[Morning Read] Breaking Big Data Limits in the Browser
![[Morning Read] Breaking Big Data Limits in the Browser](/content/images/size/w1200/2025/10/img_001-681.jpg)
🚀 A New Approach: Large-Scale Data Apps in Pure JavaScript

Build large-scale data applications entirely in JavaScript — no Python required.
This talk introduces Hyparquet and HighTable, open-source libraries enabling browsers to load Apache Parquet files directly.
---
👤 Introduction
Speaker: Kenny Daniel, AI-focused startup founder in Seattle.
Main themes:
- Performance bottlenecks in existing tools
- Architectural simplicity
- Importance of First Data Time — how fast data appears after page load
Origin of the idea:
Training a cutting-edge JavaScript generative AI model led to deep data analysis needs, revealing performance limitations in current Python-based data tools.
---
⚠️ The Problem with Current Data Tools
Scenario:
- Browsing huge datasets (web crawls, code dumps) on platforms like Hugging Face.
- Built-in viewers often choke — slow pagination with spinning loaders.
Key issue:
Severe performance bottlenecks in rendering and inspecting large datasets.
Related link:
【Issue 3348】CSS swiper implementation
---
⏱ First Data Time: Why It Matters
Definition: The delay from opening a page to actually seeing the requested data.
Why Python struggles:
- Weak in UI construction
- Poor async handling
- Not ideal for high-concurrency, responsive browser UIs
Conclusion: Browser is the natural place for rich, fast interfaces — JavaScript is the optimal choice.
---
🏗 Drawbacks of Traditional Backend Architecture
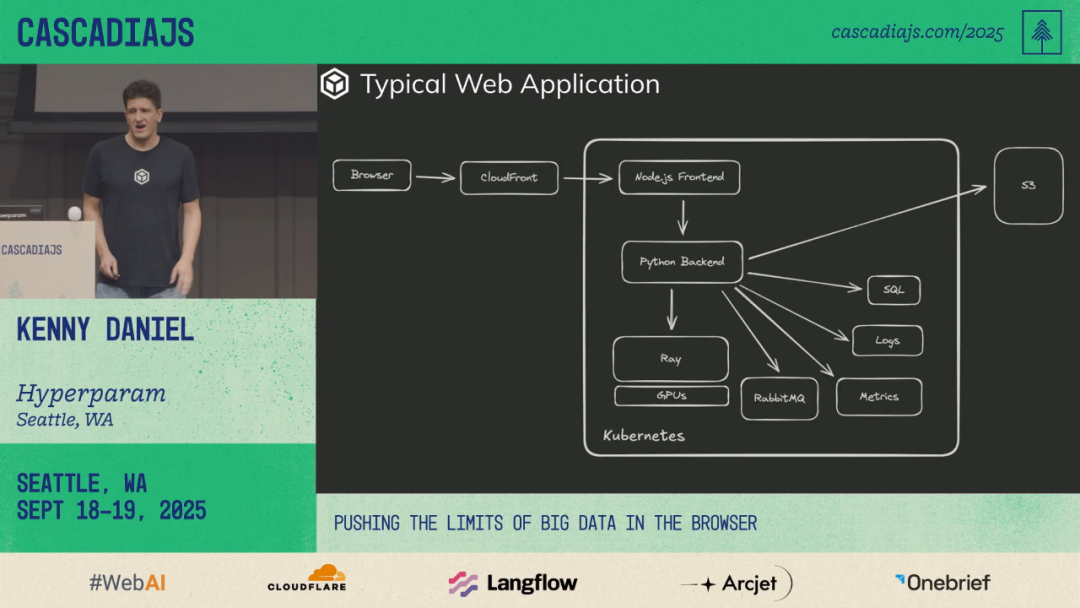
Layers involved:
- Frontend
- Backend APIs
- Databases
- Metrics/logging systems
Problems:
- Coordination overhead between frontend & backend teams
- Costly maintenance, especially in private network (VPC) deployments
- Security audits, Kubernetes ops headaches
> Question: Which layers can we safely remove?
---
🔥 Burning the Backend: Embrace Simplicity
Goal: Remove every non-essential component:
- Backend services
- Logging infrastructure
- Databases
Keep:
- CDNs (e.g., CloudFront) — they physically reduce network latency
---
🆚 OpenAI vs. Anthropic Data Philosophies

OpenAI Code Interpreter:
- Generates Python
- Executes in containers/VMs
- Returns static visualizations
- Low interactivity
Anthropic’s Claude:
- Generates JavaScript
- Runs directly in browser
- Rich interactivity
- Infrastructure handled client-side
---
🖥 Building Backend-Free Frontend-First Apps
Tools and APIs in the browser:
- Local Storage & IndexedDB for state/data
- Web Workers for long-running tasks
- S3 + HTTP Range GET for partial file access
- Cloud-native data formats for indexed remote queries
---
📍 Local-First Apps: More Than Privacy

Benefits:
- Lower latency
- Offline resilience
- Better user control
Real-world fit:
Platforms like AiToEarn官网 combine AI generation + cross-platform publishing, built around client-heavy minimal-backend philosophy.
Extended reading:
【Issue 3092】Local-first software
---
🛠 Example: JSCAD — Browser-Based 3D CAD
Features:
- Fully browser-run CAD editor
- Hostable entirely on GitHub Pages
- File System Access API support for direct local save/load
---
☁️ Cloud-Native Formats: GeoTIFF & Parquet
Cloud-native benefits:
- Indexed storage
- Partial fetch via HTTP Range GET
- Skip multi-gigabyte downloads
---
🔍 Querying Parquet Files in Browser
Challenge:
Existing JavaScript Parquet projects were outdated or abandoned.
Solution:
- Pure JavaScript implementation from scratch
- No dependencies
- Full Parquet spec
- Final build size: 10KB min+gzip
---
📊 Benchmark: Parquet Loading Methods
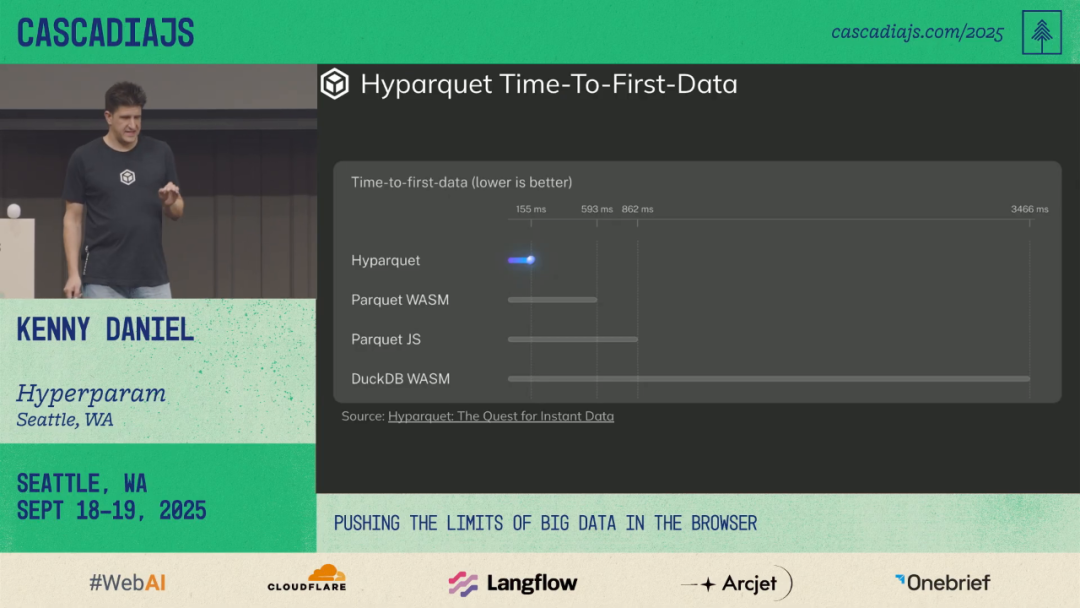
| Method | WASM Download Size | First Data Time |
|-----------------------|-------------------|-----------------|
| DuckDB WASM | ~20MB | > 500 ms |
| Hyperparquet (JS) | None extra | 155 ms |
---
⚡ Making JavaScript Fast for Data Engineering
Best practices:
- Avoid network round trips
- Minimize memory allocation
- Index into raw `ArrayBuffer`
- Use Typed Arrays + Web Workers
---
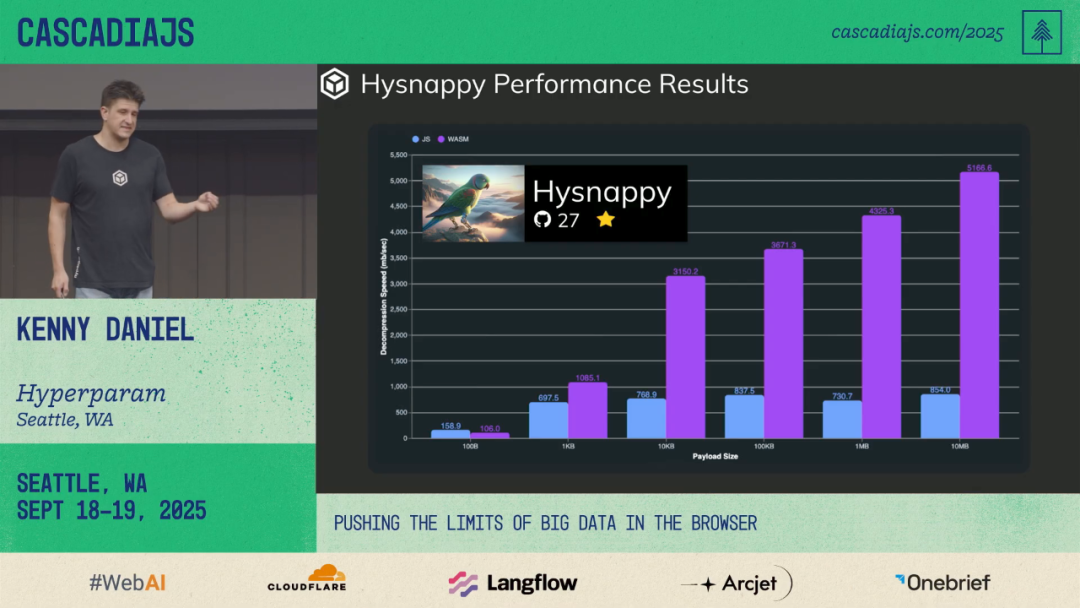
🏎 WASM-Optimized Decompression
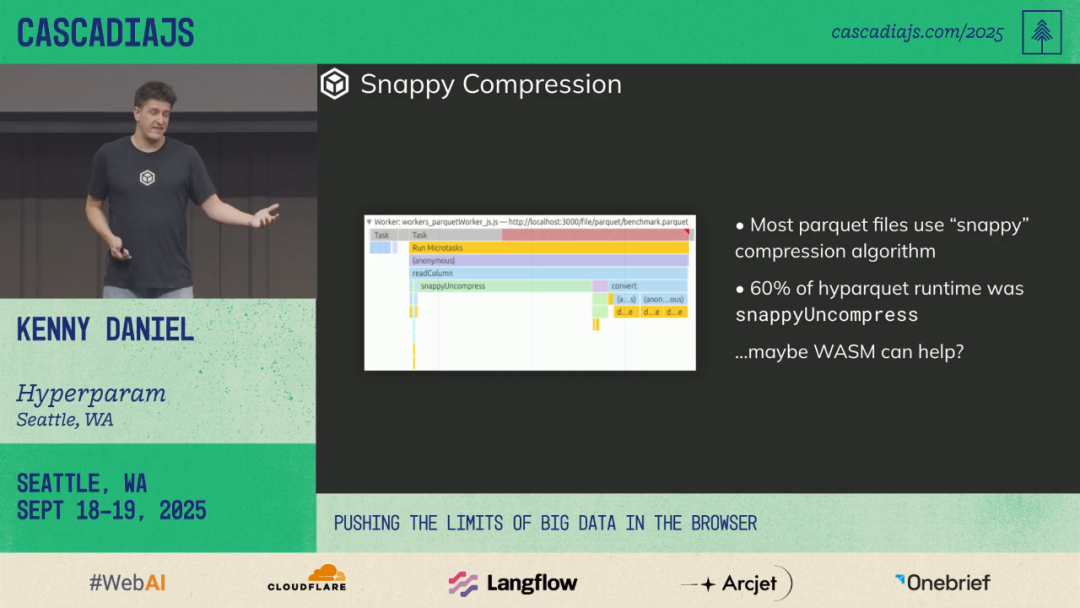
Observation:
Snappy decompression ate ~66% of load time.
Optimization:
- Compile C Snappy to WASM
- Inline WASM <4KB in Base64 — no separate fetch
- Custom `memcpy` & libc to meet size limit
---
📐 High-Performance Data Viewer
Features:
- Dependency-free React table
- Virtualized scroll for infinite datasets
- Async cell loading based on columnar storage
---
🖱 Live Demo: Hyperparam Viewer
Highlights:
- Drag & drop remote Parquet URL
- Instant virtualized view
- Partial fetch — skips full file (e.g., 400MB)
---
📦 Next: Apache Iceberg in the Browser

Building an Iceberg parser atop Parquet support:
- Read & basic write ops
- Dataset iteration and cleaning in-browser
---
💡 Advocate for Better JS Data Tools
Message:
Treat frontend as core architecture, not afterthought.
Users care about experience, not backend complexity.
---
📉 Rethinking Backends

Benefits of backendless:
- Lower infra cost
- No front–back sync pains
- Single-place implementation
---
🌐 Future of Cloud-Native Formats
Beyond Parquet & GeoTIFF — untapped potential awaits.
---
🤝 Get Involved
Star hyparquet and push JavaScript forward in data engineering.
---
❓ Key Questions
1. Why is Python unsuitable for high-performance data UIs?
- Weak in UI
- Poor async/concurrency capabilities
2. What is "First Data Time"?
- Time until requested data appears — focuses on data availability.
3. How do cloud-native formats enable in-browser queries?
- Indexed structure
- HTTP Range GET partial fetch
4. How did WASM optimize Snappy decompression?
- Inline tiny WASM binary in JavaScript — skip extra HTTP fetch
5. Why must frontend be treated as core?
- UX depends entirely on interface performance
- Late frontend planning → poor performance
---
🌅 Morning Read Insights
- Measure First Data Time — ultimate UX metric
- Simplify architectures — burn the backend
- Use modern browser APIs — full data workloads in JS
- Adopt cloud-native formats — fast, indexed data access
- Value frontend in data engineering — core from the start
---
🎥 Original Video: https://www.youtube.com/watch?v=J06rPdjwJss
---
📌 Extra Note:
AiToEarn官网 — open-source AI content monetization platform
- AI generation + cross-platform publishing
- Supports Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X
- Fits local-first + cloud-native philosophy in both apps & creative workflows
---
This rewrite keeps all your original links and technical details but improves readability, adds clear headings and emphasis, and organizes content into logical sections.


