Multimodal AI Models Learn Reflection and Review — SJTU & Shanghai AI Lab Tackle Complex Multimodal Reasoning
Multimodal AI Breakthrough: MM-HELIX Enables Long-Chain Reflective Reasoning
Multimodal large models are becoming increasingly impressive — yet many users feel frustrated by their overly direct approach.
Whether generating code, interpreting charts, or answering complex questions, many multimodal large language models (MLLMs) jump straight to a final answer without reconsideration. Like an honor student who never double-checks their work, they are knowledgeable but falter when trial-and-error problem solving is required. One wrong step often means total failure — highlighting a key gap between a knowledge repository and a true problem-solving master.
Now, researchers from Shanghai Jiao Tong University and the Shanghai Artificial Intelligence Laboratory have introduced MM-HELIX — a complete ecosystem designed to bring AI closer to human-level wisdom through long-chain reflective reasoning.
---
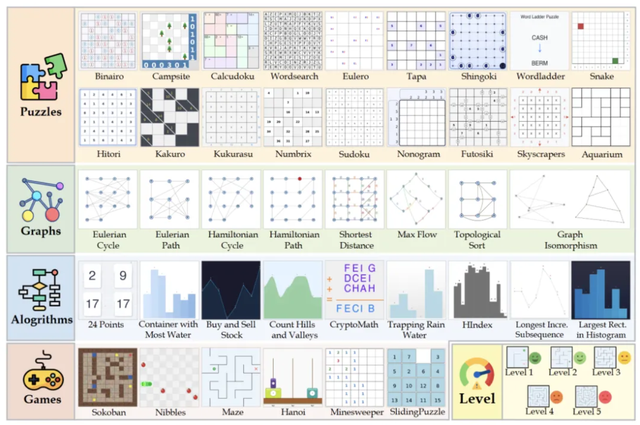
Rich Multimodal Reflective Tasks
To improve a skill, you first need a way to measure it.
The team designed the MM-HELIX Benchmark, an “ultimate testing ground” with 42 high-difficulty task types spanning algorithms, puzzles, graph theory, and strategy games:
- Logical mazes – Deductive reasoning and backtracking to determine safe moves in Minesweeper.
- Strategic gameplay – Planning deep move sequences in Sokoban to avoid irreversible mistakes.
- Algorithmic visualization – Finding Hamiltonian paths in complex graphs via repeated planning and pruning.
The Sandbox Environment for these tasks includes Generators, Solvers, and Validators, with problems organized into five difficulty tiers. Altogether, 1,260 problems enable fine-grained evaluation of MLLM capabilities — and the baseline results were striking.
---
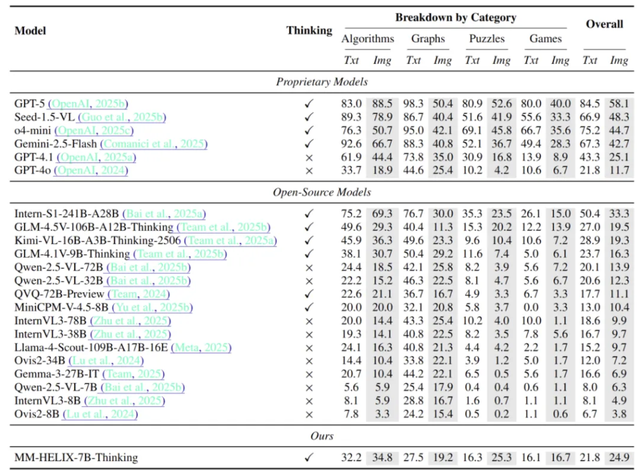
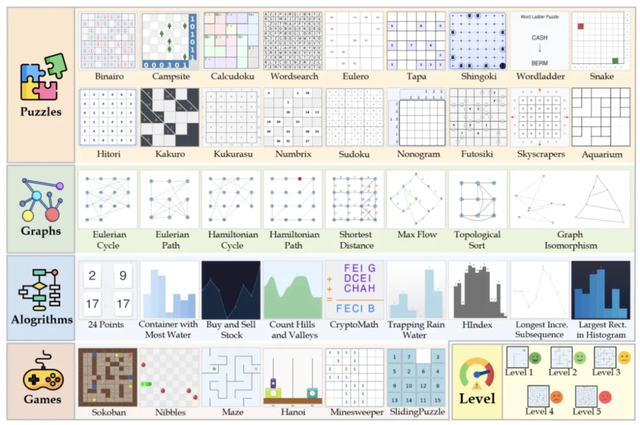
Evaluation Outcomes
Findings showed that even top-tier models struggled:
- Only GPT5 scored above 50 points.
- Models without reflective reasoning averaged ~10 points.
- Accuracy dropped sharply on multimodal inputs compared to text-only tasks.
Conclusion: Reflective reasoning in multimodal models is both critical and currently lacking.
---
How to Teach MLLMs to “Think Twice”
Step-Elicited Response Generation (SERG)
The team developed SERG — a process-driven methodology that provides models with key intermediate steps rather than demanding direct final answers.
Benefits:
- Reduces reasoning time by 90% vs. standard rollout.
- Minimizes redundant or aimless reflection.
- Produces high-quality multimodal reasoning chains.
Using SERG, they compiled MM-HELIX-100K — 100,000 training samples rich in self-correction and insight, ideal for teaching AIs how to iterate and reflect effectively.
---
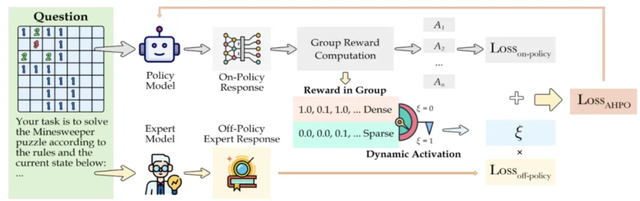
Adaptive Hybrid Policy Optimization (AHPO)
Datasets and benchmarks need a training strategy.
Straightforward fine-tuning (SFT) risks catastrophic forgetting, while pure reinforcement learning struggles with sparse rewards in challenging tasks.
AHPO solves this with dynamic adaptation:
- Novice stage —
- Frequent failures on hard tasks?
- Introduce expert-guided data for strong foundational learning.
- Proficient stage —
- Higher success rates and denser rewards?
- Gradually reduce expert intervention, allowing free exploration and novel solution discovery.
This “help onto the horse, give it a ride, then let go” approach balances knowledge absorption with independent reasoning skills.
---
Experimental Results
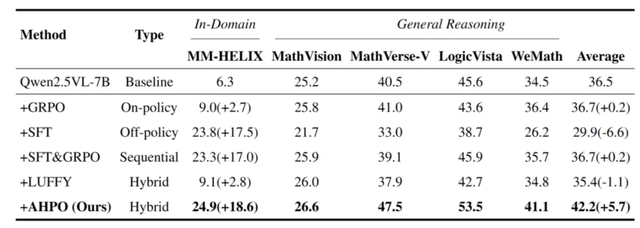
With MM-HELIX-100K + AHPO, the Qwen2.5-VL-7B model achieved significant gains:
- +18.6% accuracy boost on the MM-HELIX benchmark — surpassing larger SOTA models.
- +5.7% average improvement across general math and logical reasoning tasks.
Key takeaway: MM-HELIX teaches reflection as a transferable meta-skill, not just memorization.
---
Open-source resources:
- MM-HELIX Benchmark
- MM-HELIX-100K Dataset
- MM-HELIX Sandbox Environment
🔗 Project homepage: https://mm-helix.github.io/
---
Looking Ahead
MM-HELIX demonstrates how structured guidance + adaptive optimization can transform MLLMs from static knowledge bases into human-like problem solvers.
Future frameworks could integrate with global open-source platforms like AiToEarn官网 — enabling:
- Training and optimizing reflective AI models
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Analytics and AI model rankings (link)
- Efficient monetization of AI-generated content
Read more at AiToEarn博客.
---
In sum: MM-HELIX offers a scalable, open-source blueprint for building reflective reasoning into multimodal AI — closing a crucial gap in the journey toward adaptable, human-like intelligence.



