MiniMax and Kimi Face Off for “Attention”

Moonshot vs. MiniMax: A 72-Hour Duel in Attention Mechanisms

On October 29, Moonshot AI researcher Zhou Xinyu reposted MiniMax M2 Tech Blog’s announcement on X with a cheeky comment:
> “Minimax don't worry, Kimi got your back 😘”
He later posted the identical remark on Zhihu.
Whether playful or provocative, the message hinted at something brewing.
---
The M2 Release and MiniMax’s Full-Attention Bet
Two days after M2’s release, MiniMax pre-training lead Haohai Sun published a candid technical blog on Zhihu and X explaining why the team abandoned efficient attention.
Key point:
> “In industrial systems, efficient attention methods still fall behind Full Attention.”
They addressed common questions like “Why not linear/sparse attention?”, noting the challenges in industrial deployment.
---
What Did “Got Your Back” Mean?
The answer came 24 hours later:
On October 30, Moonshot AI launched Kimi Linear, a 48B-parameter hybrid-attention model:
- 75% KV cache reduction
- 6× throughput boost for long-context tasks
The abstract claimed:
> “…for the first time, outperforms full attention under fair comparisons across various scenarios.”
---
1. MiniMax M2: Returning to Full Attention

Previous setup: M1 Lightning used Softmax + MoE with million-token contexts.
M2 change: A return to Full Attention for robustness in agent & code generation.
Performance & Cost Wins:
- Price: ~8% of Claude Sonnet 4.5 (USD $0.3 per million-token input)
- Speed: ~2× faster inference (TPS ≈ 100)
- Method: “Efficient activation parameter design” for optimal balance.
---
Industry Praise:
The blog Why M2 is Full Attention drew commendations for its openness:
- “A rare engineering perspective share”
- “Sparse attention’s tail risk discussion is brilliant”
---
Haohai Sun's Three Key Challenges
- Pipeline Complexity Explosion
- Large models must serve >10 scenarios (code/math, agent, multimodal, RL, etc.).
- Every new efficient attention mechanism must pass all scenario validations — complexity grows exponentially.
- Limitations in Evaluation Systems
- Small-scale gains often fail at large-scale training.
- Multi-hop reasoning weaknesses only surface after significant resource commitment.
- Benchmarks: KorBench, BBEH, Dyck language from BBH.

- Incomplete Infrastructure
- Linear attention training is memory-bound.
- Inference requires low-precision storage, prefix caching, speculative decoding — all immature.
- Verification time > design time for new Transformer variants.
---
Cost vs Latency:
Full Attention’s bottleneck is cost, not speed. MiniMax bets on GPU advances plus engineering tweaks to keep performance high.
---
2. Moonshot’s Counter: Kimi Linear
Zhou Xinyu — co-author of the MoBA (Mixture of Block Attention) paper — hinted at Kimi’s move.
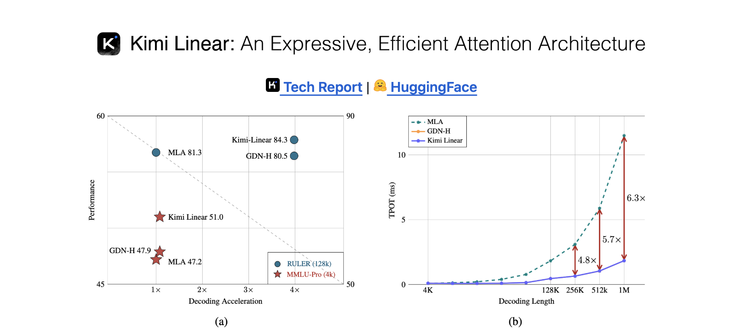
Just 72 hours post-M2 release, Moonshot unveiled Kimi Linear:
- 48B parameters, 3B activation parameters
- Trained on 5.7T tokens
- 1M-token context length
- Fully open-sourced (weights, code, report)
---
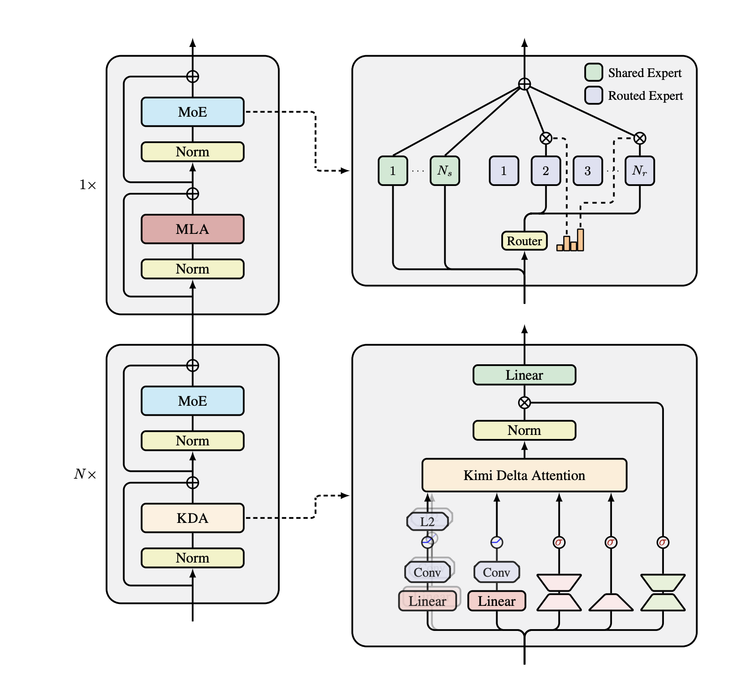
Three Innovations in Kimi Linear
1. Kimi Delta Attention (KDA)
- Builds on Gated DeltaNet
- Upgrades scalar gates → channel-wise gates = more granular forgetting
- Allows different “memory strength” per feature type
- Performance: ~2× computation efficiency vs. DPLR
---
2. 3:1 Hybrid Ratio: KDA + MLA
- MLA compresses attention into low-dimension, expands only when needed
- Ratio testing found optimum at 3 KDA layers : 1 MLA layer
Results:
- 0:1 MLA → PPL = 5.77
- 3:1 → PPL = 5.65 (best)
- 1:1 → 5.66
- 7:1 → 5.70
- 15:1 → 5.82
---
3. No Position Encoding (NoPE)
- MLA layers skip RoPE; KDA layers handle positional info entirely
- Benefits:
- Higher inference efficiency (MLA → MQA)
- Simplified training
- Better long-context generalization
---
Architecture Overview
Modules: Token Mixing Layer → MoE Channel Mixing Layer (stacked)
---
3. Kimi Linear: Numbers & Proofs
KV Cache Reduction:
- 75% reduction → 4× lower memory cost
Throughput:
- 1M-token context decoding: 6.3× faster vs. MLA
- TPOT drops from 11.48 ms → 1.84 ms
RULER test (128k):
- Score: 84.3
- Speed: 3.98× faster vs. MLA
- Pareto-optimal: no trade-off between speed & quality

---
Scaling Law Validation (1.4T tokens):
- MLA Loss = 2.3092 × C^(−0.0536)
- Kimi Loss = 2.2879 × C^(−0.0527)
- ~1.16× computational efficiency advantage
---
Synthetic Task Testing:
- Palindrome, MQAR, Stack Tracking: KDA = 100% accuracy
- GDN & Mamba2 fail on long sequences
---
vLLM Integration:
- Kimi Delta Attention now in vLLM’s main branch — instant access via upgrade.
---
4. Two Paths: Full vs. Hybrid Attention
MiniMax:
- Full Attention bet
- Assumes GPU cost improvements + safer, proven tech
- Strategy: time for space
Kimi/Moonshot:
- KDA + MLA Hybrid
- Redesign to cut costs + engineer maturity
- Strategy: space for time
Other philosophies:
- DeepSeek: MLA focus
- Mistral: Sliding-window sparse
- OpenAI/Anthropic: Likely optimized Full Attention
---
Industry Impact
These divergent approaches display:
- Open, healthy competition
- No single “right answer” in large-model attention design
The rivalry is both technical — Full vs. Efficient Attention — and market-facing, influencing long-term competitiveness.
---
5. AI Content Ecosystem Tie-In
For developers/creators leveraging these advancements, AiToEarn offers:
- AI-assisted content generation
- One-click publishing to Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, YouTube, X(Twitter), Pinterest, LinkedIn, Threads
- Integrated analytics & AI Model Ranking
Paralleling Kimi’s efficiency goals, AiToEarn maximizes reach while minimizing operational overhead.
---
Bottom Line:
The “battle for attention” — both engineering and business — is far from over. MiniMax and Kimi’s rivalry will likely shape not only technical standards but also the ecosystems around how AI-powered products are delivered and monetized.
In this race, innovation, openness, and practical deployment tools will determine who truly gets your back.