MiniMax-M2 Released! 10B Activations, Built for Efficient Coding and Agent Workflows

# MiniMax-M2: High-Efficiency Open-Source MoE Model for Coding & Agent Tasks
*2025-10-27 18:29 Zhejiang*
MiniMax-M2 is a **highly efficient open-source Mixture-of-Experts (MoE) model** with **230B total parameters** and **only 10B activated at a time**.
It is optimized for **coding** and **agent automation** tasks, delivering leading benchmark performance while enabling **low-cost deployment**.

---
## 0. Preface
Today, Minimax officially **releases and open-sources** **MiniMax-M2**, purpose-built for **max-level coding** and **agentic applications**.
Key advantages:
- **230B total parameters, lightweight 10B activation**
- **Strong general intelligence**, deeply optimized for code & agent workflows
- **Compact & scalable** design for smooth deployment
---
## 1. Key Highlights
### **1.1 Outstanding General Intelligence**
- Highly competitive performance in **math, science, instruction-following, coding**, and **agent tool usage**
- **Ranks #1 globally** among open-source models in comprehensive benchmarks (Artificial Analysis)
### **1.2 Coding Expertise**
- Handles **multi-file coding projects** end-to-end
- Supports the full “code → run → debug → fix” cycle
- **Top scores** on **Terminal-Bench** & **(Multi-)SWE-Bench**
- Proven effectiveness in **production development environments**
### **1.3 Agentic Capabilities**
- Plans & executes complex **toolchains** including Shell, browsers, Python environments, MCP tools
- **BrowseComp benchmark**: excels in discovering obscure info sources while keeping results **traceable**
- Demonstrates **self-correction** & **fault recovery**
### **1.4 Efficient Design**
- **10B active parameters** → **lower latency**, **cost savings**, higher throughput
- Designed for **multi-agent workflows** & **rapid collaboration**
- Perfect for the rising demand for **deployable coding & agent solutions**
---
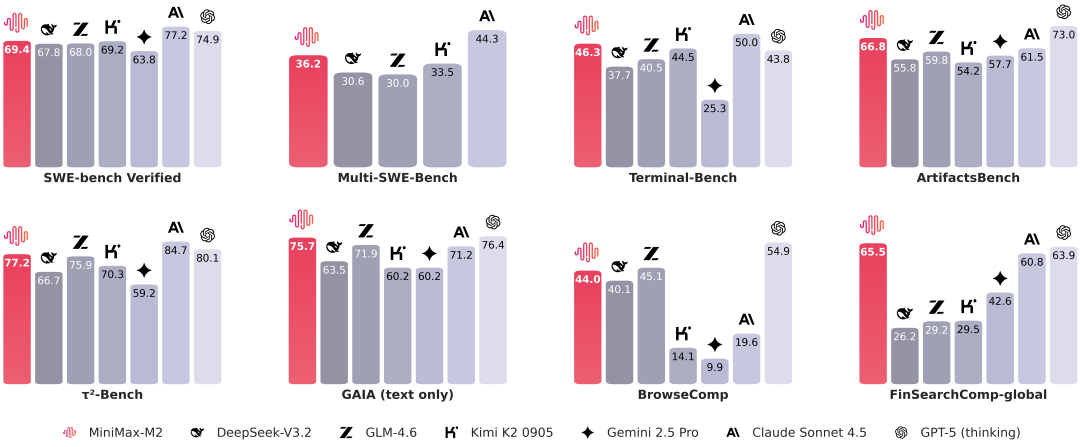
## 2. Benchmark Overview
MiniMax-M2 achieves **state-of-the-art** performance in key developer-aligned benchmarks:
- **SWE-bench**, **Terminal-Bench**, **BrowseComp**, **HLE w/tools**, **FinSearchComp-global**
- Simulates daily work in terminals, IDEs, & CI environments
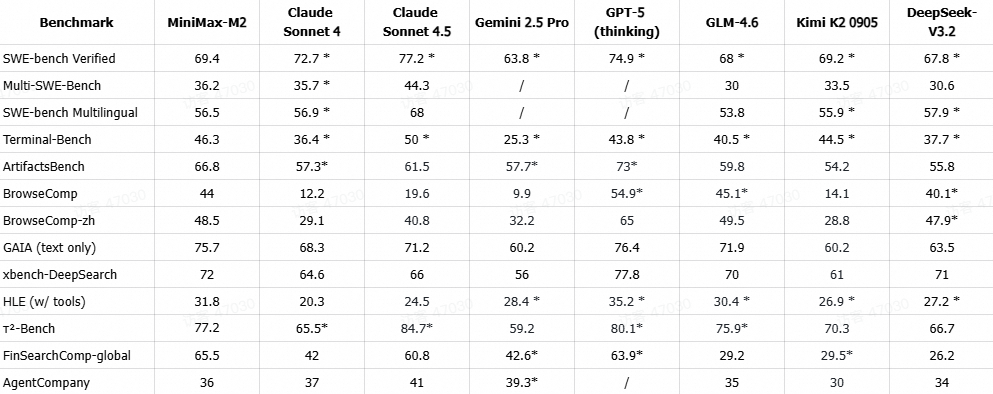
### **Evaluation Process**
Metrics marked with * came from **official reports**. Others were tested via:
- **SWE-bench Verified**:
- Based on **OpenHands**
- Test setup: 128k context, max 100 steps, no test-time scaling
- Git content removed → agent sees only relevant faulty code segment
- **Multi-SWE-Bench & SWE-bench Multilingual**:
- Using `claude-code` CLI tool (max 300 steps)
- Tested 8 times, averaged
- **Terminal-Bench**:
- `claude-code` from official repo (commit 94bf692)
- 8 repeated tests, averaged
- **ArtifactsBench**:
- Official implementation
- Evaluation model: Gemini-2.5-Pro
- Averaged over 3 runs
- **BrowseComp, BrowseComp-zh, GAIA (text only), xbench-DeepSearch**:
- Same framework as WebExplorer (Liu et al., 2025)
- GAIA subset identical to WebExplorer’s
- **HLE (w/ tools)**:
- Search tool + Python (Jupyter) environment
- Pure-text subset benchmark
- **τ²-Bench**:
- "Extended thinking w/tool use" mode
- GPT-4.1 as user simulator
- **FinSearchComp-global**:
- GPT-5-Thinking, Gemini-2.5-Pro, Kimi-K2 → official scores
- Others tested via open-source framework with search & Python
- **AgentCompany**:
- OpenHands 0.42 agent framework for scoring
---
### **Artificial Analysis Global Ranking**
**MiniMax-M2** ranked **#1 worldwide** among open-source models in:
- Mathematics
- Science
- Programming & coding
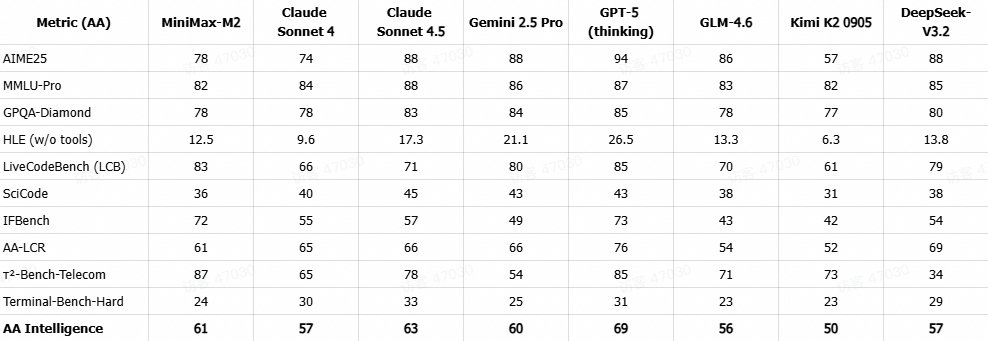
> Source: Official Artificial Analysis ([https://artificialanalysis.ai/](https://artificialanalysis.ai/))
---
## 3. Why 10B Activation is Optimal for Agents
**10B active parameters** deliver an ideal balance for modern **Plan → Act → Verify** agent workflows:
- ✅ **Faster feedback loops** for cycles like “edit → run → test” and “search → browse → cite”
- ✅ **Higher cost efficiency**, enabling more concurrent tasks per budget
- ✅ **Simpler resource planning** with smaller memory use per request
---
## 4. Model Usage
### **4.1 Try MiniMax Agent**
- [MiniMax Agent product](https://agent.minimaxi.com/) → **Free for limited time**
### **4.2 Use via API**
- [MiniMax Open Platform](https://platform.minimaxi.com/docs/guides/text-generation) → **Free for limited time**
### **4.3 Deploy Locally**
- Model weights: [ModelScope](https://modelscope.cn/models/MiniMax/MiniMax-M2)
---
## 5. Model Inference with ms-swift
### **Installation** uv pip install 'triton-kernels @ git+https://github.com/triton-lang/triton.git@v3.5.0#subdirectory=python/triton_kernels' \
vllm --extra-index-url https://wheels.vllm.ai/nightly --prerelease=allow
pip install git+https://github.com/modelscope/ms-swift.git
### **Run Inference** CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift infer \
--model MiniMax/MiniMax-M2 \
--vllm_max_model_len 8192 \
--vllm_enable_expert_parallel \
--vllm_tensor_parallel_size 4 \
--infer_backend vllm
**Recommended parameters**: temperature = 1.0
top_p = 0.95
top_k = 40
---
## 6. Summary
If you need **flagship coding & agent features** without the pain of high costs or complex deployment:
**MiniMax-M2** provides **top-tier performance**, fast execution, and flexible deployment.
For creators seeking cross-platform monetization of AI content, platforms like [AiToEarn官网](https://aitoearn.ai/) integrate:
- AI content generation
- Cross-platform publishing
- Analytics
- Model competition ranking
Publish simultaneously to: **Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X**.
---
**🔗 Links:**
- [Read Original](https://modelscope.cn/models/MiniMax/MiniMax-M2)
- [Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=1e1edd5a&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzk3NTc1NTU0Mw%3D%3D%26mid%3D2247501773%26idx%3D1%26sn%3D591b8d9f2fbaabf3cc9a6cf44366e3e5)

