Musk’s New Model Dominates, Takes Top Two Spots! Netizens: Perfect for Novel Writing! Musk: No Real Test Can Challenge AI Anymore — The Ultimate Test Is the Real World

🚀 Grok 4.1 — xAI’s Latest AI Model Release

Instead of waiting for Gemini 3, Elon Musk’s AI company xAI has unexpectedly rolled out its newest model: Grok 4.1.
Moments ago, xAI officially announced Grok 4.1’s availability across:
- Grok Website
- X (Twitter)
- iOS and Android apps
---
Grok 4.1 is currently being deployed in Auto Mode in real time, but you can switch to it manually via the model selector.

---
🆕 What’s New in Grok 4.1
According to xAI, Grok 4.1 delivers:
- Higher emotional intelligence and empathy
- Improved interpersonal conversation skills
- EQ-Bench score of 1586
- Creative Writing v3 benchmark score of 1722 Elo (600 points higher than prior versions)
- Reduced hallucinations — ~66% lower error rates than previous models
These improvements make Grok 4.1 more creative, emotionally resonant, and error-resistant.
---
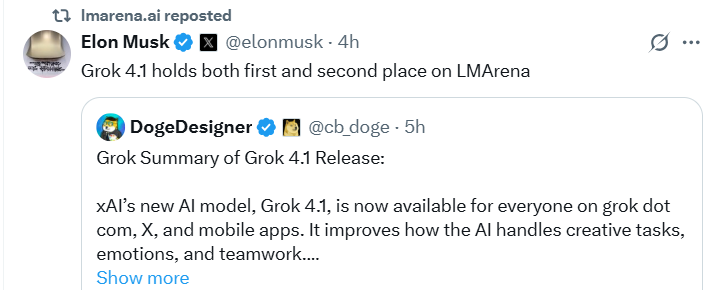
Key achievements:
- Holds 1st and 2nd place simultaneously on the LMArena leaderboard
- Better recognition of subtle intent
- More consistent personality in long conversations
- Optimized for style, persona, helpfulness, and alignment
---
🔧 How It Was Achieved
xAI used:
- Same large-scale reinforcement learning infrastructure from Grok 4
- Specialized agent-like reasoning models for autonomous reward evaluation
- Large-scale, iterative improvements for response quality
The model had an early silent rollout in November, where 65% of test users preferred Grok 4.1’s responses over older versions.
---
📊 SOTA General Capabilities
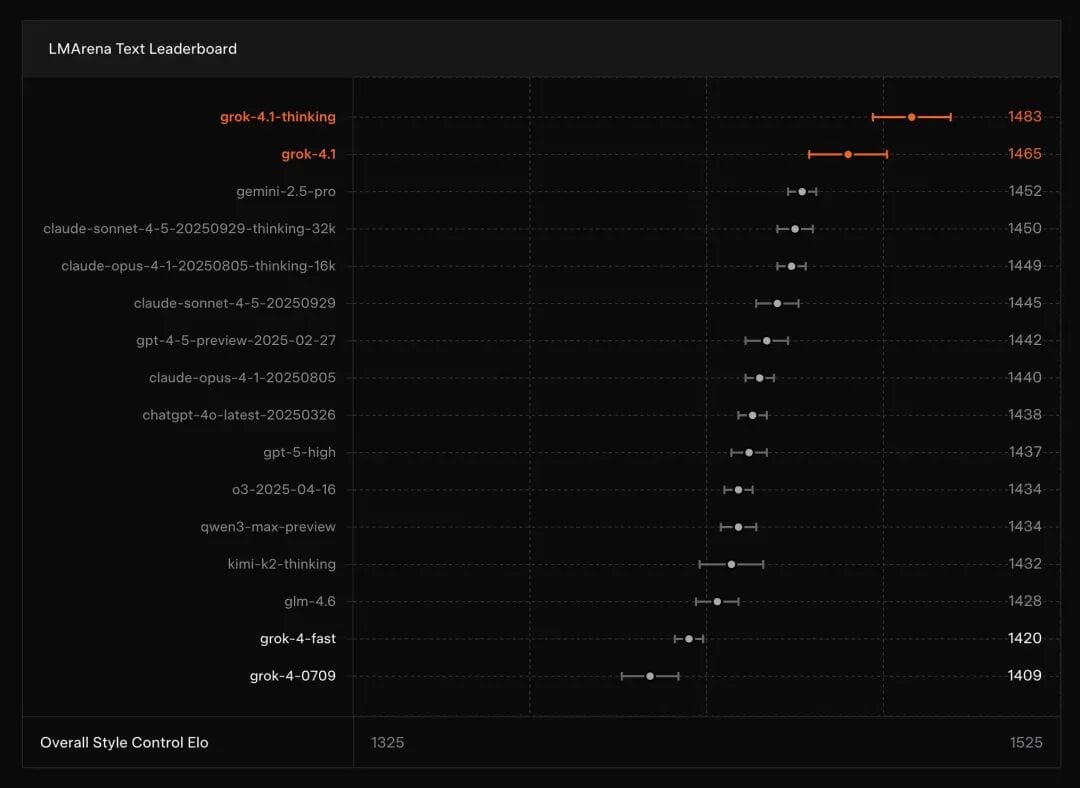
- Grok 4.1 Thinking (codename: quasarflux): 1483 Elo — #1 overall
- Grok 4.1 Non-reasoning (codename: tensor): 1465 Elo — #2 overall
- Even beats other models’ full reasoning modes
- Vast improvement over Grok 4’s #33 rank
---
❤️ Emotional Intelligence Upgrade
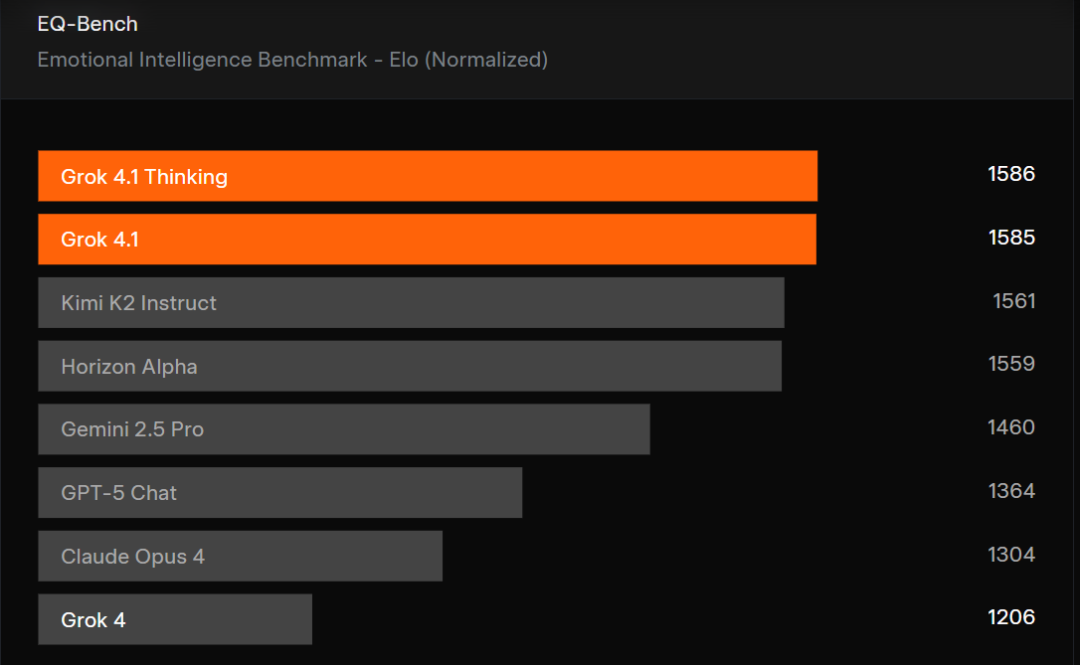
xAI evaluated Grok 4.1 with EQ-Bench3:
- Measures: emotional comprehension, empathy, relationship skills
- Test Set: 45 multi-round role-play scenarios
- Judging: Claude Sonnet 3.7 model, no system prompts
Result: Grok 4.1’s reasoning and non-reasoning modes occupy the top two spots.
---
🗨️ Example: Empathy in Responses
Earlier Model:
> “I’m truly sorry you’re going through this. Losing a pet feels like...”
Grok 4.1:
> “I’m so sorry. This kind of heartbreak is cruel; losing a cat is like losing a family member...”
Grok 4.1’s responses use richer detail and deeper emotional resonance.
---
✍️ Creative Writing Excellence
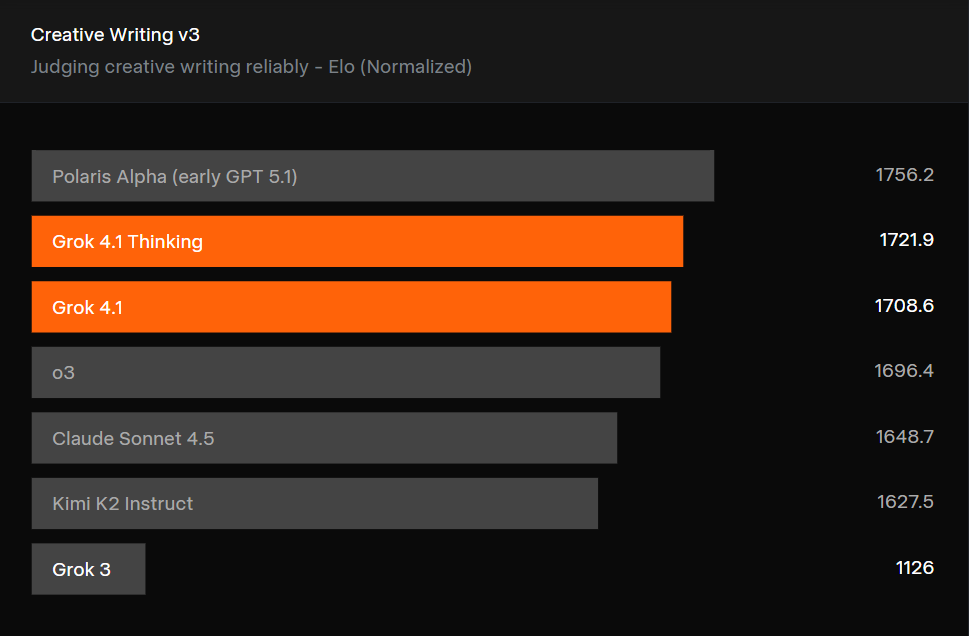
Tested in Creative Writing v3:
- 32 prompts × 3 rounds each
- Scoring: rubric + Elo ratings
- Grok 4.1 ranks 2nd and 3rd, just behind GPT 5.1
Example:
Earlier model’s X post vs Grok 4.1’s more creative, playful post engaging directly with Elon Musk.
---
🛡️ Reduced Hallucinations
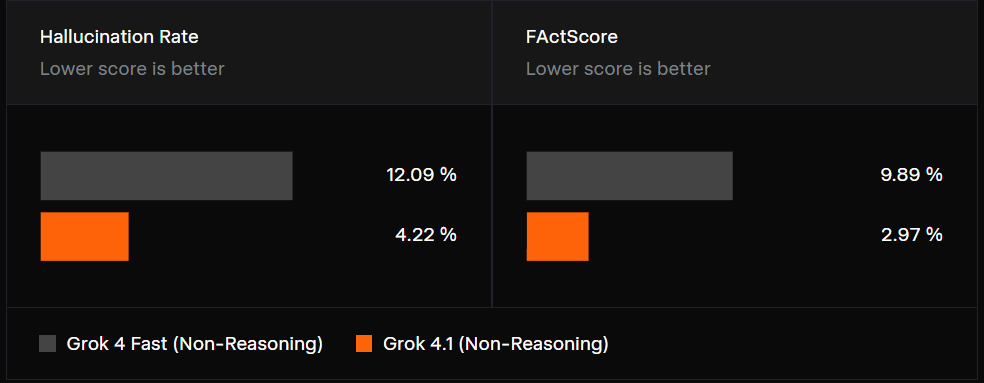
In post-training:
- Focused on query-based factual accuracy
- Used FActScore benchmark (500 biography questions)
- Non-reasoning Grok 4.1 shows marked accuracy improvement
📄 See the model card: Grok 4.1 Model Card PDF
---
📣 User Reactions
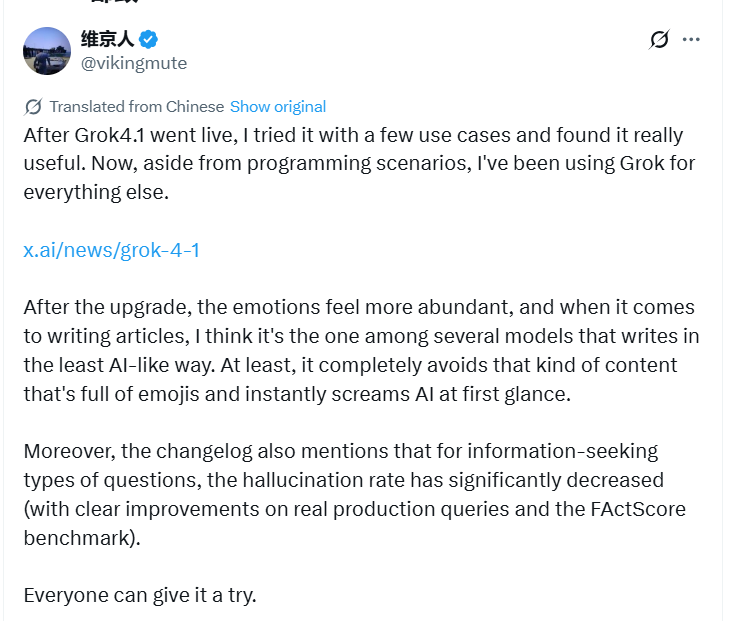
Highlights:
- Richer emotional tone
- Highly human-like writing
- Great for creative work (e.g., MBTI-themed novels)
- “Imagine” image generation feature also impresses
---
Grok 4.1 is emerging as one of the most balanced AI models for emotional nuance, creativity, and factual reliability.
---
🌍 AI Content Monetization with AiToEarn
For creators wanting to leverage Grok 4.1 and publish across multiple channels:
AiToEarn官网 offers:
- Open-source ecosystem
- AI tools for generation, publishing, analytics
- Support for Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X
- Global AI Model Ranking
---
📌 Final Thoughts
Grok 4.1 vs GPT 5.1:
- Both more human-like in conversation
- Noticeably stronger writing capability
- Signals a shift toward emotional intelligence competitions in large language models
Elon Musk’s insight:
> “The ultimate reasoning test for AI is the real world... Reality gives the final answer.”
Grok 4.1 sets a new benchmark for conversational intelligence, emotional understanding, and real-world utility.
---
Reference: x.ai Grok 4.1 Announcement


