Must-Read Large Model Inference: 14 Top Papers and 2 Blogs for 2025

The Wave of Large Models Has Shifted from "Can Generate" to "How to Generate Efficiently"
Over the past year, the wave of Large Language Models (LLMs) has moved from the shallow waters of “capable of generating” into the deep waters of “how to generate efficiently.” Inference efficiency is no longer a peripheral concern for LLM deployment — it has become a core battleground spanning the algorithm, system, and hardware stack. From vLLM paged attention to adaptive speculative decoding, Prefilling/Decoding separation, large-scale expert parallelism, KV cache compression, and cross-node transmission — each innovation is reshaping the limits of computational efficiency.
This post consolidates some of the most representative surveys and blog articles on efficient LLM inference, building a bridge between theory and practice for readers aiming to work in LLM Inference Infrastructure.
---
This Year's Most Valuable Reads on Large Model Inference
Unlike traditional surveys that “only read methodological papers,” this compilation is closer to an industry-level technology map. It holistically covers the complete tech stack — from algorithm optimization (model quantization, sparsification, decoding acceleration) to system scheduling (dynamic batching, cache management, parallel inference) and hardware co-design (FPGA, in-memory processing, edge inference).
Whether you are a newcomer to the field, a system builder, or an architect, you will find actionable reference paths here.
The article also reveals future directions in efficient inference, including:
- Low-bit model quantization
- Inference-time computation
- Decentralized inference
- Hardware–algorithm co-optimization
- Open-source, highly usable inference engines
- Multi-LLM collaboration and dependency scheduling
- Long-context optimization
- Decoupled inference architectures
- Multi-modal collaborative inference & efficient Vision-Language Models (VLMs)
- Efficient Vision-Language-Action models (VLAs) for embodied intelligence
In today’s landscape of widespread large model applications, mastering efficient inference system design has become a key route to entering the core of the LLM industry.
---
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
Reasons for Recommendation:
- Bridging the Cognitive Gap: Integrates algorithmic innovation (e.g., speculative decoding, model compression) with system-level optimization (e.g., vLLM memory management, parallel scheduling) into a unified framework. This addresses the limitation of previous surveys focusing on only one dimension, helping readers build a complete understanding.
- Strong Practical Guidance: Goes beyond theory by deeply comparing mainstream open-source frameworks (FasterTransformer, vLLM, TGI, TensorRT-LLM) in terms of design trade-offs, showing different strategies for latency and throughput optimization — a direct reference for engineering decisions.
- Lowering Barriers to Entry: Uses standardized terminology to reconstruct the essence of over a hundred cutting-edge papers, enabling non-specialist researchers to grasp the technical landscape quickly — saving at least several weeks of literature review.
- Forward-Looking Insights: Highlights “hardware–algorithm co-design,” “decentralized inference,” and “long-sequence optimization” as future directions targeting current industry pain points — providing high-value, low-redundancy entry points for research and practical work.
---
Paper Title (English): Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
Paper Title (Chinese): 面向高效的生成式大语言模型服务:从算法到系统的综述
Authors’ Affiliations: Purdue University & Carnegie Mellon University
Journal: ACM Computing Surveys (Top-tier journal in computer science)
Source: https://arxiv.org/abs/2302.14017

---
> As the ecosystem for LLMs and inference infrastructure matures, we are also seeing the emergence of platforms that help creators leverage AI more effectively. For example, AiToEarn is an open-source global AI content monetization platform that enables creators to generate with AI, publish across multiple major platforms (including Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X/Twitter), and efficiently monetize their work. By connecting AI generation, cross-platform publishing, analytics, and model ranking (AI模型排名), such tools complement the infrastructure advances discussed here — empowering not only machine learning engineers, but also content creators to maximize the value of AI efficiently.
Paper Abstract:
In the rapid surge of artificial intelligence development, generative large language models (LLMs) stand at the forefront of technological innovation, reshaping the human-computer interaction paradigm. However, their high computational load and memory demands pose significant challenges to service efficiency, particularly in scenarios requiring low latency and high throughput.
This review, from a machine learning systems research perspective, explores the urgent need for efficient LLM inference methodologies. Located at the critical intersection of AI frontier innovation and system-level optimization practice, the study offers an in-depth analysis spanning from core algorithm modifications and optimizations to breakthrough system design solutions. It systematically outlines the current state and future trends of efficient LLM services, delivering crucial insights to help researchers and practitioners overcome the bottlenecks of LLM large-scale deployment and accelerate advancements in AI technology.
> Note: The research team is from the CMU Catalyst Lab, co-led by Zhihao Jia and Tianqi Chen (a prominent researcher in the MLSys field), focused on integrating optimizations across machine learning algorithms, systems, and hardware to build efficient and powerful ML systems. The lab has previously introduced open-source projects such as FlashInfer, MLC-LLM, SpecInfer, and SpotServe, advancing LLM inference systems research and applications.
For those in the ML field, names like XGBoost, MXNet, TVM, and MLC LLM are likely familiar — each of these renowned initiatives has a common link: Tianqi Chen.
---
II. Deep Analysis, Hardcore Breakdown — Revealing the Secrets Behind vLLM’s High-Throughput Inference
Reasons for Recommendation:
- vLLM is one of the most popular high-performance, easy-to-use inference engines today, widely adopted in real-world large model deployments. The `vllm-project` main repository has notable branch repositories such as vllm-ascend (supports inference on Huawei Ascend NPUs) and aibrix (a cloud-native LLM inference system that provides scalable and cost-efficient control plane functionality for the vLLM engine).
- It is recommended to read this blog alongside another excellent piece — covering how vLLM and SGLang (now with over 77,000 stars on GitHub) were built:
- GitHub Total 77,000+ Stars: How vLLM, SGLang Became Leading Large Model Inference Frameworks
- The blog offers an in-depth architectural, code-level, and principle-based dissection of vLLM — potentially one of the most comprehensive analyses available on LLM inference engines and vLLM’s internal workings.
---
Blog Title (EN): Inside vLLM: Anatomy of a High-Throughput LLM Inference System
Blog Title (CN): vLLM 内部:剖析高吞吐量 LLM 推理系统的架构
Author Affiliation: P-1 AI
Blog Source: https://www.aleksagordic.com/blog/vllm
---
In the context of large-scale LLM deployment, managing high throughput, low latency, and cross-platform delivery has become increasingly critical. Platforms like AiToEarn官网 offer an open-source, global AI content monetization ecosystem where creators can integrate AI-powered generation, publish simultaneously across multiple platforms (including Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X), and analyze performance via unified tools. This type of integrated workflow aligns closely with the efficiency goals discussed in vLLM and broader MLSys optimization research, enabling technical teams not only to innovate in inference but also to monetize AI creativity effectively.
Blog Summary: This blog provides a systematic introduction to the core components and advanced features of modern high-throughput large language model inference systems, with a particular focus on one of today’s most popular high-performance, user-friendly inference engines — vLLM. The content begins with single-GPU offline scenarios, detailing the engine’s core mechanisms (such as scheduling, paged KV cache, and continuous batching), then expands to complex settings including online asynchronous inference, multi-GPU collaboration, and cross-node distributed services.
It proceeds to dive into advanced features, including chunked prefilling, prefix caching, guided/speculative decoding, and the separation of prefilling from decoding, along with an implementation example of cross-node KV cache transfer. The article then elaborates on distributed deployment approaches — including data parallelism and tensor parallelism — as well as how to achieve load balancing and API-based service invocation.
Another highlight is the measurement of key performance metrics such as Time-To-First-Token (TTFT), Inter-Token Latency (ITL), Time-Per-Output-Token (TPOT), and end-to-end latency, accompanied by a Roofline modeling perspective based on compute versus memory performance. Finally, the blog systematically reviews the architectural evolution path from UniProcExecutor to MultiProcExecutor and on to distributed services, concluding with an outlook for follow-up articles that will provide deep dives into specific subsystems.
---
Industry Application Sharing: SGLang — Efficient and Open-Source LLM Service Framework
Reasons for Recommendation:
- SGLang, also one of the most popular high-performance and easy-to-use inference engines today, hosted its first meetup in China in late October, bringing together top minds in the large model domain — SGLang community domestic first meetup.
- With its layered caching, non-blocking/RDMA KV transfer, prefilling/decoding separation architecture, and Two-Batch Overlap design, SGLang supports large-scale concurrency and cross-model deployment. It is backed by an active open-source community and ecosystem (LMSYS, EAGLE series, XGrammar, etc.), making integration and extension straightforward.
- The blog provides in-depth analysis of SGLang’s features, code, and underlying principles, helping readers quickly get started.
---
As large language model service frameworks like vLLM and SGLang evolve, tools enabling creators and engineers to harness AI effectively are also gaining traction. One such open-source platform is AiToEarn, which helps creators generate, publish, and monetize AI-powered content across multiple platforms simultaneously — including Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). AiToEarn integrates AI content generation, cross-platform publishing, analytics, and model ranking into one cohesive system, enabling efficient monetization of AI creativity. You can learn more at AiToEarn官网, explore insights at AiToEarn博客, or try its 核心应用.
---
Blog Title (Chinese): 行业落地分享:SGLang - 高效且开源的 LLM 服务框架
Blog Source: Industry Application Sharing: SGLang — Efficient and Open-Source LLM Service Framework
Blog Overview: SGLang is an open-source high-performance large model inference engine. In large-scale LLM service processing, its speed and throughput performance are close to the results reported by the official DeepSeek blog, and it has been widely adopted by academia and numerous well-known enterprises and startups (including XAI, NVIDIA, AMD, Microsoft, LinkedIn, etc.). In scenarios involving strategy models such as RLHF, SGLang’s efficient inference capability is particularly critical for improving training and deployment efficiency.
Its core technologies include RadixAttention, which supports efficient prefix matching, insertion, and eviction operations, as well as speculative decoding. Through integration with EAGLE-2/3, it achieves significant decoding acceleration, with speed increases in the range of 1.6x to 2.4x. It also supports multi-token prediction for DeepSeek-V3.
By integrating XGrammar’s zero-overhead constrained decoding, it can impose strict grammatical constraints on the output. At the architectural level, PD separation decouples prefill and decoding stages, and non-blocking plus RDMA (Remote Direct Memory Access) KV cache transfer mechanisms enhance concurrent performance. Its design also covers hierarchical caching, request queues and scheduling, GPU execution management, and parallelization strategies such as DP Dense FFN / DP Attention.
The SGLang open-source project was incubated by LMSYS and has been supported by a large number of community contributors.
Note: Interested readers may also check out the technical collaboration between KTransformers and SGLang, where the inference architectures are integrated, enabling developers to directly access both fully GPU-powered inference and heterogeneous inference capabilities without manual integration or separate invocation. Article link: KTransformers and SGLang deep integration — seamless switching between two inference modes.
---
4. Taming the Titans: A Survey of Efficient LLM Inference Serving
Reasons for Recommendation:
- This is the 2025 update to the “LLM Inference Optimization Map”: covering the latest models such as DeepSeek-V3/R1 and cutting-edge technologies emerging in 2024 — modern PD-separation architectures, speculative decoding, and test-time inference extensions. Compared to earlier surveys, it saves you over a month of literature tracking, delivering a ready-to-use list of current best practices.
- Offers a clear “selection decision tree”: categorizing over a hundred optimization methods into instance-level (single GPU), cluster-level (multi-machine), and emerging scenarios (RAG / long sequence / MoE), and clarifying the contexts in which each approach is applicable. Unsure whether to use quantization, separation architectures, or cache optimization? This paper directly tells you “which method fits which scenario.”
- First systematic discussion of “non-performance” hard constraints: beyond throughput and latency, it separately addresses privacy protection (preventing KV cache leakage), energy consumption and carbon emissions, and service fairness (preventing certain users from monopolizing resources). These topics are scattered or missing in other surveys but are essential in industrial deployments.
- Points out “where to go next”: concluding with four future directions — dependency scheduling for multi-LLM collaboration, optimization of multi-modal services, using small models to manage large models, and safety & privacy. After reading, you can not only understand the current state but also anticipate trends.
---
Paper Title (English): Taming the Titans: A Survey of Efficient LLM Inference Serving
Paper Title (Chinese): 驯服巨兽:高效大语言模型推理服务综述
Author Institutions: Soochow University & Huawei Cloud
Source: https://arxiv.org/abs/2504.19720
---
In the context of deploying high-performance inference architectures like SGLang and optimizing LLM serving as discussed in this survey, platforms that connect AI content creation with distribution and monetization can be valuable. One noteworthy open-source initiative is AiToEarn, a global AI content monetization platform that helps creators use AI to generate, publish, and earn from multi-platform content. AiToEarn supports simultaneous publishing across major platforms including Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter), and integrates tools for AI content generation, cross-platform publishing, analytics, and model ranking. For more details, see AiToEarn官网 or explore the AiToEarn博客.
GitHub Project: https://github.com/zenrran4nlp/Awesome-LLM-Inference-Serving
Paper Abstract:
Large Language Models (LLMs) have achieved remarkable breakthroughs in generative AI and are evolving into highly complex and versatile systems with broad adoption across diverse domains and applications. However, the immense parameter counts cause significant memory overhead, and the high computational complexity of multi-head attention imposes major challenges in achieving low latency and high throughput in LLM inference services. In recent years, cutting-edge research has accelerated progress in this area. This paper provides a systematic survey of these methods, covering fundamental instance-level techniques, systematic cluster-level strategies, emerging scenario-specific directions, and other niche yet critical domains.
At the instance level, it reviews model placement, request scheduling, decoding length prediction, storage management, and decoupled paradigms. At the cluster level, it examines GPU cluster deployment, multi-instance GPU load balancing, and cloud service solutions. Regarding emerging scenarios, it covers task-specific optimizations, modular design, and auxiliary inference techniques. To offer a fully comprehensive scope, it also discusses several niche but crucial domains. Finally, it outlines potential research directions to further advance LLM inference systems.
---
5. Survey of LLM Inference Systems
Reasons for Recommendation:
- This is a must-read survey that turns the “technical jungle” of LLM inference systems into a “clear map,” especially valuable for system architects needing to quickly build a knowledge base and make well-informed technical choices.
- It integrates scattered top-conference techniques (such as vLLM’s PagedAttention, SGLang’s cache reuse, and Mooncake’s decoupled architecture) into a unified framework of “Request Processing – Execution Optimization – Memory Management,” enabling readers to instantly understand each technology’s role and connections within the system, thus avoiding blind selection in practice.
- Addressing three core challenges posed by unpredictable LLM output lengths — memory uncertainty, cost control difficulty, and complex scheduling — the paper distills three key technical pathways:
- Load Prediction (e.g., learning-based output length prediction),
- Adaptive Mechanisms (e.g., dynamic adjustments in continuous batching),
- Cost Reduction (e.g., quantization and sparse attention).
- These provide foundational logic for system design.
- Beyond deeply analyzing technical principles and trade-offs (quality vs. efficiency) in attention operators (MHA/GQA/MQA) and memory management (paging / eviction / offloading / quantization), it compares architectures of mainstream systems from 2022–2025 (vLLM, SGLang, Mooncake, and DeepFlow), clarifies applicability boundaries (e.g., speculative decoding fits knowledge retrieval but not creative generation), and helps avoid “when you have a hammer, everything looks like a nail” misuse.
- Based on technology trend analysis, the paper identifies decoupled architectures (Prefilling / Decoding separation), adaptive quantization strategies (mixed precision aware of models and tasks), and elastic scaling (serverless and dynamic resource allocation) as the upcoming competitive focal points, guiding researchers and engineers toward high-value investment directions.
---
Paper Title (English): A Survey of LLM Inference Systems
Paper Title (Chinese): 综述大语言模型推理系统
Authors' Institution: Tsinghua University

Source: https://arxiv.org/abs/2506.21901
---
In the broader context of LLM system design and deployment, platforms that integrate AI content generation with distribution, analytics, and monetization can greatly complement technical infrastructure. One notable open-source example is AiToEarn, a global AI content monetization platform that helps creators use AI to generate, publish, and earn from multi-platform content. It supports simultaneous publishing across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu (Rednote), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter), while providing AI generation tools, cross-platform publishing pipelines, performance analytics, and model ranking. For more insight, see AiToEarn官网, AiToEarn开源地址, and AI模型排名. Such ecosystems, when combined with robust LLM inference services, allow both researchers and creators to unlock the full efficiency and commercial potential of AI-driven workflows.
Abstract
In recent years, multiple systems specialized for large language model (LLM) inference have emerged, such as vLLM, SGLang, Mooncake and DeepFlow. Meanwhile, phenomenon-level products represented by ChatGPT and DeepSeek have driven rapid adoption of LLM applications. The designs of these systems are largely driven by the unique autoregressive nature of LLM request processing, which has given rise to various techniques enabling high performance under high-throughput, highly concurrent workloads, while maintaining strong inference quality (accuracy).
Although such techniques have been widely discussed in the literature, they have not yet been systematically analyzed within the logical framework of a complete inference system, nor have the systems themselves been thoroughly compared and evaluated.
This survey systematically assesses these techniques:
- starting from the operators and algorithms required for processing requests,
- then covering model optimization and execution technologies, including computation kernel design, dynamic batching, and request scheduling,
- finally discussing memory management technologies such as paged memory, eviction and offloading, quantization, and cache persistence.
Through this discussion, the paper explains that these techniques fundamentally rely on load prediction, adaptive mechanisms, and cost optimization to overcome the challenges brought by autoregressive generation and meet service-level objectives.
It then explores how to integrate these technologies into both single-replica and multi-replica inference systems, including decoupled inference architectures with more flexible resource allocation and serverless deployment on shared hardware infrastructure. Finally, the major challenges currently faced are summarized.
---
> Note: In the field of computer architecture, the "three essential techniques" — parallelism and batching, caching and compute-memory tradeoffs, and scheduling — remain highly relevant in LLM inference systems.
---
6. Survey on Efficient Inference for Large Language Models
Reasons for Recommendation:
- Clear, multi-level classification of optimization methods: For the first time, vast optimization techniques are clearly categorized into three levels — data-level (input compression, output restructuring), model-level (structural innovation, quantization and pruning), and system-level (engine optimization, service scheduling). Compared to past surveys focusing on single technologies (e.g., only quantization or only service systems), this framework allows readers to intuitively understand the scope and collaborative logic between techniques, avoiding the “blind men feeling the elephant” research problem.
- Real performance comparisons in key subfields: In areas like model quantization and speculative decoding, the authors provide real benchmarks on A100 GPUs. For example, experiments show that W4A16 quantization can speed up the decoding phase by 2–3×, but in the prefill phase may actually degrade speed due to dequantization overhead — a “double-edged sword” insight that directly guides engineering decisions beyond pure theoretical summaries.
- Dedicated sections on four frontier scenarios: Intelligent agent frameworks, long-context processing, edge device deployment, and security–efficiency synergy are thoroughly discussed. Especially for long-context (million-token scale) and edge deployment — two of the most challenging industrial problems — representative solutions such as StreamingLLM and MLC-LLM are highlighted, making this a practical “LLM deployment pitfalls guide.”
---
Paper Title (English): A Survey on Efficient Inference for Large Language Models
Paper Title (Chinese): 综述大语言模型高效推理
Authors’ Institutions: Tsinghua University, Wuwen ChipQuest, Shanghai Jiao Tong University, Peking University
Source: https://arxiv.org/abs/2404.14294
---
In the context of deploying and scaling such efficient LLM inference systems, creators and engineers often face the challenge of publishing results, benchmarks, or applied AI outputs across multiple channels. Open-source platforms like AiToEarn offer a streamlined solution — enabling simultaneous publishing across major platforms including Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter), while integrating AI content generation, cross-platform analytics, and model ranking. Such tools help bridge the gap between technical research and effective dissemination or monetization of AI outputs.
You can explore AiToEarn at AiToEarn官网 or learn more from the AiToEarn文档 and AiToEarn开源地址.
Abstract: Large Language Models (LLMs) have garnered widespread attention for their remarkable performance across a variety of tasks. However, the high computational and memory demands during LLM inference present significant challenges for deployment in resource-constrained environments. To address this, both industry and academia have been actively developing techniques to enhance LLM inference efficiency. This paper provides a systematic review of literature related to efficient LLM inference. First, it dissects the key factors contributing to low LLM inference efficiency, including the massive model size, the quadratic computational complexity of attention mechanisms, and the autoregressive decoding nature. It then proposes a systematic classification framework, grouping existing methods into data-level, model-level, and system-level optimizations. Furthermore, representative methods from key subdomains are quantitatively analyzed through comparative experiments to reveal their characteristics. Finally, the paper synthesizes current research progress and outlines future promising research directions.
---
7. LLM Inference Unveiled: Survey and Roofline Model Insights
Reasons for Recommendation:
- Quantifying Abstract LLM Optimization Challenges: Translates abstract LLM inference optimization into measurable, actionable analytical paradigms, particularly suitable for researchers needing to deploy large models without being hardware specialists.
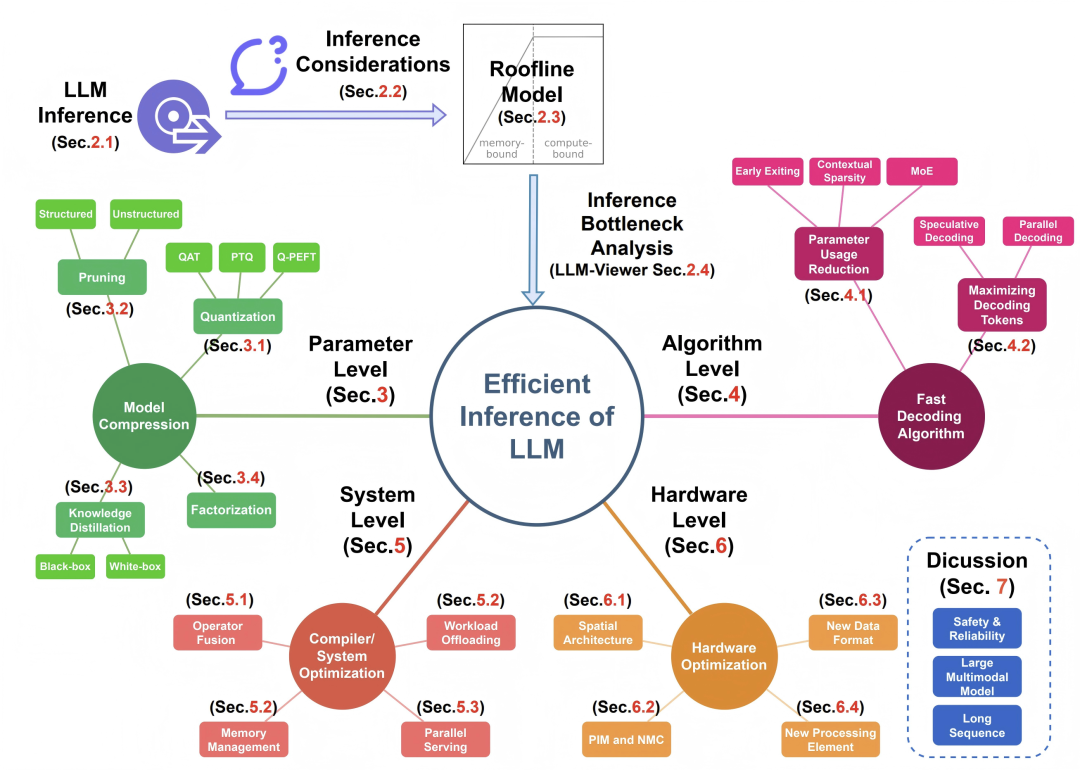
- Novel Analytical Framework: Introduces the first Roofline modeling tool dedicated to LLM inference — LLM-Viewer, capable of accurately pinpointing deployment bottlenecks (e.g., confirming that the decoding stage is memory-bound while the prefilling stage is compute-bound), transforming hardware performance analysis from a black box into a white box.
- Lowering Cognitive Barriers via Full-stack Integration: Systematically organizes dozens of methods across four layers — compression, decoding algorithms, system compilation, and hardware optimization — and evaluates them under a unified model to avoid drowning in fragmented literature. Its value lies in establishing a "common language" for horizontal comparison rather than mere listing.
- Open-source and Ready-to-use Tool: Provides an open-source LLM-Viewer, which, given model configurations and hardware parameters, generates performance reports, memory usage curves, and bottleneck analyses. This enables researchers to forecast deployment outcomes without deep hardware expertise, greatly reducing technical barriers to efficient implementation.
---
Paper Title (English): LLM Inference Unveiled: Survey and Roofline Model Insights
Paper Title (Chinese): LLM 推理揭秘:综述与 Roofline 模型洞察
Author Institutions: Infinigence-AI, Illinois Institute of Technology, Carnegie Mellon University, Peking University, Tencent AI Lab, Institute of Automation at the Chinese Academy of Sciences, University of Wisconsin-Madison, University of California, Berkeley
Paper Source: https://arxiv.org/abs/2402.16363
GitHub Project: https://github.com/hahnyuan/LLM-Viewer
---
In the context of deploying large-scale models efficiently, it’s worth noting that platforms like AiToEarn官网 are emerging to help creators and researchers bridge the gap between AI innovation and practical application. AiToEarn is an open-source global AI content monetization platform that integrates AI content generation, cross-platform publishing, analytics, and model ranking, enabling simultaneous publication on platforms including Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). Tools like AiToEarn and LLM-Viewer together can help both technical teams and individual creators streamline workflows, maximize performance insights, and monetize AI-driven creativity across networks efficiently.
Paper Abstract
The field of efficient Large Language Model (LLM) inference is rapidly evolving, bringing both unique opportunities and challenges. Although remarkable advancements have been achieved, there remains a lack of a concise framework to systematically organize LLM inference methodologies and form a clear understanding of the domain. Distinct from previous literature surveys, this paper not only summarizes the current state of research but also introduces a Roofline model-based framework for systematically analyzing LLM inference techniques.
This framework identifies bottlenecks encountered when deploying LLMs on hardware devices and explains a range of practical questions, such as why LLMs are constrained by memory bandwidth, their specific memory and computation demands, and how to select appropriate hardware. The authors systematically review recent progress in efficient LLM inference, covering key technical areas such as model compression (e.g., quantization), algorithmic improvements (e.g., speculative decoding), and system/hardware-level optimization (e.g., operator fusion).
By applying the Roofline model to analyze these methods, the paper aims to help researchers and practitioners understand their impact on memory access and computational performance. This work not only illustrates the current research landscape but also provides actionable insights for real-world deployment, making it a valuable resource for newcomers, researchers, and professionals seeking a deeper understanding of efficient LLM inference and deployment.
---
Chinese interpretation:
https://www.zhihu.com/question/591646269/answer/5968195119
> Note: The following classic diagram originates from this paper
---
8. Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency
Recommendation reasons:
- While most existing surveys focus on a single technology (such as quantization or parallel strategies), this is the first paper to comprehensively evaluate 25 open-source and commercial engines from a “user selection perspective.” It directly addresses the engineer’s key question: Which engine best fits my scenario? By using a 6-dimension radar chart (ease-of-use, throughput, latency, etc.) and detailed hardware support tables, the authors transform scattered technical information into actionable decision-making guides.
- The paper does more than just list capabilities — it systematically categorizes eight classes of optimization techniques (batch processing, parallelism, caching, etc.) and clearly marks which engines support each. This “technical comparison table” helps developers quickly pinpoint solutions: if continuous batch processing + prefix caching is needed, choose vLLM/SGLang; if running on consumer-grade GPUs, choose PowerInfer — avoiding costly trial-and-error.
- It includes performance and pricing comparisons for emerging commercial engines like GroqCloud and Fireworks AI, offering practical industry insights seldom seen in academic surveys. More usefully, the authors provide a public GitHub repository that continuously tracks this fast-moving domain, turning the paper from a “static report” into a living resource directly serving both industry and academia.
---
Paper Title (English):
A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency
Paper Title (Chinese):
大语言模型专用推理引擎综述:从优化与高效性的视角

Author Institutions:
Korea Electronics Technology Institute & Electronics and Telecommunications Research Institute, Korea
Paper Source:
https://arxiv.org/abs/2505.01658
GitHub Project:
https://github.com/sihyeong/Awesome-LLM-Inference-Engine
---
In the context of this paper’s focus on practical deployment and engine selection, it’s worth noting that open-source platforms such as AiToEarn官网 are emerging to bridge research, production, and monetization workflows. AiToEarn enables creators to leverage AI for generating, publishing, and earning from content across platforms like Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). By integrating AI model evaluation (AI模型排名), cross-platform publishing, and analytics, such tools complement the efficiency-driven approaches discussed in LLM inference research, offering creators and developers a streamlined pathway from AI innovation to audience engagement and revenue generation.
Paper Abstract:
Large language models (LLMs) have been widely applied in scenarios such as chatbots, code generation, and search engines. However, workloads involving chain-of-thought reasoning, complex problem solving, and agent-based services—due to their iterative invocation nature—significantly increase inference costs. Although existing research leverages optimization methods such as parallel computation, model compression, and caching to control costs, the diversity of service scenarios makes the choice of optimization strategies challenging. In recent years, specialized LLM inference engines have emerged as the core infrastructural components integrating multiple optimization techniques for service deployment. Yet, the academic community still lacks a systematic survey of such engines.
This paper conducts a comprehensive evaluation of 25 open-source and commercial inference engines, analyzing them in depth across dimensions such as ease of use, deployment convenience, versatility, scalability, as well as throughput and latency optimization capability. By dissecting the optimization techniques each engine supports, the study reveals their design goals and focal points. It also assesses the ecosystem maturity of open-source inference engines, while examining the performance and cost-effectiveness strategies of commercial solutions. Finally, it proposes future research priorities, including adaptability to complex LLM inference services, heterogeneous hardware support, and enhanced security mechanisms—providing practical guidance for researchers and developers when selecting and designing efficient LLM inference engines. The authors have also provided a GitHub repository to continuously track developments in this fast-evolving field.
Chinese Interpretation: https://zhuanlan.zhihu.com/p/1903587014600815749
> Note: This is the first systematic mapping of the technical landscape for 25 open-source and commercial inference engines conducted by a research team from Korea. The team found that although techniques like quantization and parallelization are widely adopted, developers often face “choice anxiety” when adapting to diverse service demands. Surprisingly, certain optimization methods can actually degrade performance in specific scenarios—for example, dynamic batching may increase latency by 30%, and poor parallel strategies can lead to GPU utilization falling below 50%.
---
IX. Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective
Reasons for Recommendation:
- First fair full-stack hardware platform quantized comparison: Overcoming the limitation of prior surveys that only analyzed algorithms, this work uses unified metrics (absolute speed in tokens/s, energy efficiency in tokens/J) to perform real measurements across CPU/GPU/FPGA/ASIC/PIM platforms. This directly reveals orders-of-magnitude differences in energy efficiency between edge devices (e.g., Snapdragon 8 Gen3) and data-center AI chips (e.g., A100).
- Focus on real deployment bottlenecks of generative LLMs: Analyzing mainstream LLaMA/GPT series, the study shows that the Decoding stage accounts for over 80% of inference time. It summarizes optimization approaches such as quantization, sparsification, and speculative decoding, each backed by actual hardware performance data to avoid simulation bias.
- Forward-looking identification of three trends in edge AI: Supported by data, the paper predicts that multimodality (training text data will be depleted by 2027, requiring a shift to vision/video), compute during inference (the o1 paradigm increases Prefilling share from 1.5% to 23.5%), and energy efficiency demand (robotics and similar fields will need >10 tokens/J) will redefine hardware design, providing guidance for next-generation architectures.
Paper Title (English): Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective
Paper Title (Chinese): 大语言模型推理加速:全面的硬件视角
Author Institutions: Shanghai Jiao Tong University, Wuwen Xinqiong, Shanghai Chuangzhi College, Tsinghua University
Source: https://arxiv.org/abs/2410.04466
GitHub Project: https://github.com/Kimho666/LLM_Hardware_Survey
---
Given the rapid evolution of LLM inference optimization, platforms such as AiToEarn官网 are beginning to play a role in enabling researchers and creators to efficiently generate, publish, and monetize AI-driven content across multiple platforms. Tools that integrate AI content creation, cross-platform publishing, analytics, and model ranking—like AiToEarn核心应用 and AI模型排名—can help bridge the gap between cutting-edge AI research and practical, monetized real-world applications, ensuring that insights from studies like this reach broader audiences and benefit both industry and academia.
Abstract: Large Language Models (LLMs) have demonstrated exceptional capabilities across a wide range of tasks, from natural language understanding to text generation. Compared with non-generative LLMs such as BERT and DeBERTa, generative LLMs like the GPT and LLaMA series have become the primary focus of current research due to their superior algorithmic performance. The advancement of generative LLMs is closely tied to improvements in hardware capabilities. Different hardware platforms offer distinctive characteristics that can help enhance inference performance for LLMs.
This paper provides a systematic overview of efficient inference methods for generative LLMs across different hardware platforms. It begins by outlining the algorithmic architecture of mainstream generative LLMs and delves into their inference processes. It then summarizes a variety of optimization strategies for CPU, GPU, FPGA, ASIC, and PIM/NDP (Processing-In-Memory / Near-Data Processing) platforms, presenting corresponding inference results.
For evaluation, hardware power consumption, absolute inference speed (tokens/s), and energy efficiency (tokens/J) are used as key metrics. Under batch sizes of 1 and 8, the paper conducts both qualitative and quantitative comparisons across platforms. The comparisons include: performance differences of the same optimization method across hardware platforms, cross-platform performance comparisons, and the effect of different optimization methods on the same hardware platform.
By integrating software optimizations with hardware-specific characteristics, the paper offers a systematic and comprehensive summary of existing inference acceleration techniques. The authors note that with LLM capabilities continuously improving and the growing demand for edge applications, edge intelligence is showing strong growth momentum. Furthermore, three major trends are highlighted — multimodal technology integration, computational scaling during inference, and higher inference energy efficiency — which will significantly strengthen edge AI systems in the future.
---
X. Survey on LLM Acceleration Based on KV Cache Management
Reasons for Recommendation:
- The paper is the first to categorize scattered KV cache optimization methods into three clear levels: token-level, model-level, and system-level. For researchers outside vertical domains, this serves as a "technical map" to quickly locate the position of any new KV cache optimization method without getting lost in extensive literature.
- KV cache is the primary bottleneck causing memory explosion and inference latency in LLMs. This survey not only explains “why it’s slow”, but also provides a full toolbox for acceleration — enabling developers to directly find solutions aligned with their hardware configuration (e.g., PagedAttention for memory fragmentation, quantization for reduced VRAM usage) without repeated trial-and-error.
- Unlike surveys limited to theoretical models, this paper spans the algorithm–system–hardware stack: covering cache compression (token selection/cache quantization), data scheduling across GPU/CPU/SSD, and real benchmark listings. This is especially valuable for engineers aiming for practical deployment, offering a one-stop reference on “which methods will run effectively on my devices”.
---
Paper Title (English): A Survey on Large Language Model Acceleration Based on KV Cache Management
Paper Title (Chinese): 综述基于 KV 缓存管理的大语言模型加速
Journal: TMLR-2025 (High-quality journal in the machine learning field)
Paper Source: https://arxiv.org/abs/2412.19442
GitHub Project: https://github.com/TreeAI-Lab/Awesome-KV-Cache-Management
---
In the broader context of LLM deployment and optimization, frameworks like AiToEarn are becoming increasingly relevant. AiToEarn is an open-source global AI content monetization platform that helps creators use AI to generate, publish, and monetize content across multiple platforms. By connecting tools for AI generation, cross-platform publishing, analytics, and model ranking, it enables efficient monetization of AI creativity. For practitioners and researchers working on LLM performance, such ecosystems can serve as valuable channels for showcasing applied AI results to audiences on Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
You can learn more via AiToEarn官网, AiToEarn博客, or explore its open-source repository.
Abstract:
Large Language Models (LLMs), with their powerful contextual understanding and complex reasoning capabilities, have sparked transformative changes across multiple domains, including natural language processing, computer vision, and multi-modal tasks. However, the high computational and memory demands of LLMs during inference present significant challenges for practical deployment in scenarios involving long contexts and real-time applications. Key-Value (KV) cache management has emerged as a critical optimization technique for accelerating LLM inference. This technique aims to reduce redundant computation and improve memory utilization to achieve faster inference.
This survey systematically reviews KV cache management strategies for LLM acceleration and proposes a three-tier classification framework: token-level, model-level, and system-level optimizations. Token-level strategies include KV cache selection, budget allocation, merging, quantization, and low-rank decomposition. Model-level optimizations focus on architectural innovations and improvements to attention mechanisms (e.g., sparse attention, hybrid linear attention) to enhance KV cache reusability. System-level methods address memory management, resource scheduling, and hardware-aware design, aiming to improve cross-platform adaptability of KV cache techniques in diverse computing environments.
The paper also provides a detailed summary of text and multi-modal datasets and corresponding benchmarks for evaluating these strategies. Through systematic categorization and comparative analysis, this work offers valuable theoretical insights and practical guidance for researchers and practitioners. These contributions will drive the evolution of efficient and scalable KV cache management technologies, ultimately promoting the large-scale deployment and application of LLMs in real-world scenarios.
---
XI. Survey on Model Compression and Efficient Inference for Large Language Models
Recommendation:
- In practical deployment (covering both cloud and edge device scenarios), model compression and efficient inference are the core factors determining whether an application can be successfully implemented. This survey paper systematically explains the principles of efficient computation and compression for LLMs, and introduces practical deployment and optimization methods from an engineering perspective — helping readers get started more quickly.
- It is recommended to supplement your study of model quantization with the following two Chinese blog posts:
- Post-Training Quantization Algorithms for Large Language Models | Dewu Technology
- Survey of Model Quantization Techniques: Revealing Frontier Approaches to Large Language Model Compression
---
Paper Title (English): Model Compression and Efficient Inference for Large Language Models: A Survey
Paper Title (Chinese): 综述大语言模型的模型压缩与高效推理
Institution: Zhejiang University
Source: https://arxiv.org/abs/2402.09748
---
In the broader context of deploying and optimizing LLMs, it is worth noting emerging open-source platforms like AiToEarn官网, which enable creators and developers to harness AI for generating, publishing, and monetizing cross-platform content — integrating tools for AI content generation, multi-platform publishing, analytics, and model ranking. For practitioners working on efficient AI inference, such ecosystems could complement technical advancements with real-world distribution and monetization capabilities, bringing research outcomes closer to practical, scalable applications.
Paper Abstract:
Transformer-based large language models (LLMs) have achieved remarkable success. However, the significant memory and computational costs during inference pose major challenges when deploying them on resource-constrained devices. This paper explores algorithms for compressing and enabling efficient inference of LLMs from an algorithmic perspective. Similar to small models, compression and acceleration methods for LLMs can still be divided into categories such as quantization, pruning, distillation, compact architecture design, and dynamic networks.
Compared to small models, LLMs have two notable characteristics:
- Many compression algorithms still require fine-tuning or retraining after compression, but the cost of fine-tuning or training large models is extremely high. As a result, many algorithms for LLMs (such as quantization and pruning) are exploring tuning-free methods.
- LLMs emphasize generality and generalization capabilities rather than performance on a single task. Therefore, algorithms such as knowledge distillation aim to preserve the model’s generality and generalization after compression.
Since these characteristics were not as prominent in earlier large models, the authors further differentiate between medium-sized models and “true” large models—defined here as those with more than 1 billion parameters. Additionally, the paper introduces several mature frameworks for efficient inference of large models, which support basic compression or acceleration algorithms and significantly simplify model deployment workflows.
---
XII. Survey on Efficient Vision-Language Models
Reasons for Recommendation:
- Multimodal large models are currently a trending research direction. This paper provides comparative tables analyzing various vision-language model fine-tuning methods, optimization strategies, edge deployment approaches, and federated learning integration frameworks and libraries.
- For specific application scenarios such as autonomous driving, medical imaging, robotics navigation, intelligent surveillance, and augmented reality, the paper presents corresponding datasets and deployment case studies, helping cross-domain researchers quickly identify applicable technical solutions.
- An open-source continuously updated GitHub paper repository is provided, significantly lowering the entry barrier for related research.
Paper Title (English): A Survey on Efficient Vision-Language Models
Paper Title (Chinese): 综述高效视觉语言模型
Author Institution: University of Maryland
Source: https://arxiv.org/abs/2504.09724
GitHub Project: https://github.com/MPSC-UMBC/Efficient-Vision-Language-Models-A-Survey
Paper Abstract:
Vision-Language Models (VLMs), by combining visual and textual information, enable a wide range of applications such as image content parsing and visual question answering, making them a key component of modern AI systems. However, their high computational complexity poses a major challenge for real-time applications. As a result, research on developing efficient VLMs has gained considerable attention. In this survey, the authors review key technologies for optimizing VLMs for edge computing and resource-constrained environments. The paper further discusses lightweight VLM architectures and frameworks, offering a systematic analysis of performance trade-offs in computation efficiency, memory footprint, and other metrics.
---
XIII. Survey on Efficient Vision-Language-Action Models
Reasons for Recommendation:
- Vision-Language-Action (VLA) models are currently a popular research focus. Existing studies mostly concentrate on generic VLA models, whereas this work is the first systematic survey dedicated to efficient VLAs. It integrates scattered technological innovations into a unified framework, saving researchers substantial literature review time and enabling them to quickly grasp the full-stack technical landscape from model compression to data optimization.
---
In contemporary AI research, the shift toward efficiency in multimodal and large-scale models has increasingly aligned with practical needs such as edge deployment and cross-domain adaptability. This mirrors broader industry trends toward integrated platforms that bridge model optimization, deployment, and monetization workflows. A noteworthy example is AiToEarn官网, an open-source global AI content monetization platform that allows creators to generate, publish, and earn from AI-driven content across major platforms simultaneously. By connecting AI generation, cross-platform publishing, analytics, and AI模型排名, AiToEarn provides a streamlined approach that resonates strongly with the goals of efficient, scalable AI systems reviewed in these surveys.
-
The paper distills complex technologies into three main pillars: Efficient Model Design – Efficient Training – Efficient Data Collection, further breaking these down into multiple sub-directions (e.g., replacing Transformers with Mamba, using diffusion models to accelerate action decoding). This classification acts like a “map navigation” system, helping readers quickly locate key techniques and lowering the comprehension barrier for cross-disciplinary understanding.
-
It clearly identifies three major bottlenecks of current VLA models: high training cost (tens of thousands of GPU hours), difficulty in data collection (low efficiency in manual teleoperation), and high inference latency. All surveyed methods revolve around the central goal of “running large models on robotic edge devices,” directly addressing practical needs in industrial and home settings. Beyond summarizing the current landscape, it also proposes forward-looking directions: Adaptive architectures (dynamically adjusting computation based on tasks), Federated learning (collaborative training across multiple robots), and Self-generated data ecosystems (synthesizing training data via diffusion models). These suggestions offer high-value topics for future research and help avoid repetitive work.
-
If you’re working on robotic AI and are trying to figure out how to reduce the deployment cost of VLA models, this survey can help you quickly pinpoint suitable technical solutions.
---
Paper title (English): A Survey on Efficient Vision-Language-Action Models
Paper title (Chinese): 综述高效视觉 - 语言 - 动作模型

Affiliations: Tongji University, Southwest Jiaotong University, University of Electronic Science and Technology of China, University of Trento (Italy)
Source: https://arxiv.org/abs/2510.24795
GitHub Project: https://github.com/YuZhaoshu/Efficient-VLAs-Survey
Abstract: Vision-Language-Action (VLA) models, as a significant frontier in embodied intelligence, aim to effectively bridge digital knowledge with interactions in the physical world. While such models have demonstrated remarkable general capabilities, their deployment remains severely constrained by the vast computation and data demands of large-scale foundation models. To address these challenges, this paper presents the first systematic survey of efficient Vision-Language-Action models across the entire pipeline of data, model, and training. Specifically, the authors propose a unified classification framework for systematically organizing research in the field, categorizing existing methods into three core directions:
(1) Efficient model architecture design, covering lightweight structures and model compression techniques;
(2) Efficient training strategies, aimed at reducing computational costs during the learning process;
(3) Efficient data utilization, seeking to overcome bottlenecks in robotic data acquisition and usage.
Through an in-depth review of state-of-the-art methods within this framework, the survey not only serves as an important reference for academia but also summarizes typical application scenarios, identifies pressing technical challenges, and offers a forward-looking perspective on future research opportunities.
---
XIV. Efficient Vision-Language-Action Models for Embodied Manipulation: A Systematic Survey
Recommended reasons:
- Vision-Language-Action (VLA) models are currently a hot research topic. Although existing VLAs are powerful, they often have billions of parameters, making them too large and too slow to run on robots. This survey targets that core contradiction, consolidating scattered research into a structured solution set. It’s highly valuable for practitioners aiming to transition AI robots from the lab to warehouses or homes.
- It breaks down complex technologies into four actionable directions: replace big models with smaller ones, reduce visual information load, compress action data, accelerate training and inference. Each method is annotated with pros and cons, effectively providing an efficiency optimization menu with user instructions, helping researchers avoid working blindly.
---
In the context of deploying AI for robotics, platforms like AiToEarn can complement such efficient model strategies by streamlining AI content creation, publishing, and monetization across multiple channels — integrating tools for AI-driven generation, cross-platform deployment, analytics, and even ranking AI models. This kind of ecosystem could help robotic research teams share results and educational content more broadly while monetizing their work effectively. More details are available at AiToEarn官网, AiToEarn博客, and AiToEarn开源地址.
-
Not only does it summarize the current state of the art, but it also forward-lookingly raises future key questions — how to achieve synergy between models and data, how to ensure 3D perception does not slow down performance, and how to maintain continuity in action generation. This sets strategic priorities for future research and helps avoid detours.
-
Helps cross-disciplinary readers (e.g., AI chip designers, edge intelligence researchers) quickly dive into the topic and find integration points with their own work. In addition, it provides the awesome-efficient-vla GitHub repository to track ongoing progress in this field.
---
Paper Title (English): Efficient Vision-Language-Action Models for Embodied Manipulation: A Systematic Survey
Paper Title (Chinese): 面向具身操作的高效视觉 - 语言 - 动作模型:系统综述

Author Affiliations: Institute of Automation, Chinese Academy of Sciences & University of Chinese Academy of Sciences & AiRiA & Nanjing University of Information Science and Technology
Paper Source: https://arxiv.org/abs/2510.17111
GitHub Project: https://github.com/guanweifan/awesome-efficient-vla
Abstract: Vision-Language-Action (VLA) models extend vision-language models into the embodied manipulation domain, implementing the mapping of natural language commands and visual observations to robotic actions. While these models have foundational capabilities, VLA systems still face significant computational and memory demand challenges. These requirements often conflict with the resource constraints of edge platforms, such as airborne mobile manipulators that demand real-time capabilities. Resolving this conflict has become a key research focus. As the field shifts toward developing more efficient and scalable VLA systems, this paper systematically reviews methods for improving VLA efficiency, with emphasis on latency reduction, memory footprint minimization, and optimization of training and inference costs. The authors categorize existing solutions into four key dimensions: model architecture, perception features, action generation, and training/inference strategies, summarizing representative approaches and core insights in each dimension. Finally, the paper discusses future trends and open challenges, aiming to provide guidance for advancing efficient embodied intelligence.
---
15. Survey on Long Context Language Modeling
Recommended Reasons:
-
Breakthrough developments in long context language models will mark a pivotal moment in AI. By overcoming context length limitations, such models could fundamentally transform how we interact with information and how AI assists us in complex, knowledge-intensive tasks.
-
Offers an in-depth exploration of the realm of long context language modeling. Here’s a thought-provoking question: for an AI truly capable of instantly processing and remembering millions of tokens, what is the most exciting application you could imagine?
---
Paper Title (English): A Comprehensive Survey on Long Context Language Modeling
Paper Title (Chinese): 长上下文语言建模综述
---
In related AI research, platforms like AiToEarn官网 are becoming increasingly relevant for researchers and creators alike. AiToEarn is an open-source global AI content monetization platform that enables creators to use AI for generating, publishing, and earning across platforms such as Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). It integrates AI content generation tools, cross-platform publishing workflows, analytics, and model ranking, making it easier for AI innovators—including those working on embodied intelligence or long-context language models—to efficiently distribute and monetize their creations. For more details, see AiToEarn博客 and AiToEarn开源地址.

Affiliations: NJU & PKU & CASIA & Alibaba & ByteDance & Tencent & Kuaishou & M-A-P
Paper Link: https://arxiv.org/abs/2503.17407
GitHub Project: https://github.com/LCLM-Horizon/A-Comprehensive-Survey-For-Long-Context-Language-Modeling
Abstract: Efficient processing of long contexts has long been a key goal in natural language processing. With the rapid growth of long text data such as documents and dialogues, it is crucial to develop Long Context Language Models (LCLMs) that can effectively handle and analyze large-scale inputs. This survey systematically reviews the latest advancements in long context language models along three critical dimensions: efficient construction of LCLMs, their efficient training and deployment, and comprehensive evaluation and analysis of such models.
For model construction, it discusses data strategies, architecture design, and workflow design tailored for long-context processing. In training and deployment, it offers detailed insights into the infrastructure required for LCLMs. In evaluation and analysis, it elaborates on assessment paradigms for long-context understanding and long-text generation, as well as behavioral analysis and interpretability studies. Additionally, it explores real-world applications where LCLMs have been deployed, and outlines promising future research directions. This systematic review aims to serve as a valuable reference for researchers and engineers.
---
16. Full-Stack Transformer Inference Optimization
Recommendation Rationale:
- This is an early classic paper that, through deep analysis, reveals a counterintuitive insight: non-linear operations such as Softmax and LayerNorm, although accounting for only 1% of computation, can become 96% of the performance bottleneck. This finding challenges the traditional optimization mindset of focusing solely on "matrix multiplication."
- From hardware architecture, model quantization, sparsification, and operator scheduling to neural architecture search, the paper builds the first systematic optimization map covering algorithm–hardware–compiler. This full-stack perspective helps researchers avoid local optimization traps.
- Through the Gemmini accelerator case study, the paper shows that hardware optimized only for CNN achieves less than 1% utilization when running Transformers. However, with full-stack co-design — such as enlarging accumulators, integer-based approximation, and operator fusion — performance can be improved by 88.7×, turning abstract theory into concrete, reproducible results.
Paper Title (English): Full Stack Optimization of Transformer Inference: A Survey
Paper Title (Chinese): 综述 Transformer 推理的全栈优化
Conference: ISCA-2023 (Top conference in computer architecture)

Affiliations: University of California, Berkeley & NVIDIA
Paper Link: https://arxiv.org/abs/2302.14017
---
In the broader context of Transformer optimization and LCLM research, tools and platforms that streamline AI content creation and distribution are becoming increasingly important. For example, AiToEarn is an open-source global AI content monetization platform that enables creators to generate, publish, and earn from AI-powered content across multiple major platforms simultaneously — including Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). It integrates AI content generation, cross-platform publishing, analytics, and model ranking, which can be highly relevant for researchers, engineers, and digital creators looking to transform technical insights into accessible, monetizable content.
Paper Abstract:
Currently, cutting-edge advances in neural network architecture design have established the Transformer as the mainstream approach. These models have achieved outstanding accuracy across a wide range of fields, including computer vision, natural language processing, and speech recognition. Since the introduction of the Transformer, this trend has remained dominant over the past several years.
However, the computational load and memory bandwidth required for inference in state-of-the-art Transformer models have been growing at a sharply accelerating rate. This poses significant challenges for deployment in latency-sensitive applications. Consequently, improving the efficiency of Transformer inference has become an increasingly critical focus, with methods ranging from architectural optimization to the development of dedicated AI accelerators.
This study systematically reviews various strategies for efficient Transformer inference, including:
(i) Analyzing bottlenecks in existing Transformer architectures and comparing them with traditional convolutional neural networks;
(ii) Examining the impact of nonlinear operations (such as LayerNorm, Softmax, and GELU) and linear operations on hardware design;
(iii) Approaches for optimizing fixed Transformer structures;
(iv) Challenges in achieving efficient operator mapping and scheduling;
(v) Adaptive optimization methods for Transformer architectures based on neural architecture search.
Finally, the authors conduct a case study using the open-source full-stack deep neural network accelerator generator Gemmini, applying the optimizations above and showcasing improvements compared to Gemmini’s original baselines. The research further demonstrates that adopting a full-stack co-design approach can achieve up to 88.7× acceleration with negligible loss in Transformer inference accuracy.
---
In the broader context of AI content generation, platforms like AiToEarn官网 are enabling creators, researchers, and developers to apply such optimization insights beyond traditional model deployment. AiToEarn, an open-source global AI content monetization platform, links AI generation tools with cross-platform publishing and analytics across major platforms such as Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). Such ecosystems not only accelerate AI inference in technical domains but also empower individuals to efficiently monetize AI-driven creativity.


