Model Express in ModelScope Community (Nov 23–29)


# 🙋 ModelScope Community Progress Update
## 📊 This Week at ModelScope
- **Models:** 3322 total — *Z-Image-Turbo*, *HunyuanOCR*, *FLUX.2-dev*, *DeepSeekMath-V2*, *Spark-Prover-X1-7B*, etc.
- **Datasets:** 427 total — *LET Full-size humanoid robot dataset*, *dolma3_longmino_pool*, *Latin-Audio*, etc.
- **Innovative Applications:** 113 total — *Z-Image-Turbo*, *Financial Deep Research*, etc.
- **Articles Published:** 7 total
---
## 📝 Community Articles This Week
- **LET Dataset Lands on ModelScope** — First open-source batch with over 60,000 minutes of full-size humanoid robot data
- **Z-Image** — Next-generation image generation model pushing the experience limits
- **ByteDance VeAgentBench + veADK** — New paradigm for intelligent agent development
- **Hangzhou AI Open Source Ecosystem Conference Recap**
- **Hunyuan OCR Model Goes Open Source** — Only 1B parameters, multiple SOTA capabilities
- **Finalist Announcement** — 800 developers demonstrate impactful AI projects
- **New LLM Interaction Mode** — Models can autonomously create interactive UIs
---
# 01. Model Recommendations
## ### Z-Image Series Overview
**Z-Image** is an advanced, efficient image generation model series from Alibaba's Tongyi Lab with **6B parameters**.
### Variants
- **Z-Image-Turbo:** Optimized for speed and stability; competitive with leading models using just 8 NFEs.
- **Highlights:** Sub-second inference, consumer GPU-ready, photorealistic output, bilingual text rendering, strong instruction-following.
- **Open Source:** [Model link](https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo)
- **Z-Image-Base:** Standard version, ideal for fine-tuning and custom development.
- **Z-Image-Edit:** Specialized for image-to-image editing via natural language.
---
### How to Try Z-Image
**Option 1 — ModelScope AIGC Zone**
Go to the [Image Generation Zone](https://modelscope.cn/aigc/imageGeneration) — *Z-Image* is the default model.
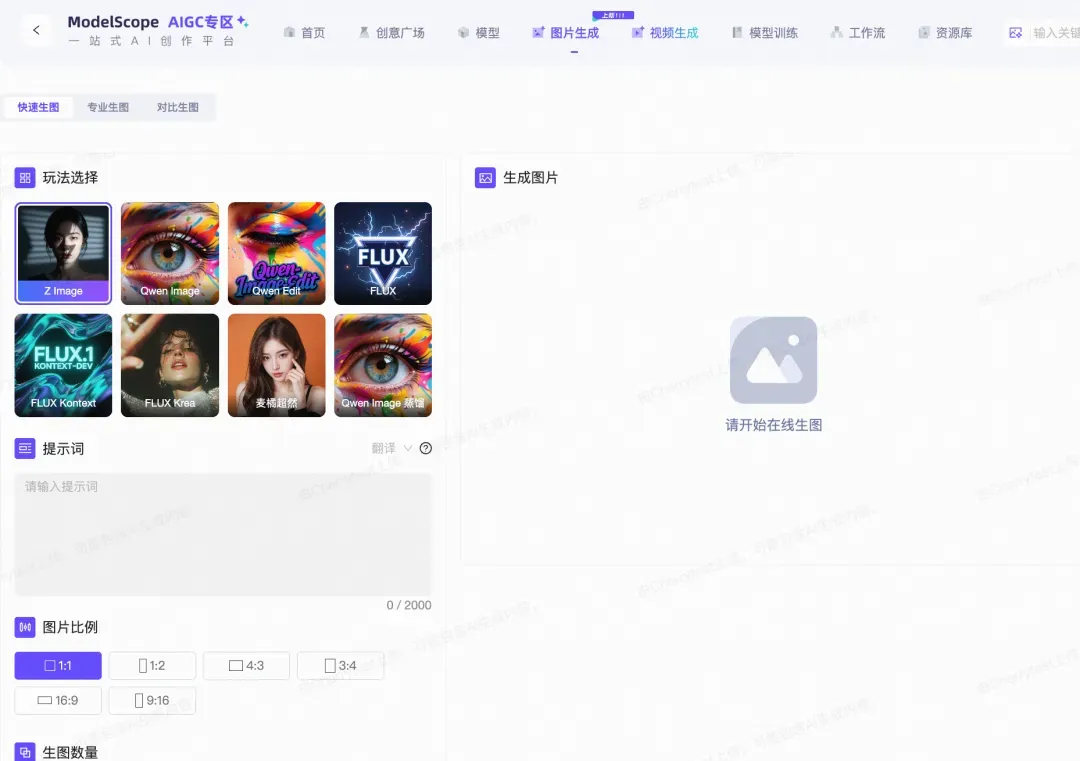
**Option 2 — API Inference**
Use the “Inference API” directly from the model page to get a ready-to-run Python script.
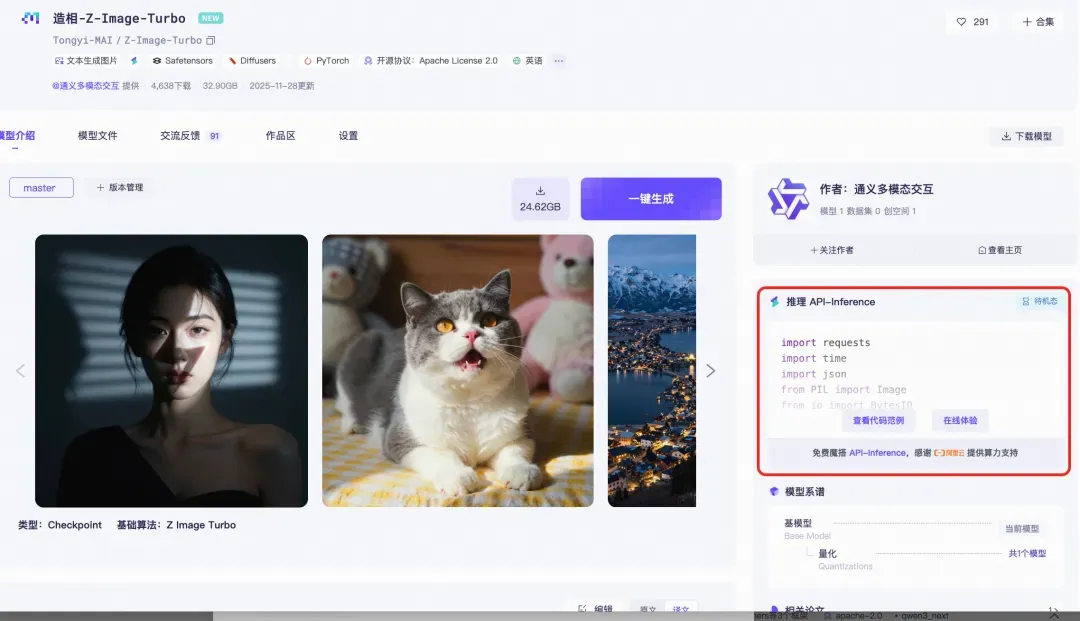
---
## ### HunyuanOCR Overview
**HunyuanOCR** — Tencent's leading end-to-end OCR VLM with 1B parameters and SOTA benchmarks.
**Strengths:**
- Complex multi-language document parsing
- Text recognition
- Open-domain information extraction
- Video subtitle parsing
- Image translation
**Model Link:** [https://modelscope.cn/models/Tencent-Hunyuan/HunyuanOCR](https://modelscope.cn/models/Tencent-Hunyuan/HunyuanOCR)
---
### Quick Start with Transformers
#### Installpip install git+https://github.com/huggingface/transformers@82a06db03535c49aa987719ed0746a76093b1ec4
#### Inference Examplefrom modelscope import AutoProcessor
from modelscope import HunYuanVLForConditionalGeneration
from PIL import Image
import torch
... full code here ...
---
## ### FLUX.2-dev Overview
**Black Forest Labs** released **FLUX.2**, a 32B *Flow Matching* Transformer for highly realistic images.
**Highlights:**
- Control over colors, poses, composition
- Multi-image reference editing (up to 10 sources)
- Efficient with guidance distillation
**Model Link:** [https://modelscope.cn/models/black-forest-labs/FLUX.2-dev](https://modelscope.cn/models/black-forest-labs/FLUX.2-dev)
#### Inference Pipeline Exampleimport torch
from modelscope import Flux2Pipeline
... full code ...
---
# 02. Dataset Recommendations
## ### LET Full-size Humanoid Robot Dataset
- Multi-view, multi-modal real-world data from Kuavo 4 Pro robot
- Covers 31 sub-task scenarios, 117 atomic skills, 1000+ hours
- Expert annotated, high quality
**Dataset Link:** [https://modelscope.cn/datasets/lejurobot/let_dataset](https://modelscope.cn/datasets/lejurobot/let_dataset)
---
## ### Dolma3 Longmino Pool
- Large-scale, high-quality text pre-training dataset by AI2
- For LLM training, NLU, and text generation research
**Dataset Link:** [https://modelscope.cn/datasets/allenai/dolma3_longmino_pool](https://modelscope.cn/datasets/allenai/dolma3_longmino_pool)
---
## ### Vox Classica (Latin Audio)
- ~73 hours classical Latin speech, segmented per sentence
- Designed for ML applications; fills gap in Latin audio datasets
**Dataset Link:** [https://modelscope.cn/datasets/AI-ModelScope/Latin-Audio](https://modelscope.cn/datasets/AI-ModelScope/Latin-Audio)
---
# 03. Creative Space Applications
## **Z-Image-Gallery**
- Image generation & gallery based on ModelScope
- For creative design, content creation, or AI teaching
**Experience Link:** [https://modelscope.cn/studios/Tongyi-MAI/Z-Image-Gallery](https://modelscope.cn/studios/Tongyi-MAI/Z-Image-Gallery)
---
## **FinResearch**
- Financial data analysis, report generation, strategy modeling
- Tailored for professionals in finance
**Experience Link:** [https://modelscope.cn/studios/ms-agent/FinResearch](https://modelscope.cn/studios/ms-agent/FinResearch)
---
# 04. Community-Selected Articles
1. [LET Dataset Open Source Announcement](https://mp.weixin.qq.com/s?__biz=Mzk3NTc1NTU0Mw==&mid=2247502784&idx=1&sn=c4cd17bc63f5266973e5673e5a6f9bba&scene=21#wechat_redirect)
2. [Z-Image Next-Gen Overview](https://mp.weixin.qq.com/s?__biz=Mzk3NTc1NTU0Mw==&mid=2247502771&idx=1&sn=977a31245dd14a968a1175681d72aa1c&scene=21#wechat_redirect)
3. [ByteDance VeAgentBench Introduction](https://mp.weixin.qq.com/s?__biz=Mzk3NTc1NTU0Mw==&mid=2247502690&idx=1&sn=1af80d079bf520de25aed3ffb993cb52&scene=21#wechat_redirect)
4. [Hangzhou AI Conference Recap](https://mp.weixin.qq.com/s?__biz=Mzk3NTc1NTU0Mw==&mid=2247502636&idx=1&sn=464f3c2232421f7ee9cfce1d99adfb4f&scene=21#wechat_redirect)
5. [Hunyuan OCR Open Source Achievements](https://mp.weixin.qq.com/s?__biz=Mzk3NTc1NTU0Mw==&mid=2247502657&idx=1&sn=81f4a7251540a32b57530f34a1db70ef&scene=21#wechat_redirect)
6. [800 AI Project Finalists](https://mp.weixin.qq.com/s?__biz=Mzk3NTc1NTU0Mw==&mid=2247502349&idx=1&sn=39ccbba875d177c7b68d868593b13910&scene=21#wechat_redirect)
7. [New LLM Interactive UI Mode](https://mp.weixin.qq.com/s?__biz=Mzk3NTc1NTU0Mw==&mid=2247502349&idx=2&sn=86c5f8546831ebaed8c2efe364b3182f&scene=21#wechat_redirect)
---
**💡 Pro Tip:** Pair these cutting-edge models and datasets with an open-source monetization platform like **[AiToEarn](https://aitoearn.ai/)** to publish across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter), and integrate analytics & AI model rankings into your creative workflow.

