Meta SAM3 Open Source: Making Image Segmentation Understand Your Words
Meta Open-Sources Segment Anything Model 3 (SAM 3)
Meta has officially released and open-sourced Segment Anything Model 3 (SAM 3) — a unified foundation model for promptable segmentation in images and video.
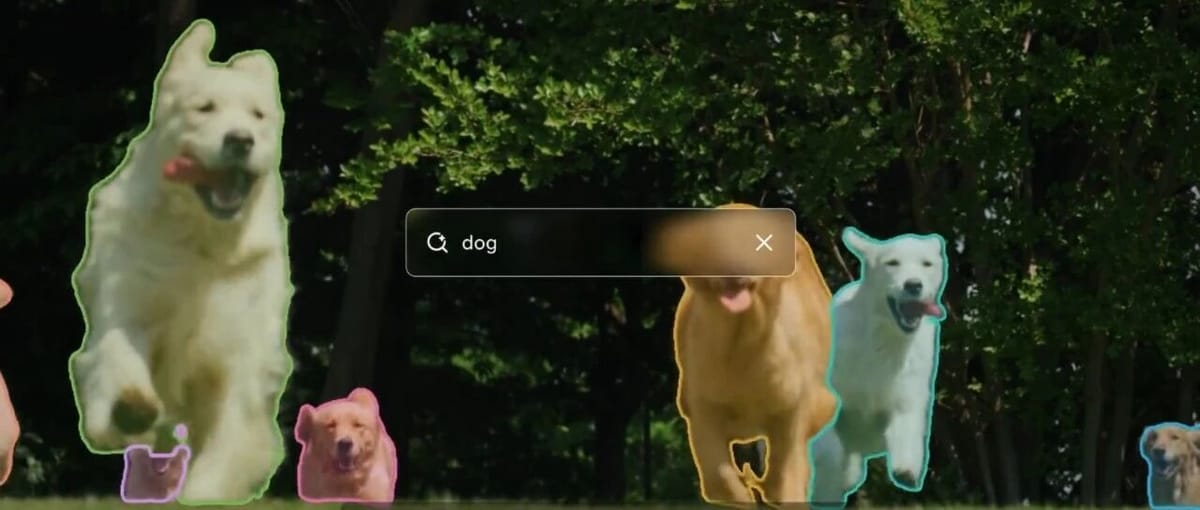
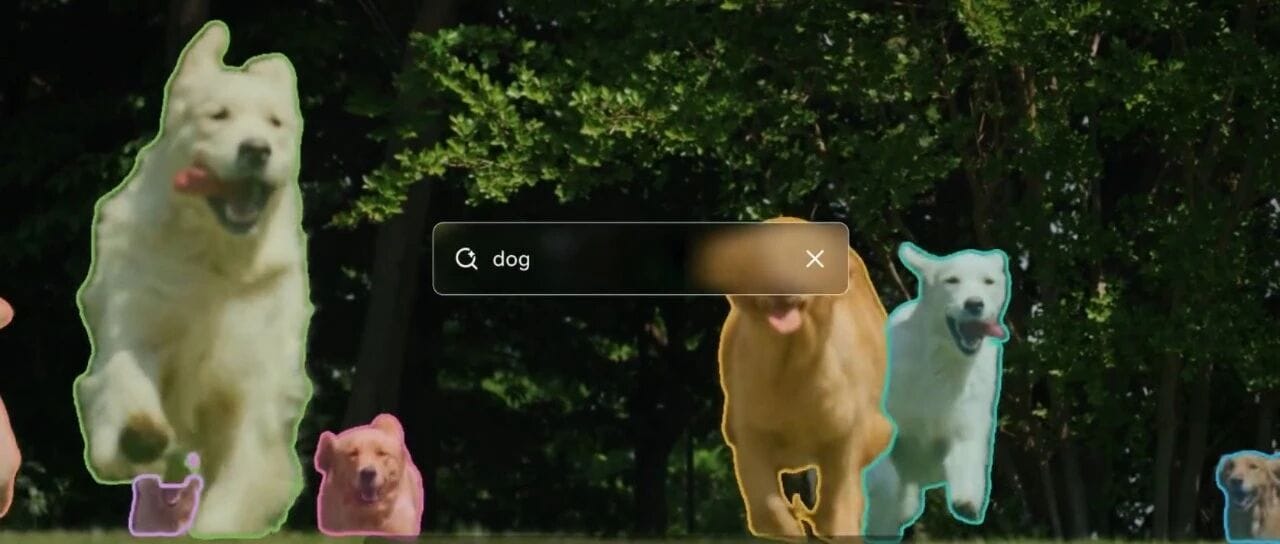
SAM 3 can detect, segment, and track targets using text prompts or visual cues (points, boxes, masks).
---
Why SAM 3 Matters
In traditional image segmentation:
- Predefined labels limit the objects you can isolate.
- Models handle common objects like person, but fail on fine-grained, specific concepts (e.g., red striped umbrella).
SAM 3 breakthrough: Promptable Concept Segmentation
- Segments all instances of a concept based on a short text or sample image.
- Handles large-scale open vocabulary.
---
Visual Examples
Tracking a fluffy golden retriever

Tracking a player wearing a white jersey

---
Performance Highlights
- Segments all instances of open-vocabulary concepts.
- Responds to far more prompts than prior models.
- On SA-Co benchmark:
- Achieved 75%–80% of human performance across 270K+ unique concepts.
- Supports 50× more concepts than current benchmarks.
---
Open-Source Links
- ModelScope: http://modelscope.cn/organization/facebook
- GitHub: https://github.com/facebookresearch/sam3?tab=readme-ov-file
---
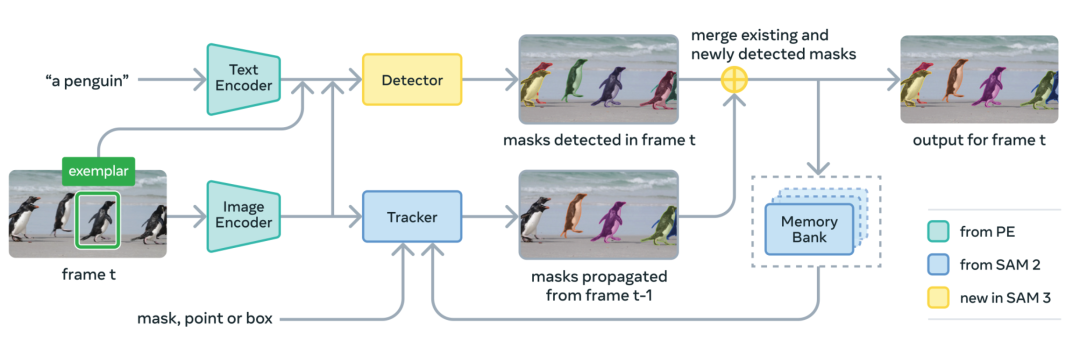
01 — Model Architecture: Promptable Concept Segmentation
SAM 3 integrates multiple Meta AI technologies:
- Encoders: Derived from Meta Perception Encoder (April release), improving classification & detection performance.
- Detector: Built on DETR (Transformer-based object detection).
- Tracker: Memory bank + encoder from SAM 2.
- Additional Components: Public datasets, benchmarks, and model improvement algorithms.
---
02 — Data Engine: AI + Human Annotation
Meta created a scalable closed-loop system combining:
- SAM 3
- Human annotators
- AI annotators
Speed gains:
- Negative prompts: 5× faster than manual labeling.
- Positive prompts: 36% faster in fine-grained domains.
Dataset scale:
Over 4 million unique concepts annotated.
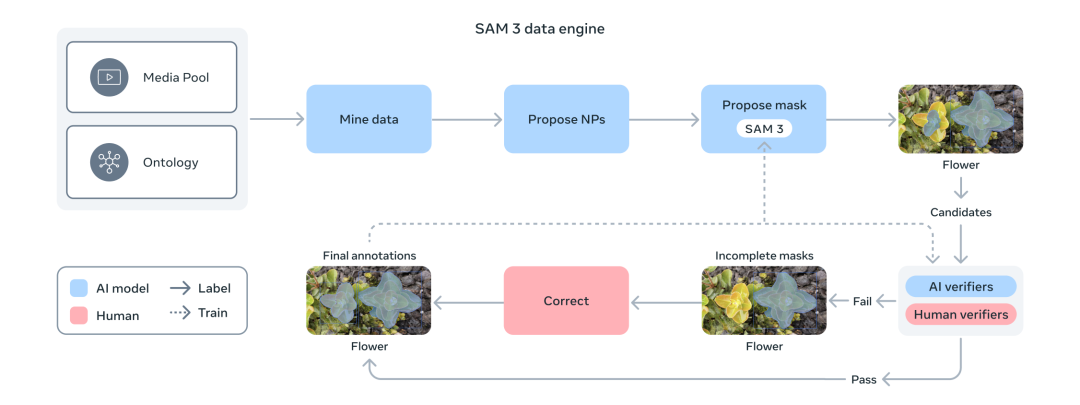
Workflow:
- Pipeline:
- SAM 3 + Llama-based image captioning mine content from massive image/video datasets.
- Extract captions → text labels → initial segmentation masks.
- Verification:
- Joint human & AI review/refinement.
- AI Annotators:
- Specially trained Llama 3.2v model — matching or surpassing human mask-quality judgment.
---
03 — Benchmark Dataset: SA-Co
SA-Co (Segment Anything with Concepts):
- Designed for large-vocabulary promptable segmentation.
- Vastly expands semantic concepts compared with prior datasets.
- Open-sourced for reproducibility & innovation.

---
04 — Model Inference
Environment Setup
# 1. Create a new conda environment
conda create -n sam3 python=3.12
conda deactivate
conda activate sam3
# 2. Install pytorch-cuda
pip install torch==2.7.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# 3. Clone repository and install
git clone https://github.com/facebookresearch/sam3.git
cd sam3
pip install -e .
# 4. Install extra dependencies
# For notebook examples
pip install -e ."[notebooks]"
# For development
pip install -e ."[train,dev]"Model Download
modelscope download --model facebook/sam3 --local_dir checkpoints---
Python Usage Example
import torch
#################################### For Image ####################################
from PIL import Image
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
# Load the model
model = build_sam3_image_model()
processor = Sam3Processor(model)
# Load an image
image = Image.open("")
inference_state = processor.set_image(image)
# Prompt the model with text
output = processor.set_text_prompt(state=inference_state, prompt="")
# Get the masks, bounding boxes, and scores
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]
#################################### For Video ####################################
from sam3.model_builder import build_sam3_video_predictor
video_predictor = build_sam3_video_predictor()
video_path = "" # a JPEG folder or an MP4 video file
# Start a session
response = video_predictor.handle_request(
request=dict(
type="start_session",
resource_path=video_path,
)
)
response = video_predictor.handle_request(
request=dict(
type="add_prompt",
session_id=response["session_id"],
frame_index=0, # Arbitrary frame index
text="",
)
)
output = response["outputs"]---
What You Get
- Masks
- Bounding boxes
- Scores
- All generated by text prompts for images or videos.
---
AiToEarn: Monetizing AI Content
For creators working across multiple platforms:
AiToEarn官网 provides:
- Cross-platform AI content publishing to Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
- Analytics & model rankings (AI模型排名).
- Open-source tooling (GitHub repo).
Benefit: Integrating tools like SAM 3 into AiToEarn workflow can:
- Save time distributing creative outputs.
- Streamline content monetization.
---
Tip: Click Read Original to view the full model link and repository.


