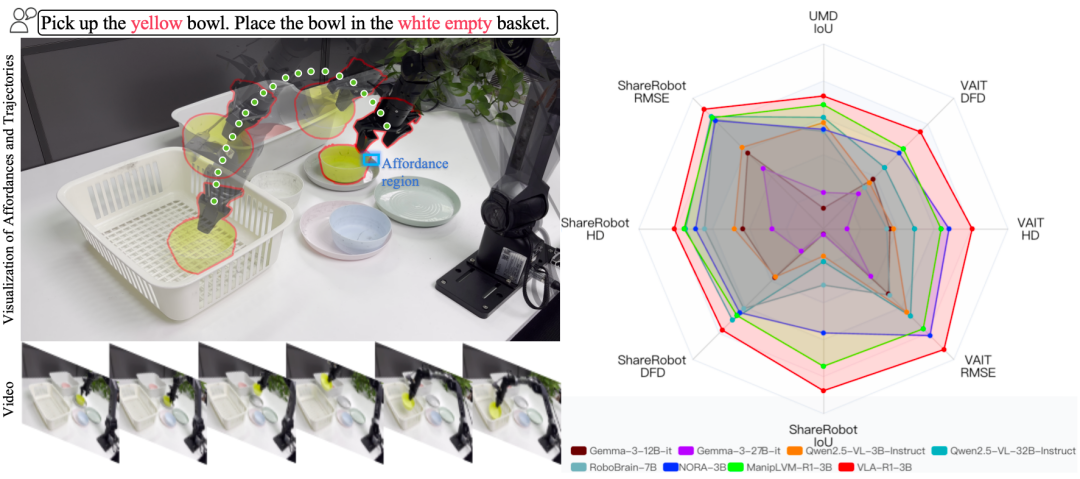
Benchmarks
In-Domain
Dataset: VLA-CoT-13K — Affordance Detection + Trajectory Generation.
Objects: bowls, cups, spoons, pens, boxes, baskets.
Results:
- Affordance IoU: 36.51 (+17.78% over baseline)
- Avg trajectory error: 91.74 (−17.25% improvement)
---
Out-of-Domain
Datasets: UMD (affordance labels) + VAIT (scene-instruction pairs)
Results:
- Affordance IoU: 33.96 (UMD)
- Trajectory error: 93.90 (VAIT)
---
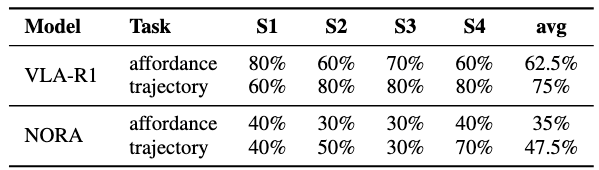
Real Robot Experiments — 4 Tabletop Scenarios
Scenarios:
- S1: Colored bowl pickup (similar colors challenge)
- S2: Fruit pickup (same-category differentiation)
- S3: Complex kitchen with occlusion
- S4: Mixed clutter with multiple containers
Results:
- Affordance SR: 62.5%
- Trajectory SR: 75%

---
Simulation (Piper / UR5)
Tested cross-platform with diverse object/instructions.
Results:
- Affordance SR: 60% / 50%
- Trajectory SR: 80% / 60%


---
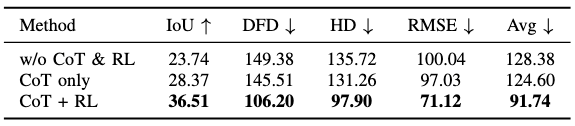
Ablation Study
Configurations:
- Direct trajectory output
- CoT only
- CoT + RL
Findings:
- CoT boosts IoU from 23.74 → 28.37
- CoT+RL boosts IoU to 36.51 with lower trajectory error
---
Demo Display
Thought Process Showcase
Real Machine Platform
Simulation Platform
---
Application Prospects
Household Picking & Storage
- Handles clutter, color similarity, uneven lighting
- Resolves ambiguities before acting:
- e.g., spoon → bowl, pen → white box
Warehouse Picking & Light Assembly
- Explains why container/path chosen
- Smooth, safe trajectories with MES/PLC integration
Educational & Evaluation
- `` + `` format supports grading and teaching
- Standard metrics for comparison between training methods

---
Related AI Content Publishing
Platforms like AiToEarn let creators monetize AI-driven content.
Features:
- Generate → Publish → Analyze → Monetize
- Multi-platform delivery: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X
- Open-source model ranking & analytics
Further resources:
---
© THE END
For repost authorization, please contact this account.
Original: Read here